之前用group by分组后一直困惑怎么把分组后的数据拿到,因为分组后同一组的只有一条数据,最后发现了group_concat函数。记录一下,以后能用。
语法:group_concat( [distinct] 要连接的字段 [order by 排序字段 asc/desc ] [separator '分隔符'] )
说明:通过使用distinct可以排除重复值(去重);如果希望对结果中的值进行排序,可以使用order by子句;separator是一个字符串值,缺省为一个逗号。[]中的就是选填的
$list = self::where("uid",$uid)
->field('FROM_UNIXTIME(add_time,"%Y-%m") as time,group_concat(id SEPARATOR ",") ids')
->whereTime('add_time','between',[$start_time,$end_time])
->group('time')
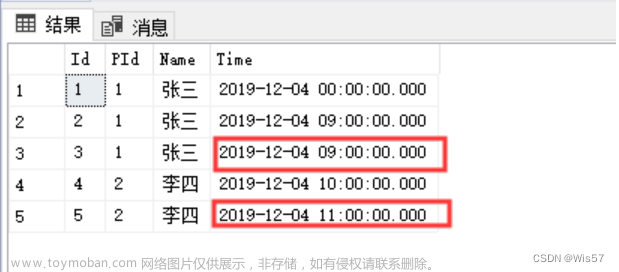
->select()->toArray();上面代码是用年月分组,然后把id连接显示,结果如下
Array
(
[0] => Array
(
[time] => 2023-02
[ids] => 4,5,6,7,13,14,15,16,17,18,28,29,30
)
)这样就知道2023年2月份的相关记录的id了
参考资料:
数据库数据
+------+------+
| id| name |
+------+------+
|1 | 10|
|1 | 20|
|1 | 20|
|2 | 20|
|3 | 200 |
|3 | 500 |
+------+------+
可以用下面的SQL测试一下效果
1、以id分组,把name字段的值打印在一行,逗号分隔(默认)
select id,group_concat(name) from aa group by id;
select id,group_concat(name separator ';') from aa group by id;
2、以id分组,把去冗余的name字段的值打印在一行,name(去重复)
select id,group_concat(distinct name) from aa group by id;
3、以id分组,把name字段的值打印在一行,逗号分隔,以name排倒序
select id,group_concat(name order by name desc) from aa group by id; 另外个函数:concat()
语法:concat(str1, str2,...),返回结果为连接参数产生的字符串,如果有任何一个参数为null,则返回值为null。
1、select concat (id, name, score) as info from tt2;
我们可以加一个逗号作为分隔符:
2、select concat (id,',', name,',', score) as info from tt2;concat_ws()函数:功能:和concat()一样,将多个字符串连接成一个字符串,但是可以一次性指定分隔符~(concat_ws就是concat with separator)
语法:concat_ws(separator, str1, str2, ...)
说明:第一个参数指定分隔符。需要注意的是分隔符不能为null,如果为null,则返回结果为null。
select concat_ws(',',id, name, score) as info from tt2;注意:把分隔符指定为null,结果全部变成了null:
select concat_ws(null,id, name, score) as info from tt2;结合应用:
我们要查询以name分组的所有组的id和score:按id排序,拼接id和score
select name,group_concat(concat_ws('-',id,score) order by id) from tt2 group by name
我们要试试以name分组的所有组的id和score:按id倒序,拼接id和score,用‘;’做分隔符
select name,group_concat(concat_ws('-',id,score) order by id desc separator ';') from tt2 group by name借鉴文章
https://baijiahao.baidu.com/s?id=1595349117525189591&wfr=spider&for=pc文章来源:https://www.toymoban.com/news/detail-445913.html
https://blog.csdn.net/qq_32907195/article/details/106852951文章来源地址https://www.toymoban.com/news/detail-445913.html
到了这里,关于group by聚合分组后如何获取分组数据的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!