-
hive入门到精通
-
hive部署
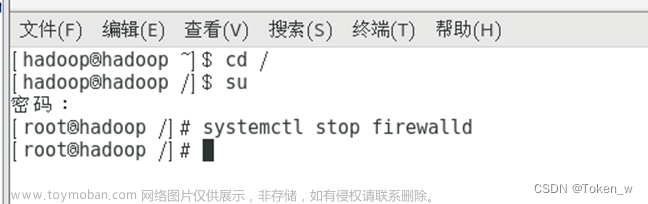
- 启动Hadoop
- 检查MySQL是否启动成功
-
安装hive
- hive-env.sh
-
hive-site.xml
- 需要修改的位置提炼如下:
- 上传 MySQL 连接驱动 jar 包到 hive 安装目录的lib目录下:
- guava版本冲突
- 配置环境变量
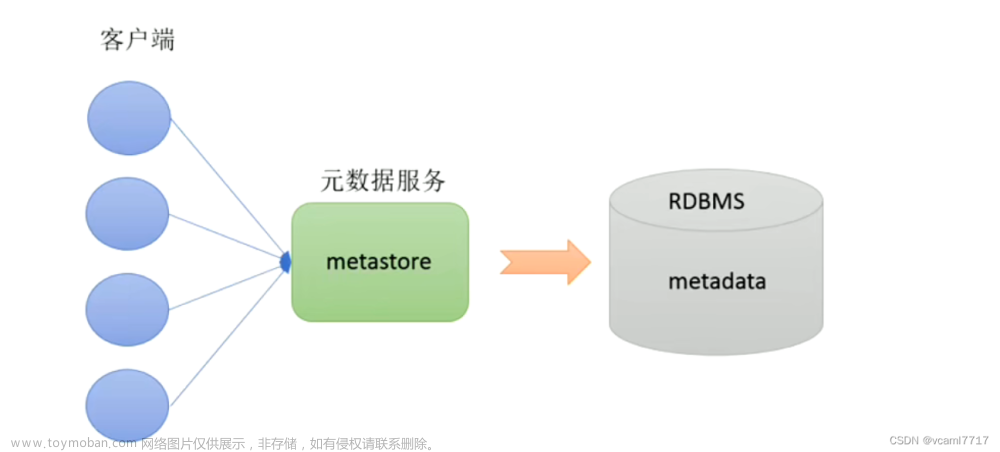
- 初始化hive的元数据库
- 远程模式
- 体验
-
编程
-
DDL
-
操作数据库
- 创建数据库
- 查询数据库
- 修改数据库
- 删除数据库
- 切换数据库
-
操作数据库
-
DML
-
操作数据表
- 基本数据类型
- 内部表
- 外部表
- 部表与外部表转换
- 查看表
- 修改表
- 删除表
- 清除表
-
操作数据表
-
DQL
- 准备数据
- 单表查询
- 综合练习
-
高级聚合函数
- 分组排序取TopN
- UDTF
- UDTF 案例
- 分组和去重
-
开窗函数
- 聚合函数
-
跨行取值
- lead lag
- first_value last_value
-
综合练习
- 准备数据
- 练习题目
-
分区表
-
模拟数据
- 身份证前六位
- 身份证前六位
- pom.xml
- 工具类
- 创建数据库
- 内部分区表
-
内部分区表
- 导入数据
-
外部分区表
- 创建外部分区表关联目录
- 创建外部分区表
- 导入数据
-
多重内部分区表
- 创建内部多重内部分区表
- 导入数据
-
多重外部分区表
- 创建多重外部分区表关联目录
- 创建多重外部分区表
- 动态分区
-
模拟数据
-
分桶
- 创建普通表并导入数据
- 开启分桶
- 创建桶表
- 载入数据到桶表
- 视图
-
存储与压缩
- 文件格式
- text file:
- sequence file
- ORC
- Parquet
- rcfile
-
DDL
-
hive部署
hive入门到精通
hive部署
启动Hadoop
# 启动hadoop
start-all.sh
# 检查hadoop进程
jps
# 检查各端口
netstat -aplnt | grep java
检查MySQL是否启动成功
ps -aux | grep mysql
netstat -aplnt | grep 3306
安装hive
# 将软件上传到 /opt/soft 目录
# 解压hive
tar -zxvf apache-hive-3.1.3-bin.tar.gz
# 目录改名
mv apache-hive-3.1.3-bin hive3
# 进入配置文件目录
cd /opt/soft/hive3/conf
# 复制配置文件
cp hive-env.sh.template hive-env.sh
cp hive-default.xml.template hive-site.xml
# 编辑环境配置文件
vim hive-env.sh
# 编辑配置文件
vim hive-site.xml
hive-env.sh
# hadoop 安装路径
export HADOOP_HOME=/opt/soft/hadoop3/
# hive 配置文件路径
export HIVE_CONF_DIR=/opt/soft/hive3/conf/
hive-site.xml
需要修改的位置提炼如下:
<configuration>
<!-- 记录HIve中的元数据信息 记录在mysql中 -->
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://spark03:3306/hive?useUnicode=true&createDatabaseIfNotExist=true&characterEncoding=UTF8&useSSL=false&serverTimeZone=Asia/Shanghai</value>
</property>
<!-- jdbc mysql驱动 -->
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.cj.jdbc.Driver</value>
</property>
<!-- mysql的用户名和密码 -->
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>Lihaozhe!!@@1122</value>
</property>
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
</property>
<property>
<name>hive.exec.scratchdir</name>
<value>/user/hive/tmp</value>
</property>
</property>
<property>
<name>hive.exec.local.scratchdir</name>
<value>/user/hive/local</value>
<description>Local scratch space for Hive jobs</description>
</property>
<property>
<name>hive.downloaded.resources.dir</name>
<value>/user/hive/resources</value>
<description>Temporary local directory for added resources in the remote file system.</description>
</property>
<!-- 日志目录 -->
<property>
<name>hive.querylog.location</name>
<value>/user/hive/log</value>
</property>
<!-- 设置metastore的节点信息 -->
<property>
<name>hive.metastore.uris</name>
<value>thrift://spark01:9083</value>
</property>
<!-- 客户端远程连接的端口 -->
<property>
<name>hive.server2.thrift.port</name>
<value>10000</value>
</property>
<property>
<name>hive.server2.thrift.bind.host</name>
<value>0.0.0.0</value>
</property>
<property>
<name>hive.server2.webui.host</name>
<value>0.0.0.0</value>
</property>
<!-- hive服务的页面的端口 -->
<property>
<name>hive.server2.webui.port</name>
<value>10002</value>
</property>
<property>
<name>hive.server2.long.polling.timeout</name>
<value>5000</value>
</property>
<property>
<name>hive.server2.enable.doAs</name>
<value>true</value>
</property>
<!--
<property>
<name>datanucleus.autoCreateSchema</name>
<value>false</value>
</property>
<property>
<name>datanucleus.fixedDatastore</name>
<value>true</value>
</property>
-->
<property>
<name>hive.execution.engine</name>
<value>mr</value>
</property>
<property>
<name>hive.metastore.schema.verification</name>
<value>false</value>
<description>
Enforce metastore schema version consistency.
True: Verify that version information stored in is compatible with one from Hive jars. Also disable automatic
schema migration attempt. Users are required to manually migrate schema after Hive upgrade which ensures
proper metastore schema migration. (Default)
False: Warn if the version information stored in metastore doesn't match with one from in Hive jars.
</description>
</property>
</configuration>
注意:上面配置文件中的路径在 vi 编辑器下 全局替换
:%s@\${system:java.io.tmpdir}@/tmp/hive-logp@g不要使用图形化 不然每次保存后3215行都会有个  特殊字符 如果产生删除即可 具体报错信息 后面有单独的描述
上传 MySQL 连接驱动 jar 包到 hive 安装目录的lib目录下:
/opt/soft/hive3/lib
jar 包有两个 分别为:
- mysql-connector-java-8.0.33.jar
- protobuf-java-3.22.2.jar
删除原有的 protobuf-java-2.5.0.jar 文件
guava版本冲突
删除 hive/lib目录中的 guava-19.0.jar
拷贝hadoop/share/hadoop/common/lib目录中的 guava-27.0-jre.jar 到 hive/lib 目录
rm -f /opt/soft/hive3/lib/guava-19.0.jar
cp -v /opt/soft/hadoop3/share/hadoop/common/lib/guava-27.0-jre.jar /opt/soft/hive3/lib
配置环境变量
vim /etc/profile
export HIVE_HOME=/opt/soft/hive3
export PATH=$PATH:$HIVE_HOME/bin
source /etc/profile
初始化hive的元数据库
注意:初始初始元素中库之前 保证 hadoop 和 mysql 正常启动
schematool -initSchema -dbType mysql
Exception in thread "main" java.lang.RuntimeException: com.ctc.wstx.exc.WstxParsingException: Illegal character entity: expansion character (code 0x8
at [row,col,system-id]: [3215,96,"file:/usr/local/hive/conf/hive-site.xml"]
at org.apache.hadoop.conf.Configuration.loadResource(Configuration.java:3051)
...
at org.apache.hadoop.util.RunJar.main(RunJar.java:236)
Caused by: com.ctc.wstx.exc.WstxParsingException: Illegal character entity: expansion character (code 0x8
at [row,col,system-id]: [3215,96,"file:/usr/local/hive/conf/hive-site.xml"]
at com.ctc.wstx.sr.StreamScanner.constructWfcException(StreamScanner.java:621)
...
at org.apache.hadoop.conf.Configuration.loadResource(Configuration.java:3034)
... 17 more
报错原因:
hive-site.xml配置文件中,3215行(见报错记录第二行)有特殊字符
解决办法:
进入hive-site.xml文件,跳转到对应行,删除里面的  特殊字符即可
Caused by: java.net.URISyntaxException: Relative path in absolute URI: ${system:java.io.tmpdir%7D/$%7Bsystem:user.name%7D
at java.net.URI.checkPath(URI.java:1822)
at java.net.URI.<init>(URI.java:745)
at org.apache.hadoop.fs.Path.initialize(Path.java:260)
解决方案:将hive-site.xml配置文件的
hive.querylog.location
hive.exec.local.scratchdir
hive.downloaded.resources.dir
三个值(原始为$标识的相对路径)写成绝对值
# 全局替换
:%s@\${system:java.io.tmpdir}@/tmp/hive-logp@g
远程模式
# 启动服务端
hive --service metastore &
hive --service hiveserver2 &
# 后台运行
nohup hive --service metastore > /dev/null 2>&1 &
nohup hive --service hiveserver2 > /dev/null 2>&1 &
hiveserver2 start
nohup hiveserver2 >/dev/null 2>&1 &
# 客户端连接
hive
beeline -u jdbc:hive2://spark01:10000 -n root
beeline jdbc:hive2://spark01:10000> show databases;
体验
use default;
create table person (
id int,
phonenum bigint,
salary double,
name string
);
create table ps (
id int,
phonenum bigint,
salary double,
name string
);
show tables;
insert into person values (1001,13966668888,9999.99,"张三");
songsong,bingbing_lili,xiao song:18_xiaoxiao song:19
longlong,pingping_liuliu,xiao long:8_xiaoxiao long:9
drop table person;
create table person (
name string,
friends array<string>,
childrens map<string,int>
)
row format delimited fields terminated by ','
collection items terminated by '_'
map keys terminated by ':'
lines terminated by '\n';
load data local inpath '/root/person.txt' into table person;
drop table data;
create table data (
name string,
amount int
)
row format delimited fields terminated by ','
lines terminated by '\n';
load data local inpath '/root/data.txt' into table data;
select count(*) from data;
select count(*) from data group by name;
select name,max(t) from data group by name;
select name,max(t) from data group by name order by max(t) ;
编程
DDL
操作数据库
创建数据库
-- 创建数据库不指定路径
create database db_hive01;
-- 创建数据库指定 hdfs 路径
create database db_hive02 location '/db_hive02';
-- 创建数据库附加 dbproperties
create database db_hive03 with dbproperties ('create-date'='2023-04-17','create_author'='lihaozhe');
查询数据库
-- 查看所有数据库
show databases;
-- 模糊查看所有数据库
-- * 代表所有
-- | 代表或
show databases like 'db_hive*';
-- 查看数据库信息
desc database db_hive03;
-- 查看数据库详尽信息
describe database db_hive03;
-- 查看数据库更详尽信息
describe database extended db_hive03;
修改数据库
-- 修改 dbproperties
alter database db_hive03 SET dbproperties ('crate_data'='2023-04-18');
-- 修改location
alter database db_hive02 SET location '/db_hive002';
-- 修改 owner user
alter database database_name set owner user lhz;
删除数据库
-- 删除空数据库
drop database db_hive02 restrict;
-- 删除非空数据库
drop database db_hive03 cascade;
切换数据库
use db_hive01;
DML
操作数据表
普通表
临时表 temporary
外部表 external
-- 利用 select 语句查询结果 创建一张表
create table as select
-- 复刻一张已经存在的表结构 但是 不包含数据
create table like
基本数据类型
| 数据类型 | 说明 | 定义 |
|---|---|---|
| tinyint | 1 byte 有符号整型 | |
| smallint | 2 byte 有符号整型 | |
| int | 4 byte 有符号整型 | |
| bigint | 8 byte 有符号整型 | |
| float | 4 byte 单精度浮点数 | |
| double | 8 byte 双精度浮点数 | |
| dicimal | 十进制精准数据类型 | |
| varchar | 字符序列 需要指定最大长度 范围[1~65535] | |
| string | 字符串 无需指定最大长度 | |
| timestamp | 时间 | |
| binary | 二进制数据 | |
| boolean | true false | |
| array | 一组相同数据类型的集合 | array |
| map | 一组相同数据类型的键值对 | map<string,int> |
| struct | 由多个属性组成,每个属性都有自己的属性名和数据类型 | structid:int,name:string |
内部表
简单表
create table person (
id int,
phonenum bigint,
salary dicimal,
name string
);
show tables;
insert into person values (1001,13966668888,9999.99,"张三");
简单数据类型
create table data (
name string,
amount int
)
row format delimited fields terminated by ','
lines terminated by '\n'
location '/user/hive/warehouse/lihaozhe.db/data';
# 上传文件到Hive表指定的路径
hdfs dfs -put /root/data.csv /user/hive/warehouse/lihaozhe.db/data
复杂数据类型
vim /root/person.txt
songsong,bingbing_lili,xiao song:18_xiaoxiao song:19
longlong,pingping_liuliu,xiao long:8_xiaoxiao long:9
drop table person;
create table person (
name string,
friends array<string>,
childrens map<string,int>
)
row format delimited fields terminated by ','
collection items terminated by '_'
map keys terminated by ':'
lines terminated by '\n';
load data local inpath '/root/person.txt' into table person;
json数据类型
json函数
get_json_object
json_tuple
json serde加载数据
--serialization 序列化 --deserialization 反序列化
{"name":"user01","amount":"100"}
{
"name":"lhz",
"friends":["lize","lanlan","manman"],
"students":[
"xiaohui":15000,"huixiaoxiao":18000
],
"address":{
"province":"jilin",
"city":"liaoyuan",
"district":"liaoyuan"
}
}
-- 案例一
create table video (info string);
load data local inpath '/root/video.log' into table video;
select * from video limit 10;
select count(*) from video;
select
get_json_object(info,'$.id') as id,
get_json_object(info,'$.nickname') as nickname,
get_json_object(info,'$.gold') as gold
from video limit 5;
select
json_tuple(info,'id','nickname',"gold") as (id,nickname,gold)
from video limit 5;
案例二
create table video(
id string ,
uid string,
nickname string,
gold int,
watchnumpv int,
watchnumuv int,
hots int,
nofollower int,
looktime int,
smlook int ,
follower int ,
gifter int ,
length int ,
area string ,
rating varchar(1),
exp int ,
type string
)
row format serde 'org.apache.hive.hcatalog.data.JsonSerDe';
load data local inpath '/root/video.log' into table video;
--把json数据,按类给格式化,
STORED AS TEXTFILE;--文本文档的形式
--导入数据
load data local inpath '/root/video.log' into table video;
创建表的loaction'' 作用是 集群里边有对应的数据,则直接将数据加载到表中
load data loacl inpath '' into table 是使用hive将数据从本地加载到已经建好的表中
load data inpath '' into table 是使用hive将数据从集群里边加载到已经建好的表中
外部表
create external table data (
name string,
amount int
)
row format delimited fields terminated by ','
lines terminated by '\n'
location '/user/hive/warehouse/lihaozhe.db/data';
部表与外部表转换
-- 内部表转外部表
alter table tblName set tblproperties('external'='true');
-- 外部表转内部表
alter table tblName set tblproperties('external'='false');
查看表
-- 查看表
show tables;
-- 查看某数据库下的某张表
show tables in lihaozhe;
-- 查看表
show tables;
-- 模糊查看数据表
-- * 代表所有
-- | 代表或
show tables like 'per*';
-- 查看基本表信息
describe person;
-- 查看基本表详细信息
describe extended person;
-- 查看基本表详细信息并格式化展示
describe formatted person;
修改表
-- 修改表名称
alter table person rename to tb_user;
-- 添加字段 向末尾追加
alter table tb_user add columns (gender tinyint);
-- 修改字段名称及类型
alter table tb_user change gender age smallint;
-- 删除字段
删除表
drop table tb_user
清除表
truncate table video;
DQL
准备数据
-- 部门表 dept.csv
10,行政部,1700
20,财务部,1800
30,教学部,1900
40,销售部,1700
hdfs dfs -mkdir -p /quiz01/dept
hdfs dfs -put /root/dept.csv/quiz01/dept
create external table dept(
dept_id int comment '部门id',
dept_name string comment '部门名称',
location_code int comment '部门位置'
)
comment '部门表'
row format delimited fields terminated by ','
lines terminated by '\n'
stored as textfile
location '/quiz01/dept';
load data local inpath '/root/dept.csv' into table dept;
员工表
7369,张三,研发,800.00,30
7499,李四,财务,1600.00,20
7521,王五,行政,1250.00,10
7566,赵六,销售,2975.00,40
7654,侯七,研发,1250.00.30
7698,马八,研发,2850.00,30
7782,金九,行政,2450.0,30
7788,银十,行政,3000.00,10
7839,小芳,销售,5000.00,40
7844,小明,销告,1500.00,40
7876,小李,行政,1100.00,10
7900,小元,讲师,950.00,30
7902,小海,行政,3000.00,10
7934,小红明,讲师,1300.00,30
hdfs dfs -mkdir -p /quiz01/emp
hdfs dfs -put /root/emp.csv /quiz01/emp
create external table emp
(
emp_id int comment '员工ID',
emp_name string comment '员工姓名',
emp_job string comment '员工岗位',
emp_salary decimal(8, 2) comment '员工薪资',
dept_id int comment '员工隶属部门ID'
)
comment '员工表'
row format delimited fields terminated by ','
lines terminated by '\n'
stored as textfile
location '/quiz01/emp' ;
load data local inpath '/root/emp.csv' into table emp;
居民表 person.csv
hdfs dfs -mkdir -p /quiz02/person
hdfs dfs -put /root/person.csv /quiz02/person
CREATE external TABLE `person` (
`id` int COMMENT '主键',
`id_card` varchar(18) COMMENT '身份证号码',
`mobile` varchar(11) COMMENT '中国手机号',
`real_name` varchar(15) COMMENT '身份证姓名',
`uuid` varchar(32) COMMENT '系统唯一身份标识符'
)
row format delimited fields terminated by ','
lines terminated by '\n'
stored as textfile
location '/quiz02/person';
load data local inpath '/root/person.csv' into table person;
地区表 region.csv
hdfs dfs -mkdir -p /quiz02/region
hdfs dfs -put /root/region.csv /quiz02/region
CREATE external TABLE `region` (
`parent_code` int COMMENT '当前地区的上一级地区代码',
`region_code` int COMMENT '地区代码',
`region_name` varchar(10) COMMENT '地区名称'
)
row format delimited fields terminated by ','
lines terminated by '\n'
stored as textfile
location '/quiz02/region';
load data local inpath '/root/region.csv' into table region;
单表查询
-- 查询所有
select * from dept;
-- 按照指定字段查询
select dept_name from dept;
-- 列别名
select dept_name as name from dept;
-- limit 分页查询
select * from emp limit 5,5
-- where 按条件查询
select * from emp where dept_id = 10;
-- 关系运算符
-- = != > >= < <=
-- in
select * from emp where dept_id in (20,40);
-- not in
select * from emp where dept_id not in (20,40);
-- like
select * from emp where emp_name like '小%';
-- not like
select * from emp where emp_name not like '小%';
-- 逻辑运算符
-- and
select * from emp where dept_id = 30 and emp_salary > 1000;
-- between and
select * from emp where dept_id = 30 and emp_salary > 1000 and emp_salary < 2000;
select * from emp where dept_id = 30 and emp_salary between 1000 and 2000;
--not between and
select * from emp where dept_id = 30 and emp_salary not between 1000 and 2000;
-- or
select * from emp where dept_id = 10 or dept_id = 40;
-- not !
select * from emp where dept_id != 10;
select * from emp where not dept_id = 10;
-- 聚合函数
-- count(*) count(1) count(column_name)
select count(*) from emp;
select count(*) as total from emp;
-- max
select max(emp_salary) from emp;
-- min
select min(emp_salary) from emp;
-- sum
select sum(emp_salary) from emp;
-- avg
select avg(emp_salary) from emp;
-- group by 分组查询
select dept_id, avg(emp_salary) as avg_salary from emp group by dept_id;
-- having
select dept_id, avg(emp_salary) as avg_salary from emp group by dept_id having avg_salary > 2000;
-- where having
select dept_id, avg(emp_salary) as avg_salary from emp where dept_id != 10 group by dept_id having avg_salary > 2000;
-- order by 全局排序
select * from emp order by dept_id desc ,emp_salary desc;
select dept_id, max(emp_salary) from emp group by dept_id;
select dept_id, max(emp_salary) as max_salary from emp group by dept_id order by max_salary desc;
-- sort by (每个reduce)内部排序
select * from emp sort by dept_id desc
-- 查看 reduce 数量
set mapreduce.job.reduces;
-- 设置 reduce 数量 仅在当前连接有效 连接断开失效
set mapreduce.job.reduces=2;
select * from emp sort by dept_id desc;
-- 将查询结果写入到文件
insert overwrite local directory '/root/sort-result' select * from emp sort by dept_id desc;
-- distribute by 分区 类似与 mapreduce 中的 partation 自定义分区
set mapreduce.job.reduces=2;
insert overwrite local directory '/root/distribute-result' select * from emp distribute by dept_id sort by emp_salary desc;
-- distribute by 分区规则 根据字段的hash值 与 reduce 的数量 进行相除 余数 相同的在到一个分区
-- hvie 要求 distribute by 语句执行 在 sort by 语句之前
-- 执行结束之后 将 mapreduce.job.reduces 设置为 -1 不然 会影响 分区 分桶 load
-- cluster by 只能升序 不能降序 cluster by = sort by + distribute by
select * from emp cluster by dept_id;
多表查询
-- 笛卡尔积
select * from dept,emp;
-- 避免笛卡尔积
select * from dept,emp where dept.dept_id = emp.dept_id
-- 等值json 内连接
select * from dept join emp where dept.dept_id = emp.dept_id
-- left join 左外连接
select d.dept_id,d.dept_name,d.location_code,e.emp_id,e.emp_name,e.emp_jpb,e.emp_salary
from dept d left join emp e where d.dept_id = e.dept_id;
-- right join 右外连接
select d.dept_id,d.dept_name,d.location_code,e.emp_id,e.emp_name,e.emp_jpb,e.emp_salary
from dept d right join emp e where d.dept_id = e.dept_id;
-- full join 满外连接
select d.dept_id,d.dept_name,d.location_code,e.emp_id,e.emp_name,e.emp_jpb,e.emp_salary
from dept d full join emp e where d.dept_id = e.dept_id;
-- union 上下拼接 去重
select * from emp where dept_id = 10 or dept_id = 40;
select * from emp where dept_id in(10,40);
select * from emp where dept_id = 10 union select * from emp where dept_id = 40;
-- union all 上下拼接 不去重
select * from emp where dept_id = 10 or dept_id = 40;
select * from emp where dept_id in(10,40);
select * from emp where dept_id = 10 union all select * from emp where dept_id = 40;
-- 自关联
select * from region where region_code='220422';
--
函数
# 设施本地模式
set hive.exec.mode.local.auto=true;
set mapperd.job.tracker=local
-- 算术运算符
-- + — * / % & | ~
-- 数值运算
-- round 四舍五入
select round (3.3) as num;
-- ceil 向上取整
select ceil(3.3) as num;
-- floor 向下取整
select floor(3.3) as num;
-- 字符串
-- 截取 substr(column_name,start_index,length)
select substr(id_card,3,3) from person;
-- substring(column_name,start_index,length)
select substring(id_card,3,3) from person;
-- spilt 字符串切割
select split('2023-04-19','-');
-- nvl 判空 替换 null 值
select nvl("lhz",1);
select nvl(null,1);
-- replace 字符串替换
SELECT REPLACE('aaa.mysql.com','a','w');
-- concat 字符串拼接
select concat('slogan','-','tlbyxzcx');
-- concat 字符串拼接
select concat_ws('-',array('2022','04','19'));
-- get_json_object 解析 json 字符串
select get_json_object('[{"name":"lhz","age":41}]','$.name') as name;
select get_json_object('[
{"name":"lhz","age":41},
{"name":"lz","age":14}
]','$.[0].name')
-- json_tuple
select json_tuple('{"name":"lhz","age":41}','name','age') as (name,age);
-- 日期函数
-- unix 时间戳
--(1970.01.01 00:00:00 GMT UTC 时间)
-- unix_timestamp 返回 bigint 无时区
select unix_timestamp();-- 1681951622 时间秒数
select unix_timestamp('1983-11-22 20:30:00','yyyy-MM-dd HH:mm:ss'); -- 438381000
-- from_unixtime
select from_unixtime(438381000); -- 1983-11-22 20:30:00
-- current_date
select current_date();
-- current_timestamp
select current_timestamp();
-- year month day hours minute second
select year('1983-01-23');
-- datediff 两个日期相差天数(结束日期减去开始日期)
select datediff('1983-01-23','1982-12-31')
-- date_add 日期增加几天
select date_add('1995-01-01',15);
-- date_sub 日期减少几天
select date_sub('1995-01-01',15);
-- date_format 日期格式化
select date_format ('1983-11-22 20:30:00','yyyy年MM月dd日 HH时mm分ss秒');
-- 读取身份证获取出生日期 输出格式为 yyyy-MM-dd
-- 1、字符串截取 2、日期格式化
select substr(id_card,7,8) from person limit 3;
select unix_timestamp(substr(id_card,7,8),'yyyyMMdd') from person limit 3;
select from_unixtime(unix_timestamp(substr(id_card,7,8),'yyyyMMdd')) from person limit 3;
select substr(from_unixtime(unix_timestamp(substr(id_card,7,8),'yyyyMMdd')),1,10) from person limit 3;
-- 流程控制语句
-- case when
-- >90 a,80~90 b, 70~80 c, 60~70 的,<60 e
select
stu_id,course_id,
case
when score >= 90 then 'A'
when score >= 80 then 'B'
when score >= 70 then 'c'
when score >= 60 then 'D'
else'E'
end as grade
From score;
-- if 三目运算 if(条件表达式,条件为真的返回结果,条件为假的返回结果)
select if(1=2,'托尼','玛丽') as `发型师`
-- 结合字符串函数 时间函数 流程控制函数 计算身份证信息
-- 根据身份证号 判断性别 身份证号 第十七位 奇数为男性 偶数为女性
select id_card, if(mod(substr(id_card,17,1),2) = 1,'精神小伙儿','扒蒜老妹儿') gender from person;
-- 根据身份证号 找出所有男性信息
select *, mod(substr(id_card,17,1),2) gender from person where mod(substr(id_card,17,1),2) = 1;
-- 根据身份证号 计算男性人数和女性人数
select
if(mod(substr(id_card,17,1),2) = 1,'精神小伙儿','扒蒜老妹儿') gender ,
count(*) gender_count
from person group by mod(substr(id_card,17,1),2) limit 10;
-- 根据身份证号 计算生日排序
select
date_format(from_unixtime( unix_timestamp(substr(id_card,7,8),'yyyyMMdd')),'yyyy-MM-dd') as `birthday`
from person
order by unix_timestamp(`birthday`,'yyyy-MM-dd') desc
-- 根据身份证号 计算年龄
-- 1、当前月份-出生月份 > 0 说明 已经过完生日 及 使用 当前年份 - 出生年份 = 年龄
-- 2、当前月份-出生月份 < 0 说明 未过生日 及 使用 当前年份 - 出生年份 -1 = 年龄
-- 3、当前月份-出生月份 = 0
-- 3.1、当前日-出生日 > 0 说明 已经过完生日 及 使用 当前年份 - 出生年份 = 年龄
-- 3.2、当前日-出生日 < 0 说明 未过生日 及 使用 当前年份 - 出生年份 -1 = 年龄
-- 3.3、当前日-出生日 = 0 说明 生日视作过完了 及 使用 当前年份 - 出生年份 = 年龄
select if(month(`current_date`()) - month(from_unixtime(unix_timestamp(substr(id_card, 7, 8), 'yyyyMMdd'))) > 0,
year(`current_date`()) - year(from_unixtime(unix_timestamp(substr(id_card, 7, 8), 'yyyyMMdd'))),
if(month(`current_date`()) - month(from_unixtime(unix_timestamp(substr(id_card, 7, 8), 'yyyyMMdd'))) < 0,
year(`current_date`()) - year(from_unixtime(unix_timestamp(substr(id_card, 7, 8), 'yyyyMMdd'))) - 1,
if(day(`current_date`()) - day(from_unixtime(unix_timestamp(substr(id_card, 7, 8), 'yyyyMMdd'))) > 0,
year(`current_date`()) - year(from_unixtime(unix_timestamp(substr(id_card, 7, 8), 'yyyyMMdd'))),
if(day(`current_date`()) - day(from_unixtime(unix_timestamp(substr(id_card, 7, 8), 'yyyyMMdd'))) < 0,
year(`current_date`()) - year(from_unixtime(unix_timestamp(substr(id_card, 7, 8), 'yyyyMMdd'))) - 1,
year(`current_date`()) - year(from_unixtime(unix_timestamp(substr(id_card, 7, 8), 'yyyyMMdd')))
)
)
)
) as `age`
from person;
-- 集合函数
-- size 集合中元素的数量
select size(array(0,1,2,3,4,5));
-- array 声明一个集合 数组
select array(0,1,2,3,4,5) as nums;
-- array_contains 判断array中是否包含某元素 返回值是 布尔值 tury false
select array_contains(array(0,1,2,3,4,5),3) as num;
-- sort_array 排序 目前只能升序
select sort_array(array(0,1,2,3,4,5));
-- struct 声明结构体属性名称
select struct('real_name','lhz','age','41');
-- {"col1":"real_name","col2":"lhz","col3":"age","col4":"41"}
-- named_struct 声明结构体属性和值
select named_struct('real_name','lhz','age','41');
-- {"real_name":"lhz","age":"41"}
-- 集合函数
-- map
select map('xz',1000,'js',800);
-- {"xz":1000,"js":800}
-- map_keys 返回 map 中所有的 key
select map_keys(map('xz',1000,'js',800));
-- map_values 返回 map 中所有的 value
select map_values(map('xz',1000,'js',800));
-- if 三目运算
select if(条件表达式,条件为真表达式,条件为假表达式)
练习
数据:
学生表
讲师表
课程表
分数表
学生表 student.csv
hdfs dfs -mkdir -p /quiz03/student
hdfs dfs -put /root/student.csv /quiz03/student
load data local inpath '/root/student.csv' into table student;
课程表 course.csv
hdfs dfs -mkdir -p /quiz03/course
hdfs dfs -put /root/course.csv /quiz03/course
load data local inpath '/root/course.csv' into table course;
分数表 score.csv
hdfs dfs -mkdir -p /quiz03/score
hdfs dfs -put /root/score.csv /quiz03/score
load data local inpath '/root/course.csv' into table course;
-- 学生表
create external table student (
stu_id string comment '学生ID',
stu_name string comment '学生姓名',
birthday string comment '出生年月',
gender string comment '学生性别'
)
row format delimited fields terminated by ','
lines terminated by '\n'
stored as textfile
location '/quiz03/student';
--教师表
create external table teacher (
tea_id string comment '课程ID',
tea_name string comment '教师名称'
)
row format delimited fields terminated by ','
lines terminated by '\n'
stored as textfile
location '/quiz03/teacher';
--课程表
create external table course (
coures_id string comment '课程ID',
coures_name string comment '课程名称',
tea_id string comment '讲师ID'
)
row format delimited fields terminated by ','
lines terminated by '\n'
stored as textfile
location '/quiz03/course';
--成绩表
create external table score (
stu_id string comment '学生ID',
coures_id string comment '课程ID',
score string comment '成绩'
)
row format delimited fields terminated by ','
lines terminated by '\n'
stored as textfile
location '/quiz03/score';
综合练习
-- 查询所有学生信息
select * from student;
-- 查询周姓学生信息
select * from student where stu_name like '周%';
-- 查询周姓学生数量
select count(*) as zhou_count from student where stu_name like '周%';
-- 查询 学生ID 004 的分数 超过 85 的成绩
select * from score where stu_id = 004 and score > 85;
-- 查询 学生ID 004 的分数 超过 85 的成绩
select * from score where stu_id = 004 and score > 85;
-- 查询 学生程ID 004 的成绩降序
select * from score where stu_id = 01 order by score desc;
-- 查询 数学成绩不及格学生及其对应的成绩 安装学生ID排序
select stu.stu_id, stu.stu_name,s.score
from student stu join course c join score s
on stu.stu_id = s.stu_id and c.course_id = s.course_id
and c.course_name = '数学' and s.score < 60
order by stu.stu_id;
-- 查询男女生人数
select gender,count(*) as gender_count from student group by gender;
-- 查询编号为 02 的课程平均成绩
select avg(score) from score where course_id = 02;
-- 查询每科课程平均成绩
select avg(score) from score group by course_id;
-- 查询参加考试学生人数
select count(distinct stu_id) as stu_count from score;
-- 查询每科有多少学生参加考试
select course_id,count(*) as stu_count from score group by course_id;
-- 查询未参加考试的学生信息
select stu_id,stu_name from student where stu_id not in (
select distinct stu.stu_id from student stu left join course c left join score s
on stu.stu_id = s.stu_id and c.course_id = s.course_id
order by stu.stu_id
)
-- 查询平均成绩及格(60分)的学生的平均成绩
select stu_id, avg(score) avg_score
from score
group by stu_id
having avg_score >= 60;
-- 查询选修至少 4 门 以上课程学生的学号
select stu_id,count(course_id) course_count from score
group by stu_id
having course_count >= 4;
-- 查询姓氏相同学生名单 并且同姓人数大于 2 的姓氏
select first_name ,count(*) first_name_count from (
select stu_id,stu_name,substr(stu_name,1,1) as first_name
from student
) ts
group by ts.first_name
having first_name_count > 1;
-- 查询每门功课的学生的平均成绩 按照平均成绩升序 平均成绩相同按照课程编号降序
select course_id, avg(score) avg_score
from score
group by course_id
order by avg_score,course_id desc;
-- 统计参加考试人数大于等于 15 的学科
select course_id,count(*) as stu_count from score group by course_id having stu_count > 15;
-- 查询学生总成绩并按照总成绩降序排序
select stu_id, sum(score) sum_score
from score
group by stu_id
order by sum_score desc;
-- 按照指定格式显示 stu_id 语文 数学 英语 选课数 平均成绩
select
s.stu_id,
sum(`if`(c.course_name='语文',score,0)) as `语文`,
sum(`if`(c.course_name='数学',score,0)) as `数学`,
sum(`if`(c.course_name='英语',score,0)) as `英语`,
count(s.course_id) as `选课数`,
avg(s.score) as `平均成绩`
from course c left join score s
on c.course_id = s.course_id
group by s.stu_id
order by `平均成绩` desc;
-- 查询一共参加了三门功课且其中一门为语文的学生id 和 姓名
select s.stu_id,stu_name from
(select t1.stu_id ,count(t1.course_id) course_count from
(select stu_id,course_id from score
where stu_id in ( select stu_id from score where course_id = "01")
) t1 group by t1.stu_id having course_count >=3
) t2 join student s on t2.stu_id = s.stu_id;
-- 分解
-- 查询该学生的姓名
select s.stu_id,stu_name from
-- 成绩表中学习科目数量 >=3 科的学生
(select t1.stu_id ,count(t1.course_id) course_count from
-- 报名了语文的学生还报名了那些学科
(select stu_id,course_id from score
where stu_id in (
-- 查询报名了语文的学生ID
select stu_id from score where course_id = "01"
)
) t1 group by t1.stu_id having course_count >=3
) t2 join student s on t2.stu_id = s.stu_id;
-- 查询两门以上的课程不及格学生的学号及其平均成绩
-- 1、先按照学生分组 过滤出成绩低于60的数量 大于1
-- 2、计算所有学生的平均成绩
-- 3、两个子查询相互join
select t1.stu_id,t2.avg_score from
(select stu_id, sum(if(score < 60, 1, 0)) as result from score group by stu_id having result > 1) t1
left join
(select stu_id,avg(score) as avg_score from score group by stu_id) t2 on t1.stu_id =t2.stu_id;
-- 查询所有学生的学号、姓名、选课数、总成绩
select
stu.stu_id,stu.stu_name,count(s.course_id) count_course ,nvl(sum(s.score),0) total_score
from student stu left join score s on stu.stu_id = s.stu_id
group by stu.stu_id, stu.stu_name order by stu.stu_id;
-- 平均成绩大于 85 的所有学生的学号、姓名、平均成绩
select
stu.stu_id,stu.stu_name ,nvl(avg(s.score),0) as `avg_score`
from student stu left join score s on stu.stu_id = s.stu_id
group by stu.stu_id, stu.stu_name having nvl(avg(s.score),0) > 85 order by stu.stu_id
-- 查询学生的选课情况:学号,姓名,课程号,课程名称
select student.stu_id,student.stu_name,c.course_id,c.course_name from student
right join score s on student.stu_id = s.stu_id
left join course c on s.course_id = c.course_id
-- 查询学生的没有选课情况:学号,姓名
select stu_id,stu_name from
(
select student.stu_id,student.stu_name, s.course_id from student
left join score s on student.stu_id = s.stu_id
left join course c on s.course_id = c.course_id
) t where course_id is null
-- 查询出每门课程的及格人数和不及格人数
select c.course_id,course_name,pass,fail
from course c join
(
select
course_id,sum(if(score >= 60,1,0)) as `pass`, sum(if(score < 60,1,0)) as `fail`
from score group by course_id
) t on c.course_id = t.course_id
-- 查询课程编号为03且课程成绩在80分以上的学生的学号和姓名及课程信息
select t1.stu_id,s.stu_name,t1.course_id,c.course_name,t1.score from
(select * from score where course_id = '03' and score > 80) t1
left join student s on s.stu_id = t1.stu_id
left join course c on t1.course_id = c.course_id
-- 查询语文成绩低于平均分数的学生是谁,教师是谁
select t3.stu_id,t3.stu_name,t3.`avg_score`,t.tea_name from
(select t2.stu_id,t2.`avg_score`,s.stu_name,t2.course_id,c.tea_id from
(select t1.stu_id,t1.course_id,t1.`avg_score` from
(select stu_id,s.course_id, avg(score) as `avg_score` from score s right join
(select course_id from course where course_name = '语文') t1 on t1.course_id = s.course_id
group by stu_id,s.course_id) t1
where t1.`avg_score` < (select avg(score) as `avg_score` from score s right join (select course_id from course where course_name = '语文') t1 on t1.course_id = s.course_id)
) t2 left join student s on t2.stu_id = s.stu_id
left join course c on t2.course_id = c.course_id
)t3 left join teacher t on t3.tea_id = t.tea_id;
-- 查询所有学生总成绩和平均成绩,
-- 且他们的总成绩低于平均成绩的有多少个人,
-- 高于平均成绩的有多少人,
-- 低于平均成绩的男生和女生分别有多少人,
-- 且他们的任课老师是谁。
-- 统计各科成绩各分数段人数:课程编号,课程名称,[100-85],[85-70],[70-60],[0-60]及所占百分比
-- 方法一
select course_id,
concat(round((sum(`if`(score >= 85, 1, 0)) / count(*)) * 100, 2), '%') as `a`,
concat(round((sum(`if`(score < 85, `if`(score >= 70, 1, 0), 0)) / count(*)) * 100, 2), '%') as `b`,
concat(round((sum(`if`(score < 70, `if`(score >= 60, 1, 0), 0)) / count(*)) * 100, 2), '%') as `c`,
concat(round((sum(`if`(score < 60, 1, 0)) / count(*)) * 100, 2), '%') as `d`
from score group by course_id;
-- 方法二
select course_id,
concat(round((sum(`if`(score >= 85, 1, 0)) / count(*)) * 100, 2), '%') as `a`,
concat(round((sum(`if`(score between 70 and 84, 1, 0)) / count(*)) * 100, 2), '%') as `b`,
concat(round((sum(`if`(score between 60 and 74, 1, 0)) / count(*)) * 100, 2), '%') as `c`,
concat(round((sum(`if`(score < 60, 1, 0)) / count(*)) * 100, 2), '%') as `d`
from score group by course_id;
-- 查询各科成绩最高分、最低分和平均分,以如下形式显示:
-- 课程ID,课程name,最高分,最低分,平均分,及格率,中等率,优良率,优秀率
-- 及格为>=60,中等为:70-80,优良为:80-90,优秀为:>=90
select c.course_id as `课程ID`,
c.course_name as `课程name`,
max(score) as `最高分`,
min(score) as `最低分`,
round(avg(score), 2) as `平均分`,
concat(round(sum(`if`(score >= 60, 1, 0)) / count(*) * 100, 2), '%') as `及格率`,
concat(round(sum(if(score between 70 and 79, 1, 0)) / count(*) * 100, 2), '%') as `中等率`,
concat(round(sum(if(score between 80 and 89, 1, 0)) / count(*) * 100, 2), '%') as `优良率`,
concat(round(sum(`if`(score >= 90, 1, 0)) / count(*) * 100, 2), '%') as `优秀率`
from course c left join score s on c.course_id = s.course_id
group by c.course_id, c.course_name;
-- 查询每门课程的教师学生有谁,男生和女生的比例是多少,
select t1.course_id,t1.gender,concat(round((t1.count_gender / t2.count_course_student) * 100,2),'%') as `proportion` from
(
select c.course_id, stu.gender,count(stu.gender) as `count_gender`
from course c left join score s on c.course_id = s.course_id left join student stu on s.stu_id = stu.stu_id
group by c.course_id, stu.gender
) t1
join
(
select c.course_id, count(*) as `count_course_student`
from course c left join score s on c.course_id = s.course_id left join student stu on s.stu_id = stu.stu_id
group by c.course_id
) t2 on t1.course_id = t2.course_id
join score s on t1.course_id = s.course_id
-- 且他们的每门学科的成绩是男生比较优一些还是女生比较优一些,并且每门课程的最高分是谁。
select s.course_id,max(s.score) as `max_score`,min(s.score) as `min_score` from course join score s on course.course_id = s.course_id group by s.course_id
-- 课程编号为"01"且课程分数小于60,按分数降序排列的学生信息
select s.stu_id, stu.stu_name, stu.birthday, stu.gender,s.score
from score s join student stu on s.stu_id = stu.stu_id
where s.score < 60 order by s.score desc
-- 查询所有课程成绩在70分以上的学生的姓名、课程名称和分数,按分数升序
select stu.stu_name, c.course_name, s2.score
from student stu join
(select s.stu_id, sum(`if`(s.score >= 70, 0, 1)) as `is_ok` from score s group by s.stu_id having is_ok = 0) t1
on stu.stu_id = t1.stu_id left join score s2 on stu.stu_id = s2.stu_id left join course c on s2.course_id = c.course_id
order by s2.score
-- 查询某学生不同课程的成绩相同的学生编号、课程编号、学生成绩
select s1.stu_id,collect_list(s1.course_id) as course_id,collect_set(s1.score) as score
from score s1 join score s2 on s1.stu_id = s2.stu_id
and s1.course_id != s2.course_id
and s1.score == s2.score
group by s1.stu_id
-- 查询语文成绩低于平均分数的学生是谁,教师是谁
select stu.stu_name,tea_name from student stu left join score s left join course c left join teacher t where c.course_nam = "语文" and s.
-- 结合字符串函数 时间函数 流程控制函数 计算身份证信息
-- 根据身份证号 判断性别 身份证号 第十七位 奇数为男性 偶数为女性
select id_card, if(mod(substr(id_card,17,1),2) = 1,'精神小伙儿','扒蒜老妹儿') gender from person;
-- 根据身份证号 找出所有男性信息
select *, mod(substr(id_card,17,1),2) gender from person where mod(substr(id_card,17,1),2) = 1;
-- 根据身份证号 计算男性人数和女性人数
select
if(mod(substr(id_card,17,1),2) = 1,'精神小伙儿','扒蒜老妹儿') gender ,
count(*) gender_count
from person group by mod(substr(id_card,17,1),2) limit 10;
-- 根据身份证号 计算生日排序
select
date_format(from_unixtime( unix_timestamp(substr(id_card,7,8),'yyyyMMdd')),'yyyy-MM-dd') as `birthday`
from person
order by unix_timestamp(`birthday`,'yyyy-MM-dd') desc
-- 根据身份证号 计算年龄
-- 1、当前月份-出生月份 > 0 说明 已经过完生日 及 使用 当前年份 - 出生年份 = 年龄
-- 2、当前月份-出生月份 < 0 说明 未过生日 及 使用 当前年份 - 出生年份 -1 = 年龄
-- 3、当前月份-出生月份 = 0
-- 3.1、当前日-出生日 > 0 说明 已经过完生日 及 使用 当前年份 - 出生年份 = 年龄
-- 3.2、当前日-出生日 < 0 说明 未过生日 及 使用 当前年份 - 出生年份 -1 = 年龄
-- 3.3、当前日-出生日 = 0 说明 生日视作过完了 及 使用 当前年份 - 出生年份 = 年龄
select if(month(`current_date`()) - month(from_unixtime(unix_timestamp(substr(id_card, 7, 8), 'yyyyMMdd'))) > 0,
year(`current_date`()) - year(from_unixtime(unix_timestamp(substr(id_card, 7, 8), 'yyyyMMdd'))),
if(month(`current_date`()) - month(from_unixtime(unix_timestamp(substr(id_card, 7, 8), 'yyyyMMdd'))) < 0,
year(`current_date`()) - year(from_unixtime(unix_timestamp(substr(id_card, 7, 8), 'yyyyMMdd'))) - 1,
if(day(`current_date`()) - day(from_unixtime(unix_timestamp(substr(id_card, 7, 8), 'yyyyMMdd'))) > 0,
year(`current_date`()) - year(from_unixtime(unix_timestamp(substr(id_card, 7, 8), 'yyyyMMdd'))),
if(day(`current_date`()) - day(from_unixtime(unix_timestamp(substr(id_card, 7, 8), 'yyyyMMdd'))) < 0,
year(`current_date`()) - year(from_unixtime(unix_timestamp(substr(id_card, 7, 8), 'yyyyMMdd'))) - 1,
year(`current_date`()) - year(from_unixtime(unix_timestamp(substr(id_card, 7, 8), 'yyyyMMdd')))
)
)
)
) as `age`
from person;
高级聚合函数
分组排序取TopN
-- row_number() over () 连续序号
-- over()里头的分组以及排序的执行晚于 where 、group by、order by 的执行。
-- partition by 分区
select *,row_number() over () as `num` from score;
-- 查询各科成绩前三名的学生
SELECT a.stu_id,a.course_id,a.score
FROM score a
LEFT JOIN score b ON a.course_id = b.course_id
AND a.score <= b.score
GROUP BY a.stu_id,a.course_id,a.score
HAVING COUNT( b.stu_id ) <= 3
ORDER BY a.course_id,a.score DESC;
SELECT S1.course_id,s1.stu_id,s1.score FROM score s1
WHERE (
SELECT COUNT(*) FROM score s2
WHERE s2.course_id=s1.course_id AND s2.score > s1.score
) < 3 ORDER BY s1.course_id,s1.score DESC;
select * from
(
select course_id,stu_id,score,
row_number() over (partition by course_id order by score desc ) as `num`
from score
) t where t.num <= 3;
-- rank() over () 排名 跳跃排序 序号不是连续的
select * from
(
select course_id,stu_id,score,
rank() over (partition by course_id order by score desc ) as `ranking`
from score
) t;
-- dense_rank() over () 排名 连续排序
select * from
(
select course_id,stu_id,score,
dense_rank() over (partition by course_id order by score desc ) as `ranking`
from score
) t;
行列转换
-- 行转列
-- collect_list 行转列 有序可重复 结果是个集合
select collect_list(emp_job) as `job` from employee;
-- collect_set 行转列 过滤重复 结果是个集合
select collect_list(emp_job) as `job` from employee;
-- concat_ws 把集合转字符串
concat_ws('分隔符',集合)
select concat_ws(',',collect_set(emp_job)) as `job` from emp;
-- split 把字符串转为集合
concat_ws(字符串,'分隔符')
select split(concat_ws(',',collect_set(emp_job)))as `job` from emp;
-- 列转行
UDF,即用户定义函数(user-defined function),作用于单行数据,并且产生一个数据行作为输出。
Hive中大多数函数都属于这一类,比如数学函数和字符串函数。UDF函数的输入与输出值是1:1关系。
UDTF,即用户定义表生成函数(user-defined table-generating function),-- 又称炸裂函数
作用于单行数据,并且产生多个数据行。UDTF函数的输入与输出值是1:n的关系。UDAF,用户定义聚集函数(user-defined aggregate function),作用于多行数据,产生一个输出数据行。
Hive中像COUNT、MAX、MIN和SUM这样的函数就是聚集函数。UDAF函数的输入与输出值是n:1的关系。
雇员表 employee.csv
hdfs dfs -mkdir -p /quiz04/employee
hdfs dfs -put /root/employee.csv /quiz04/employee
create external table employee(
name string comment '姓名',
sex string comment '性别',
birthday string comment '出生年月',
hiredate string comment '入职日期',
job string comment '岗位',
salary int comment '薪资',
bonus int comment '奖金',
friends array<string> comment '朋友',
children map<string,int> comment '孩子'
)
row format delimited fields terminated by ','
collection items terminated by '_'
map keys terminated by ':'
lines terminated by '\n'
stored as textfile
location '/quiz04/employee';
load data local inpath '/root/employee.csv' into table employee;
UDTF
-- explode
select explode(array('java','python','scala','go')) as course;
select explode(map('name','李昊哲','gender','1')) as (key,value);
-- posexplode
select posexplode(array('java','python','scala','go')) as (pos,course);
-- inline
select inline(array(named_struct('id',1,'name','李昊哲','gender','1'),
named_struct('id',2,'name','李哲','gender','0'),
named_struct('id',3,'name','李大宝','gender','1'))) as (id,name,gender);
-- lateral view
select * from employee lateral view explode(friends) t as friend;
select e.name,e.friends,t1.friend from employee e lateral view explode(friends) t1 as `friend`;
select * from employee e lateral view explode(children) t1 as `children_name`,`children_friend_count`;
select e.name,e.children,t1.children_name,t1.nvl(t2.children_friend_count,0) from employee e
lateral view explode(children) t1 as `children_name`,`children_friend_count`;
select e.name,e.friends,e.children,t1.friend,t2.children_name,nvl(t2.children_friend_count,0) from employee e
lateral view explode(friends) t1 as `friend`
lateral view explode(children) t2 as `children_name`,`children_friend_count`;
-- lateral view outer
电影表 movie.txt
hdfs dfs -mkdir -p /quiz04/movie
hdfs dfs -put /root/movie.txt /quiz04/movie
create external table movie(
name string comment '电影名称',
category string comment '电影分类'
)
row format delimited fields terminated by '-'
lines terminated by '\n'
stored as textfile
location '/quiz04/movie';
load data local inpath '/root/movie.txt' into table movie;
UDTF 案例
-- 根据上述电影信息表,统计各分类的电影数量
select cate,count(name) as `quantity` from movie
lateral view explode(split(category,',')) tmp as cate
group by cate;
分组和去重
-- 统计岗位数量
select count(distinct emp_job) from emp;
select count(*) from (select emp_job from emp group by emp_job) t;
开窗函数
能为每行数据划分一个窗口,然后对窗口范围内的数据进行计算,最后将计算结果返回给该行
什么是开窗函数,
开窗函数(Window Function)是在 SQL 中用于对分组数据执行聚合函数过程的函数。开窗函数可以将结果分成分组集合,并逐个分组进行计算,而不是标准聚合函数计算全部数据。
开窗函数可以按照窗口大小(范围)对行数据进行分组,并对每个子组执行聚合计算。它们在 SELECT 和 ORDER BY 子句中使用,且不能单独使用。在使用开窗函数时需要与 OVER 子句一起使用,以便定义子分组。 下面是一些常见的开窗函数:
-
ROW_NUMBER():分配连续的整数行号给查询结果集中的每一行。 -
ROWNUM:Oracle 中类似 ROW_NUMBER() 函数的行号函数,不过在语法上有所不同。 -
RANK():计算等级。相同数据的等级是一样的,假如有3个人考了同样的分数,他们的排名应该是并列第一,第四个人的排名则应是第四。 -
DENSE_RANK():计算等级,此函数不会像前面的 RANK 函数一样跳过重复项,而是把他们放在同一个等级里。 -
LEAD( ):返回当前行后的指定行数的值。 -
LAG(): 返回当前行前的指定行数的值。 -
FIRST_VALUE():返回窗口或分组的第一行对应的值。 -
LAST_VALUE():返回窗口或分组的最后一行对应的值。 -
SUM() OVER():计算窗口或分组的总和。 -
AVG() OVER():计算窗口或分组的平均值。 -
MIN() OVER():计算窗口或分组的最小值 -
MAX() OVER():计算窗口或分组的最大值。
Function(arg1,..., argn) OVER ([PARTITION BY <...>] [ORDER BY <....>] [<window_expression>])
-- 其中Function(arg1,..., argn) 可以是下面分类中的任意一个
-- 聚合函数:比如sum max min avg count等
-- 排序函数:比如row_number rank dense_rank等
-- 分析函数:比如lead lag first_value last_value等
-- OVER [PARTITION BY <...>] 类似于group by 用于指定分组 每个分组你可以把它叫做窗口
-- 如果没有PARTITION BY 那么整张表的所有行就是一组
-- [ORDER BY <....>] 用于指定每个分组内的数据排序规则 支持ASC、DESC
-- [<window_expression>] 用于指定每个窗口中 操作的数据范围 默认是窗口中所有行
hdfs dfs -mkdir /quiz04/order
hdfs dfs -put /root/order.csv /quiz04/order
create external table `order`
(
order_id string comment '订单id',
user_id string comment '用户id',
user_name string comment '用户姓名',
order_date string comment '下单日期',
order_amount int comment '订单金额'
)
row format delimited fields terminated by ','
lines terminated by '\n'
stored as textfile
location '/quiz04/order';
聚合函数
rows 基于行
range 基于值
函数() over(rows between and 3)
- unbounded preceding 表示从前面的起点
- number preceding 往前
- current row 当前行
- number following 往后
- unbounded following 表示到后面的终点
load data local inpath '/root/order.csv' into table order;
-- 统计每个用户截至每次下单的累计下单总额
select *,
sum(order_amount) over
(partition by user_id order by order_date rows between unbounded preceding and current row) `sum_order_amount`
from `order`
-- 统计每个用户截至每次下单的当月累积下单总额
select *,
sum(order_amount)
over(partition by user_id,substr(order_date,1,7) order by order_date
rows between unbounded preceding and current row) `sum_order_amount`
from `order`
跨行取值
lead lag
-- 统计每个用户每次下单距离上次下单相隔的天数(首次下单按0天算)
select user_id,user_name,order_id,order_date,datediff(order_date,last_order_date) `diff_date` from
(select *,
lag(order_date,1,order_date) over (partition by user_id order by order_date) `last_order_date` from order`) t
first_value last_value
-- 查询所有下单记录以及每个用户的每个下单记录所在月份的首/末次下单日期
select *,
first_value(order_date) over(partition by user_id,substr(order_date,1,7) order by order_date) `first_date`,
last_value(order_date) over (partition by user_id,substr(order_date,1,7) order by order_date
rows between unbounded preceding and unbounded following) `last_date`
from `order`
分组排序TopN
-- 为每个用户的所有下单记录按照订单金额进行排名
综合练习
准备数据
用户信息表 user.csv
hdfs dfs -mkdir -p /tmall/user
hdfs dfs -put /root/user.csv /tmall/user
create external table `user` (
`user_id` string COMMENT '用户id',
`gender` string COMMENT '性别',
`birthday` string COMMENT '生日'
) COMMENT '用户信息表'
row format delimited fields terminated by ','
lines terminated by '\n'
stored as textfile
location '/tmall/user';
load data local inpath '/root/user.csv' into table user;
商品信息表 sku.csv
hdfs dfs -mkdir -p /tmall/sku
hdfs dfs -put /root/sku.csv /tmall/sku
create external table sku (
`sku_id` string COMMENT '商品id',
`name` string COMMENT '商品名称',
`category_id` string COMMENT '所属分类id',
`from_date` string COMMENT '上架日期',
`price` double COMMENT '商品单价'
) COMMENT '商品信息表'
row format delimited fields terminated by ','
lines terminated by '\n'
stored as textfile
location '/tmall/sku';
load data local inpath '/root/sku.csv' into table sku;
商品分类信息表 category.csv
hdfs dfs -mkdir -p /tmall/category
hdfs dfs -put /root/category.csv /tmall/category
create external table category (
`category_id` string COMMENT '商品分类ID',
`category_name` string COMMENT '商品分类名称'
) COMMENT '商品分类信息表'
row format delimited fields terminated by ','
lines terminated by '\n'
stored as textfile
location '/tmall/category';
load data local inpath '/root/category.csv' into table category;
订单信息表 order.csv
hdfs dfs -mkdir -p /tmall/order
hdfs dfs -put /root/order.csv /tmall/order
create external table `order` (
`order_id` string COMMENT '订单id',
`user_id` string COMMENT '用户id',
`create_date` string COMMENT '下单日期',
`total_amount` decimal(16, 2) COMMENT '订单总金额'
) COMMENT '订单信息表'
row format delimited fields terminated by ','
lines terminated by '\n'
stored as textfile
location '/tmall/order';
load data local inpath '/root/order.csv' into table order;
订单明细表 order_detail.csv
hdfs dfs -mkdir -p /tmall/order_detail
hdfs dfs -put /root/order_detail.csv /tmall/order_detail
create external table order_detail (
`order_detail_id` string COMMENT '订单明细id',
`order_id` string COMMENT '订单id',
`sku_id` string COMMENT '商品id',
`create_date` string COMMENT '下单日期',
`price` decimal(16, 2) COMMENT '下单时的商品单价',
`sku_num` int COMMENT '下单商品件数'
) COMMENT '订单明细表'
row format delimited fields terminated by ','
lines terminated by '\n'
stored as textfile
location '/tmall/order_detail';
load data local inpath '/root/order_detail.csv' into table order_detail;
登录明细表 user_login.csv
hdfs dfs -mkdir -p /tmall/user_login
hdfs dfs -put /root/user_login.csv /tmall/user_login
create external table user_login (
`user_id` string comment '用户id',
`ip_address` string comment 'ip地址',
`login_ts` string comment '登录时间',
`logout_ts` string comment '登出时间'
) COMMENT '登录明细表'
row format delimited fields terminated by ','
lines terminated by '\n'
stored as textfile
location '/tmall/user_login';
load data local inpath '/root/user_login.csv' into table user_login;
商品价格变更明细 user.csv
hdfs dfs -mkdir -p /tmall/sku_price_modify_detail
hdfs dfs -put /root/sku_price_modify_detail.csv /tmall/sku_price_modify_detail
create external table sku_price_modify_detail (
`sku_id` string comment '商品id',
`new_price` decimal(16, 2) comment '更改后的价格',
`change_date` string comment '变动日期'
) COMMENT '商品价格变更明细表'
row format delimited fields terminated by ','
lines terminated by '\n'
stored as textfile
location '/tmall/sku_price_modify_detail';
load data local inpath '/root/sku_price_modify_detail.csv' into table sku_price_modify_detail;
配送信息表 user.csv
hdfs dfs -mkdir -p /tmall/delivery
hdfs dfs -put /root/delivery.csv /tmall/delivery
create external table delivery (
`delivery_id` string comment '配送单id',
`order_id` string comment '订单id',
`user_id` string comment '用户id',
`order_date` string comment '下单日期',
`custom_date` string comment '期望配送日期'
) COMMENT '配送信息表'
row format delimited fields terminated by ','
lines terminated by '\n'
stored as textfile
location '/tmall/delivery';
load data local inpath '/root/delivery.csv' into table delivery;
好友关系表 user.csv
hdfs dfs -mkdir -p /tmall/friendship
hdfs dfs -put /root/friendship.csv /tmall/friendship
create external table friendship (
`user_id` string comment '用户id',
`firend_id` string comment '好友id'
) COMMENT '好友关系表'
row format delimited fields terminated by ','
lines terminated by '\n'
stored as textfile
location '/tmall/friendship';
load data local inpath '/root/friendship.csv' into table friendship;
收藏信息表 favor.csv
hdfs dfs -mkdir -p /tmall/favor
hdfs dfs -put /root/favor.csv /tmall/favor
create external table favor (
`user_id` string comment '用户id',
`sku_id` string comment '商品id',
`create_date` string comment '收藏日期'
) COMMENT '收藏信息表'
row format delimited fields terminated by ','
lines terminated by '\n'
stored as textfile
location '/tmall/favor';
load data local inpath '/root/favor.csv' into table favor;
练习题目
-- 查询订单明细表(order_detail)中销量(下单件数)排名第二的商品id,不存在返回null,存在多个排名第二的商品则需要全部返回
select t2.sku_id from
(select t1.sku_id,dense_rank() over (order by t1.sum_sku desc) ranking from
(select sku_id ,sum(sku_num) sum_sku from order_detail group by sku_id) t1
) t2 where t2.ranking = 2;
-- 查询订单信息表(order)中最少连续3天下单的用户id
select t2.user_id from
(select t1.user_id
,lag(t1.create_date,1,t1.create_date) over (partition by t1.user_id order by t1.create_date) day01
,lead(t1.create_date,1,t1.create_date) over (partition by t1.user_id order by t1.create_date) day03
from
(select user_id,create_date from `order` group by user_id, create_date) t1 -- 相同用户在同一天下单视为一条记录
)t2 where datediff(day03,day01) = 2 group by t2.user_id;
-- 从订单明细表(order_detail)统计各品类销售出的商品种类数及累积销量最好的商品
select t2.category_id,t2.category_name,t2.sku_id,t2.name,t2.sum_sku_num,
rank() over (order by t2.sum_sku_num desc) ranking
from
(select
t1.category_id,t1.category_name,t1.sku_id,t1.name,t1.sum_sku_num,
rank() over (partition by t1.category_id order by t1.sum_sku_num desc) ranking
from
(select c.category_id,c.category_name,od.sku_id,s.name ,sum(od.sku_num) sum_sku_num from order_detail od
left join sku s on od.sku_id = s.sku_id
left join category c on s.category_id = c.category_id
group by c.category_id, c.category_name, od.sku_id,s.name
) t1) t2 where t2.ranking = 1;
-- 从订单信息表(order)中统计每个用户截止其每个下单日期的累积消费金额,以及每个用户在其每个下单日期的VIP等级
-- 用户vip等级根据累积消费金额计算,计算规则如下:
-- 设累积消费总额为X,
-- 若0=<X<10000,则vip等级为普通会员
-- 若10000<=X<30000,则vip等级为青铜会员
-- 若30000<=X<50000,则vip等级为白银会员
-- 若50000<=X<80000,则vip为黄金会员
-- 若80000<=X<100000,则vip等级为白金会员
-- 若X>=100000,则vip等级为钻石会员
select t2.user_id,t2.create_date,t2.total_amount_day,
case
when t2.total_amount_month >= 100000 then '钻石会员'
when t2.total_amount_month >= 80000 then '白金会员'
when t2.total_amount_month >= 50000 then '黄金会员'
when t2.total_amount_month >= 30000 then '白银会员'
when t2.total_amount_month >= 10000 then '青铜会员'
when t2.total_amount_month >= 0 then '黑铁会员'
end vip_level
from
(select t1.user_id,t1.create_date,t1.total_amount_day,
sum(t1.total_amount_day) over (partition by t1.user_id order by t1.create_date) total_amount_month
from
(select user_id,create_date,sum(total_amount) total_amount_day from `order`
group by user_id,create_date
) t1) t2;
-- 从订单信息表(order)中查询首次下单后第二天仍然下单的用户占所有下单用户的比例,结果保留一位小数,使用百分数显示
select concat(round(t4.count_order_user / (select count(*) from `user`) * 100,1),'%') order_user_percent from
(select size(collect_set(t3.user_id)) count_order_user from
(select t2.user_id,t2.create_date,t2.next_day from
(select t1.user_id,t1.create_date,
lead(t1.create_date,1,t1.create_date) over (partition by t1.user_id order by t1.create_date) next_day
from (select user_id,create_date from `order` group by user_id,create_date) t1
) t2 where datediff(t2.next_day,t2.create_date) = 1) t3) t4;
-- 从订单明细表(order_detail)统计每个商品销售首年的年份、销售数量和销售总额
select distinct t2.sku_id ,t2.first_create_date,
sum(sku_num) over (partition by sku_id) sum_sku_num,
sum(price * sku_num) over (partition by sku_id) total_amount
from
(select t1.sku_id ,t1.first_create_date,t1.price,t1.sku_num
from
(select sku_id,create_date,price,sku_num,
first_value(create_date) over (partition by sku_id order by create_date) first_create_date
from order_detail) t1
where year(t1.create_date) = year(t1.first_create_date)
) t2;
-- 从订单明细表(order_detail)中筛选去年总销量小于100的商品及其销量,设今天的日期是2022-01-10,不考虑上架时间小于一个月的商品
select t1.sku_id,t2.name,t1.total_sku_num
from
(select sku_id,sum(sku_num) total_sku_num from order_detail where year(create_date) = year('2022-01-11') - 1
group by sku_id having total_sku_num < 100 ) t1
left join (select sku_id,name from sku where datediff('2022-01-10',from_date) > 30) t2
on t1.sku_id = t2.sku_id
-- 从用户登录明细表(user_login)中查询每天的新增用户数,
-- 若一个用户在某天登录了,且在这一天之前没登录过,则认为该用户为这一天的新增用户
select t1.first_date_login,count(*) from (select user_id,
min(date_format(login_ts,'yyyy-MM-dd')) first_date_login
from user_login group by user_id
) t1 group by t1.first_date_login;
-- 从订单明细表(order_detail)中统计出每种商品销售件数最多的日期及当日销量,如果有同一商品多日销量并列的情况,取其中的最小日期
select t2.sku_id,t2.create_date,t2.sum_sku_num
from (select t1.sku_id,t1.create_date,t1.sum_sku_num,
row_number() over (partition by t1.sku_id order by t1.sum_sku_num) number
from
(select sku_id,create_date,sum(sku_num) sum_sku_num
from order_detail group by sku_id, create_date) t1) t2
where t2.number = 1;
-- 从订单明细表(order_detail)中查询累积销售件数高于其所属品类平均数的商品
select t3.sku_id,t3.name,t3.category_id,t3.sum_sku_num,t3.avg_cate_num from
(select t1.sku_id,t2.name,t2.category_id,t1.sum_sku_num,avg(sum_sku_num) over (partition by category_id) avg_cate_num
from
(select sku_id,sum(sku_num) sum_sku_num from order_detail group by sku_id) t1
left join
(select sku_id,name,category_id from sku)t2 on t1.sku_id = t2.sku_id) t3
where t3.sum_sku_num > t3.avg_cate_num;
-- 从用户登录明细表(user_login)和订单信息表(order)中
-- 查询每个用户的注册日期(首次登录日期)、总登录次数以及其在2021年的登录次数、订单数和订单总额
select t1.user_id,t1.first_login_date,t2.total_login,t3.count_order,t3.total_amount from
(select user_id,min(login_ts) first_login_date from user_login group by user_id) t1
left join
(select user_id,count(login_ts) total_login from user_login group by user_id) t2
on t1.user_id = t2.user_id
left join
(select user_id,count(*) count_order,sum(total_amount) total_amount from `order` where year(create_date) = 2021 group by user_id) t3
on t2.user_id = t3.user_id;
-- 从商品价格修改明细表(sku_price_modify_detail)中查询2021-10-01的全部商品的价格,假设所有商品初始价格默认都是99
select * from sku_price_modify_detail where change_date = '2021-10-01';
-- 订单配送中,如果期望配送日期和下单日期相同,称为即时订单,如果期望配送日期和下单日期不同,称为计划订单。
-- 从配送信息表(delivery)中求出每个用户的首单(用户的第一个订单)中即时订单的比例,保留两位小数,以小数形式显示
select round(sum(`if`(custom_date = order_date,1,0))/count(*) ,2) percent from
(select *,row_number() over (partition by user_id order by order_date) num from delivery) t1
where num = 1;
-- 现需要请向所有用户推荐其朋友收藏但是用户自己未收藏的商品,
-- 从好友关系表(friendship)和收藏表(favor)中查询出应向哪位用户推荐哪些商品
select t1.user_id,collect_set(firend_favor.sku_id) from (
select user_id,friend_id from friendship
union
select friend_id,user_id from friendship
) t1 left join favor firend_favor on t1.friend_id = firend_favor.user_id
left join favor my_favor on t1.user_id = firend_favor.user_id
and firend_favor.sku_id = my_favor.sku_id
where my_favor.sku_id is null
group by t1.user_id
-- 从登录明细表(user_login)中查询出,所有用户的连续登录两天及以上的日期区间,以登录时间(login_ts)为准
select t3.user_id,min(pre_login_date) start_date,max(login_date) end_date from
(select * from (select user_id,login_date,
lag(login_date,1,login_date) over (partition by user_id order by login_date) pre_login_date
from (select user_id,date_format(login_ts,'yyyy-MM-dd') login_date
from user_login group by user_id,date_format(login_ts,'yyyy-MM-dd')) t1
) t2 where datediff(login_date,pre_login_date) = 1
) t3 group by t3.user_id;
-- 从订单信息表(order)和用户信息表(user)中,
-- 分别统计每天男性和女性用户的订单总金额,如果当天男性或者女性没有购物,则统计结果为0
select o.create_date,
sum(`if`(gender = '男',o.total_amount,0)) male_total_amount,
sum(`if`(gender = '女',o.total_amount,0)) female_total_amount
from `order` o
left join `user` u on o.user_id = u.user_id
group by o.create_date;
-- 查询截止每天的最近3天内的订单金额总和以及订单金额日平均值,保留两位小数,四舍五入
select t1.create_date,
round(sum(t1.total_amount) over (order by t1.create_date rows between 2 preceding and current row ),2) total_3d,
round(avg(t1.total_amount) over (order by t1.create_date rows between 2 preceding and current row ),2) avg_3d
from
(select create_date,sum(total_amount) total_amount from `order` group by create_date) t1;
-- 从订单明细表(order_detail)中查询出所有购买过商品1和商品2,但是没有购买过商品3的用户
select o.user_id,collect_set(od.sku_id) sku_ids from order_detail od left join `order` o
on od.order_id = o.order_id
group by o.user_id
having array_contains(sku_ids,'1') and array_contains(sku_ids,'2') and !array_contains(sku_ids,'3');
select t1.user_id from
(select o.user_id,collect_set(od.sku_id) sku_ids from order_detail od left join `order` o
on od.order_id = o.order_id
group by o.user_id) t1
where array_contains(sku_ids,'1') and array_contains(sku_ids,'2') and !array_contains(sku_ids,'3')
-- 从订单明细表(order_detail)中统计每天商品1和商品2销量(件数)的差值(商品1销量-商品2销量)
select create_date,
(sum(`if`(sku_id = '1',sku_num,0)) - sum(`if`(sku_id = '2',sku_num,0))) sku_num_diff
from order_detail group by create_date
-- 从订单信息表(order)中查询出每个用户的最近三笔订单
select * from
(select *,row_number() over (partition by user_id order by create_date desc) ranking from `order`) t1
where ranking < 4;
-- 从登录明细表(user_login)中查询每个用户两个登录日期(以login_ts为准)之间的最大的空档期。
-- 统计最大空档期时,用户最后一次登录至今的空档也要考虑在内,假设今天为2021-10-10
select t2.user_id, max(datediff(t2.next_login_date,t2.login_date)) max_gap_period from
(select t1.user_id,t1.login_date,
lead(t1.login_date,1,'2021-10-10') over (partition by t1.user_id order by t1.login_date) next_login_date
from
(select user_id,date_format(login_ts,'yyyy-MM-dd') login_date from user_login) t1) t2
group by t2.user_id
-- 从登录明细表(user_login)用户最后一次登录至今的空档期限,
-- 分级推荐
-- 一年以上 A级
-- 半年以上 B级
-- 3到6个月 C级
-- 1到3个月 D级
-- 一周以上 E级
-- 一周以下 F级
select t1.user_id,gap_period,
case
when gap_period > 365 then 'A'
when gap_period > 182 then 'B'
when gap_period > 91 then 'C'
when gap_period > 30 then 'D'
when gap_period > 7 then 'E'
else 'F'
end level
from (select user_id,datediff(date_sub(`current_date`(),500),date_format(max(login_ts),'yyyy-MM-dd')) gap_period
from user_login group by user_id) t1;
-- 从登录明细表(user_login)中查询在相同时刻,多地登陆(ip_address不同)的用户
select user_id, date_format(login_ts,'yyyy-MM-dd') login_date from user_login
group by user_id, date_format(login_ts,'yyyy-MM-dd')
having size(collect_set(ip_address)) > 1;
-- 商家要求每个商品每个月需要售卖出一定的销售总额
-- 假设1号商品销售总额大于21000,2号商品销售总额大于10000,其余商品没有要求
-- 写出SQL从订单详情表中(order_detail)查询连续两个月销售总额大于等于任务总额的商品
select t6.sku_id,date_month,date_amount from
(select t4.sku_id,t5.create_month
from (select t3.sku_id,t3.amount_map from
(select t2.sku_id,collect_list(map(t2.ymd,t2.total_amount)) amount_map
from
(select t1.sku_id,t1.ymd,t1.total_amount
from
(select sku_id,date_format(create_date,'yyyy-MM') ymd,sum(price * sku_num) total_amount
from order_detail where sku_id in ('1','2')
group by sku_id ,date_format(create_date,'yyyy-MM')
having (sku_id = '1' and total_amount > 21000)
or (sku_id = '2' and total_amount > 10000)
) t1
)
t2 group by t2.sku_id)
t3 where size(t3.amount_map) > 1) t4
lateral view explode(t4.amount_map) t5 as create_month) t6
lateral view explode(t6.create_month) t5 as date_month,date_amount;
-- 从订单详情表中(order_detail)对销售件数对商品进行分类,
-- 0-5000为冷门商品,5001-19999位一般商品,20000往上为热门商品,并求出不同类别商品的数量
select t2.category, count(*) total
from (select t1.sku_id,
case
when t1.total_num between 0 and 5000 then '冷门商品'
when t1.total_num between 5001 and 19999 then '一般商品'
else '热门商品'
end category
from (select sku_id, sum(sku_num) total_num from order_detail group by sku_id) t1) t2
group by t2.category;
-- 从订单详情表中(order_detail)和商品(sku)中查询各个品类销售数量前三的商品。
select t2.category_id,t2.sku_id from (select sku.category_id,t1.sku_id,
rank() over (partition by sku.category_id order by t1.total_sku_num desc ) ranking
from
(select sku_id,sum(sku_num) as total_sku_num from order_detail group by sku_id) t1
left join sku on t1.sku_id = sku.sku_id) t2 where t2.ranking < 4;
-- 从订单详情表(order_detail)中找出销售额连续3天超过100的商品
select t3.sku_id,t3.create_date,t3.amount from
(select t2.sku_id,t2.create_date,t2.amount,
count(*) over (partition by t2.sku_id,t2.reference) count_reference
from
(select t1.sku_id,t1.create_date,t1.amount,
date_sub(t1.create_date,row_number() over (partition by t1.sku_id order by t1.create_date)) reference
from
(select sku_id ,create_date,sum(price * sku_num) amount from order_detail
group by sku_id ,create_date having amount > 100) t1
) t2
) t3 where t3.count_reference > 2 order by t3.sku_id,t3.create_date;
-- 从用户登录明细表(user_login_detail)中首次登录算作当天新增,第二天也登录了算作一日留存
-- 新增用户数量 第二日留存数量 第二日登录的留存率
select *,round(t2.count_next_day_login / t2.count_register,2) retention_rate from
(select t1.first_login_date,count(t1.user_id) count_register, count(ul.user_id) count_next_day_login from
(select user_id,date_format(min(login_ts),'yyyy-MM-dd') first_login_date from user_login group by user_id) t1
left join user_login ul on t1.user_id = ul.user_id
and datediff(date_format(login_ts,'yyyy-MM-dd'),t1.first_login_date) = 1
group by t1.first_login_date) t2;
-- 从订单详情表(order_detail)中,求出商品连续售卖的时间区间
select t1.sku_id,min(t1.create_date) start_date,max(t1.create_date) end_date from
(select sku_id,create_date,date_sub(create_date,row_number() over (partition by sku_id order by create_date)) reference
from order_detail group by sku_id,create_date) t1
group by t1.sku_id,t1.reference;
-- 分别从登陆明细表(user_login)和配送信息表(delivery)中每天用户登录时间和下单时间统计登陆次数和交易次数
select t1.user_id, t1.login_date, t1.count_login, nvl(count_consumption,0) count_consumption
from (select user_id, date_format(login_ts, 'yyyy-MM-dd') login_date, count(*) count_login
from user_login
group by user_id, date_format(login_ts, 'yyyy-MM-dd')) t1
left join
(select user_id, create_date date_consumption, count(*) count_consumption
from `order`
group by user_id, create_date) t2
on t1.user_id = t2.user_id and t1.login_date = t2.date_consumption;
-- 从订单明细表(order_detail)中列出每个商品每个年度的购买总额
select sku_id,date_format(create_date,'yyyy') every_year,sum(price * sku_num) total_amount
from order_detail group by sku_id,date_format(create_date,'yyyy');
-- 从订单详情表(order_detail)中查询2021年9月27号-2021年10月3号这一周所有商品每天销售情况
select sku_id,
sum(`if`(`dayofweek`(create_date) - 1 = 1,sku_num,0)) Monday,
sum(`if`(`dayofweek`(create_date) - 1 = 2,sku_num,0)) Tuesday,
sum(`if`(`dayofweek`(create_date) - 1 = 3,sku_num,0)) Wednesday,
sum(`if`(`dayofweek`(create_date) - 1 = 4,sku_num,0)) Thursday,
sum(`if`(`dayofweek`(create_date) - 1 = 5,sku_num,0)) Friday,
sum(`if`(`dayofweek`(create_date) - 1 = 6,sku_num,0)) Saturday,
sum(`if`(`dayofweek`(create_date) - 1 = 0,sku_num,0)) Sunday
from order_detail where create_date between '2021-09-27' and '2021-10-03' group by sku_id;
-- 从商品价格变更明细表(sku_price_modify_detail),得到最近一次价格的涨幅情况,并按照涨幅升序排序
select t1.sku_id,t1.change_date,t1.new_price,t1.increase from (select sku_id,change_date,new_price,
new_price - nvl(lag(new_price) over (partition by sku_id order by change_date),new_price) increase,
rank() over (partition by sku_id order by change_date desc) ranking
from sku_price_modify_detail) t1 where ranking = 1 order by t1.increase;
-- 通过商品信息表(sku)订单信息表(order)订单明细表(order_detail)分析
-- 如果有一个用户成功下单两个及两个以上的购买成功的手机订单(购买商品为xiaomi 10,apple 12,xiaomi 13)
-- 那么输出这个用户的id及第一次成功购买手机的日期和第二次成功购买手机的日期,以及购买手机成功的次数
select t2.user_id,t2.first_date, t2.date_of_second,t2.count_purchases from
(select t1.user_id,t1.create_date date_of_second,
first_value(t1.create_date) over (partition by t1.user_id order by t1.create_date) first_date,
dense_rank() over (partition by t1.user_id order by t1.order_id) ranking,
count(distinct t1.order_id) over (partition by t1.user_id) count_purchases
from (select o.user_id,o.create_date,o.order_id,s.name
from `order` o
left join order_detail od on `o`.order_id = od.order_id
left join sku s on od.sku_id = s.sku_id
)t1 where t1.name in ('xiaomi 10','apple 12','xiaomi 13')
) t2 where t2.ranking = 2;
-- 从订单明细表(order_detail)中,求出同一个商品在2020年和2021年中同一个月的售卖情况对比
select nvl(t2020.sku_id,t2021.sku_id) sku_id,
`if`(month(t2020.m) - month(t2021.m) > 0,
month(t2021.m) ,
month(t2020.m)) m,
nvl(t2020.sku_sum,0) sku_num_2020,
nvl(t2021.sku_sum,0) sku_num_2021
from
(select sku_id, concat(date_format(create_date,'yyyy-MM') ,'-01') m,
sum(sku_num) sku_sum
from order_detail
where year(create_date) = 2020
group by sku_id,date_format(create_date,'yyyy-MM')
) t2020
full join
(select sku_id, concat(date_format(create_date,'yyyy-MM') ,'-01') m,
sum(sku_num) sku_sum
from order_detail
where year(create_date) = 2021
group by sku_id,date_format(create_date,'yyyy-MM')
) t2021
where t2020.sku_id = t2021.sku_id;
-- 从订单明细表(order_detail)和收藏信息表(favor)统计2021国庆期间,每个商品总收藏量和购买量
select nvl(o.sku_id,f.sku_id) sku_id,sku_num,fav from
(select sku_id,sum(sku_num) sku_num from order_detail
where create_date between '2021-10-01' and '2021-10-07' group by sku_id) o
full join
(select sku_id,count(*) fav from favor where create_date < '2021-10-8' group by sku_id) f
on f.sku_id = o.sku_id
-- 假设今天是数据中所有日期的最大值,从用户登录明细表中的用户登录时间给各用户分级,求出各等级用户的人数
-- 用户等级:
-- 忠实用户:近7天活跃且非新用户
-- 新晋用户:近7天新增
-- 沉睡用户:近7天未活跃但是在7天前活跃
-- 流失用户:近30天未活跃但是在30天前活跃
select t.level level, count(*) count_user from
(select ul.user_id,
case
when datediff(today, date_format(max(login_ts), 'yyyy-MM-dd')) >= 30 then '流失用户'
when datediff(today, date_format(max(login_ts), 'yyyy-MM-dd')) >= 7 and
datediff(today, date_format(max(login_ts), 'yyyy-MM-dd')) < 30 then '沉睡用户'
when datediff(today, date_format(min(login_ts), 'yyyy-MM-dd')) < 7 then '新晋用户'
when datediff(today, date_format(min(login_ts), 'yyyy-MM-dd')) > 7 and
datediff(today, date_format(max(login_ts), 'yyyy-MM-dd')) < 7 then '忠实用户'
end level
from user_login ul
join
(select date_format(max(login_ts), 'yyyy-MM-dd') today from user_login) ref
group by ul.user_id,today
) t group by t.level;
-- 用户每天签到可以领1金币,并可以累计签到天数,连续签到的第3、7天分别可以额外领2和6金币。
-- 每连续签到7天重新累积签到天数。从用户登录明细表中求出每个用户金币总数,并按照金币总数倒序排序
select t3.user_id,sum(t3.gold) total_gold from (select t2.user_id,
max(t2.count_login) + sum(`if`(t2.count_login % 3 = 0,2,0)) + sum(`if`(t2.count_login % 7 = 0,6,0)) gold
from
(select t1.user_id,t1.login_date,
date_sub(login_date,t1.num) ref,
count(*) over(partition by user_id,date_sub(login_date,t1.num) order by t1.login_date) count_login
from
(select user_id,date_format(login_ts,'yyyy-MM-dd') login_date,
row_number() over (partition by user_id order by date_format(login_ts,'yyyy-MM-dd')) num
from user_login group by user_id,date_format(login_ts,'yyyy-MM-dd')
) t1
) t2 group by t2.user_id,ref
) t3 group by t3.user_id order by total_gold desc;
-- 动销率定义为品类商品中一段时间内有销量的商品占当前已上架总商品数的比例(有销量的商品/已上架总商品数)。
-- 滞销率定义为品类商品中一段时间内没有销量的商品占当前已上架总商品数的比例。(没有销量的商品 / 已上架总商品数)。
-- 只要当天任一店铺有任何商品的销量就输出该天的结果
-- 从订单明细表(order_detail)和商品信息表(sku)表中求出国庆7天每天每个品类的商品的动销率和滞销率
select t4.category_id,
t3.day01 / count_shelf day01_mr,
(count_shelf - t3.day01) / count_shelf day01_ar,
t3.day02 / count_shelf day02_mr,
(count_shelf - t3.day02) / count_shelf day02_ar,
t3.day03 / count_shelf day03_mr,
(count_shelf - t3.day03) / count_shelf day03_ar,
t3.day04 / count_shelf day04_mr,
(count_shelf - t3.day04) / count_shelf day04_ar,
t3.day05 / count_shelf day05_mr,
(count_shelf - t3.day05) / count_shelf day05_ar,
t3.day06 / count_shelf day06_mr,
(count_shelf - t3.day06) / count_shelf day06_ar,
t3.day07 / count_shelf day07_mr,
(count_shelf - t3.day07) / count_shelf day07_ar
from
(select t2.category_id,
sum(`if`(t2.create_date = '2021-10-01',1,0)) day01,
sum(`if`(t2.create_date = '2021-10-02',1,0)) day02,
sum(`if`(t2.create_date = '2021-10-03',1,0)) day03,
sum(`if`(t2.create_date = '2021-10-04',1,0)) day04,
sum(`if`(t2.create_date = '2021-10-05',1,0)) day05,
sum(`if`(t2.create_date = '2021-10-06',1,0)) day06,
sum(`if`(t2.create_date = '2021-10-07',1,0)) day07
from
(select distinct t1.category_id,t1.create_date,t1.name from
(select s.category_id,od.create_date,s.name
from order_detail od join sku s on od.sku_id = s.sku_id
) t1 where t1.create_date between '2021-10-01' and '2021-10-07'
) t2 group by t2.category_id
) t3
join
(select category_id,count(*) count_shelf from sku group by category_id) t4
on t3.category_id = t4.category_id;
-- 根据用户登录明细表(user_login),求出平台同时在线最多的人数
select
max(sum_l_time)
from
(
select
sum(flag)over(order by t1.l_time) sum_l_time
from
(
select
login_ts l_time,
1 flag
from
user_login
union
select
logout_ts l_time,
-1 flag
from
user_login
)t1
)t2;
分区表
模拟数据
身份证前六位
身份证前六位
110101,110102,110103,110104,110105,110106,110107,110108,110109,110111,110112,110113,110114,110224,110226,110227,110228,110229,120101,120102,120103,120104,120105,120106,120107,120108,120109,120110,120111,120112,120113,120114,120221,120223,120224,120225,130101,130102,130103,130104,130105,130106,130107,130121,130123,130124,130125,130126,130127,130128,130129,130130,130131,130132,130133,130181,130182,130183,130184,130185,130201,130202,130203,130204,130205,130206,130221,130223,130224,130225,130227,130229,130230,130281,130282,130283,130301,130302,130303,130304,130321,130322,130323,130324,130401,130402,130403,130404,130406,130421,130423,130424,130425,130426,130427,130428,130429,130430,130431,130432,130433,130434,130435,130481,130501,130502,130503,130521,130522,130523,130524,130525,130526,130527,130528,130529,130530,130531,130532,130533,130534,130535,130581,130582,130601,130602,130603,130604,130621,130622,130623,130624,130625,130626,130627,130628,130629,130630,130631,130632,130633,130634,130635,130636,130637,130638,130681,130682,130683,130684,130701,130702,130703,130705,130706,130721,130722,130723,130724,130725,130726,130727,130728,130729,130730,130731,130732,130733,130801,130802,130803,130804,130821,130822,130823,130824,130825,130826,130827,130828,130901,130902,130903,130921,130922,130923,130924,130925,130926,130927,130928,130929,130930,130981,130982,130983,130984,131001,131002,131003,131022,131023,131024,131025,131026,131028,131081,131082,131101,131102,131121,131122,131123,131124,131125,131126,131127,131128,131181,131182,140101,140105,140106,140107,140108,140109,140110,140121,140122,140123,140181,140201,140202,140203,140211,140212,140221,140222,140223,140224,140225,140226,140227,140301,140302,140303,140311,140321,140322,140401,140402,140411,140421,140423,140424,140425,140426,140427,140428,140429,140430,140431,140481,140501,140502,140521,140522,140524,140525,140581,140601,140602,140603,140621,140622,140623,140624,140701,140702,140721,140722,140723,140724,140725,140726,140727,140728,140729,140781,140801,140802,140821,140822,140823,140824,140825,140826,140827,140828,140829,140830,140881,140882,140901,140902,140921,140922,140923,140924,140925,140926,140927,140928,140929,140930,140931,140932,140981,141001,141002,141021,141022,141023,141024,141025,141026,141027,141028,141029,141030,141031,141032,141033,141034,141081,141082,142301,142302,142303,142322,142323,142325,142326,142327,142328,142329,142330,142332,142333,150101,150102,150103,150104,150105,150121,150122,150123,150124,150125,150201,150202,150203,150204,150205,150206,150207,150221,150222,150223,150301,150302,150303,150304,150401,150402,150403,150404,150421,150422,150423,150424,150425,150426,150428,150429,150430,150501,150502,150521,150522,150523,150524,150525,150526,150581,152101,152102,152103,152104,152105,152106,152122,152123,152127,152128,152129,152130,152131,152201,152202,152221,152222,152223,152224,152501,152502,152522,152523,152524,152525,152526,152527,152528,152529,152530,152531,152601,152602,152624,152625,152626,152627,152629,152630,152631,152632,152634,152701,152722,152723,152724,152725,152726,152727,152728,152801,152822,152823,152824,152825,152826,152827,152921,152922,152923,210101,210102,210103,210104,210105,210106,210111,210112,210113,210114,210122,210123,210124,210181,210201,210202,210203,210204,210211,210212,210213,210224,210281,210282,210283,210301,210302,210303,210304,210311,210321,210323,210381,210401,210402,210403,210404,210411,210421,210422,210423,210501,210502,210503,210504,210505,210521,210522,210601,210602,210603,210604,210624,210681,210682,210701,210702,210703,210711,210726,210727,210781,210782,210801,210802,210803,210804,210811,210881,210882,210901,210902,210903,210904,210905,210911,210921,210922,211001,211002,211003,211004,211005,211011,211021,211081,211101,211102,211103,211121,211122,211201,211202,211204,211221,211223,211224,211281,211282,211301,211302,211303,211321,211322,211324,211381,211382,211401,211402,211403,211404,211421,211422,211481,220101,220102,220103,220104,220105,220106,220112,220122,220181,220182,220183,220201,220202,220203,220204,220211,220221,220281,220282,220283,220284,220301,220302,220303,220322,220323,220381,220382,220401,220402,220403,220421,220422,220501,220502,220503,220521,220523,220524,220581,220582,220601,220602,220621,220622,220623,220625,220681,220701,220702,220721,220722,220723,220724,220801,220802,220821,220822,220881,220882,222401,222402,222403,222404,222405,222406,222424,222426,230101,230102,230103,230104,230105,230106,230107,230108,230121,230123,230124,230125,230126,230127,230128,230129,230181,230182,230183,230184,230201,230202,230203,230204,230205,230206,230207,230208,230221,230223,230224,230225,230227,230229,230230,230231,230281,230301,230302,230303,230304,230305,230306,230307,230321,230381,230382,230401,230402,230403,230404,230405,230406,230407,230421,230422,230501,230502,230503,230505,230506,230521,230522,230523,230524,230601,230602,230603,230604,230605,230606,230621,230622,230623,230624,230701,230702,230703,230704,230705,230706,230707,230708,230709,230710,230711,230712,230713,230714,230715,230716,230722,230781,230801,230802,230803,230804,230805,230811,230822,230826,230828,230833,230881,230882,230901,230902,230903,230904,230921,231001,231002,231003,231004,231005,231024,231025,231081,231083,231084,231085,231101,231102,231121,231123,231124,231181,231182,231201,231202,231221,231222,231223,231224,231225,231226,231281,231282,231283,232721,232722,232723,310101,310103,310104,310105,310106,310107,310108,310109,310110,310112,310113,310114,310115,310116,310117,310118,310225,310226,310230,320101,320102,320103,320104,320105,320106,320107,320111,320112,320113,320114,320115,320122,320123,320124,320125,320201,320202,320203,320204,320205,320206,320211,320281,320282,320301,320302,320303,320304,320305,320311,320321,320322,320323,320324,320381,320382,320401,320402,320404,320405,320411,320481,320482,320483,320501,320502,320503,320504,320505,320506,320507,320581,320582,320583,320584,320585,320601,320602,320611,320621,320623,320681,320682,320683,320684,320701,320703,320704,320705,320706,320721,320722,320723,320724,320801,320802,320803,320804,320811,320826,320829,320830,320831,320901,320902,320921,320922,320923,320924,320925,320928,320981,320982,321001,321002,321003,321011,321023,321081,321084,321088,321101,321102,321111,321121,321181,321182,321183,321201,321202,321203,321281,321282,321283,321284,321301,321302,321321,321322,321323,321324,330101,330102,330103,330104,330105,330106,330108,330122,330127,330181,330182,330183,330184,330185,330201,330203,330204,330205,330206,330211,330225,330226,330227,330281,330282,330283,330301,330302,330303,330304,330322,330324,330326,330327,330328,330329,330381,330382,330401,330402,330411,330421,330424,330481,330482,330483,330501,330521,330522,330523,330601,330602,330621,330624,330681,330682,330683,330701,330702,330703,330723,330726,330727,330781,330782,330783,330784,330801,330802,330821,330822,330824,330825,330881,330901,330902,330903,330921,330922,331001,331002,331003,331004,331021,331022,331023,331024,331081,331082,331101,331102,331121,331122,331123,331124,331125,331126,331127,331181,340101,340102,340103,340104,340111,340121,340122,340123,340201,340202,340203,340204,340207,340221,340222,340223,340301,340302,340303,340304,340311,340321,340322,340323,340401,340402,340403,340404,340405,340406,340421,340501,340502,340503,340504,340505,340521,340601,340602,340603,340604,340621,340701,340702,340703,340711,340721,340801,340802,340803,340811,340822,340823,340824,340825,340826,340827,340828,340881,341001,341002,341003,341004,341021,341022,341023,341024,341101,341102,341103,341122,341124,341125,341126,341181,341182,341201,341202,341203,341204,341221,341222,341225,341226,341282,341301,341302,341321,341322,341323,341324,341401,341402,341421,341422,341423,341424,341501,341502,341503,341521,341522,341523,341524,341525,341601,341602,341621,341622,341623,341701,341702,341721,341722,341723,341801,341802,341821,341822,341823,341824,341825,341881,350101,350102,350103,350104,350105,350111,350121,350122,350123,350124,350125,350128,350181,350182,350201,350202,350203,350204,350205,350206,350211,350212,350301,350302,350303,350321,350322,350401,350402,350403,350421,350423,350424,350425,350426,350427,350428,350429,350430,350481,350501,350502,350503,350504,350505,350521,350524,350525,350526,350527,350581,350582,350583,350601,350602,350603,350622,350623,350624,350625,350626,350627,350628,350629,350681,350701,350702,350721,350722,350723,350724,350725,350781,350782,350783,350784,350801,350802,350821,350822,350823,350824,350825,350881,350901,350902,350921,350922,350923,350924,350925,350926,350981,350982,360101,360102,360103,360104,360105,360111,360121,360122,360123,360124,360201,360202,360203,360222,360281,360301,360302,360313,360321,360322,360323,360401,360402,360403,360421,360423,360424,360425,360426,360427,360428,360429,360430,360481,360501,360502,360521,360601,360602,360622,360681,360701,360702,360721,360722,360723,360724,360725,360726,360727,360728,360729,360730,360731,360732,360733,360734,360735,360781,360782,360801,360802,360803,360821,360822,360823,360824,360825,360826,360827,360828,360829,360830,360881,360901,360902,360921,360922,360923,360924,360925,360926,360981,360982,360983,361001,361002,361021,361022,361023,361024,361025,361026,361027,361028,361029,361030,361101,361102,361121,361122,361123,361124,361125,361126,361127,361128,361129,361130,361181,370101,370102,370103,370104,370105,370112,370123,370124,370125,370126,370181,370201,370202,370203,370205,370211,370212,370213,370214,370281,370282,370283,370284,370285,370301,370302,370303,370304,370305,370306,370321,370322,370323,370401,370402,370403,370404,370405,370406,370481,370501,370502,370503,370521,370522,370523,370601,370602,370611,370612,370613,370634,370681,370682,370683,370684,370685,370686,370687,370701,370702,370703,370704,370705,370724,370725,370781,370782,370783,370784,370785,370786,370801,370802,370811,370826,370827,370828,370829,370830,370831,370832,370881,370882,370883,370901,370902,370903,370921,370923,370982,370983,371001,371002,371081,371082,371083,371101,371102,371121,371122,371201,371202,371203,371301,371302,371311,371312,371321,371322,371323,371324,371325,371326,371327,371328,371329,371401,371402,371421,371422,371423,371424,371425,371426,371427,371428,371481,371482,371501,371502,371521,371522,371523,371524,371525,371526,371581,371601,371603,371621,371622,371623,371624,371625,371626,371701,371702,371721,371722,371723,371724,371725,371726,371727,371728,410101,410102,410103,410104,410105,410106,410108,410122,410181,410182,410183,410184,410185,410201,410202,410203,410204,410205,410211,410221,410222,410223,410224,410225,410301,410302,410303,410304,410305,410306,410307,410322,410323,410324,410325,410326,410327,410328,410329,410381,410401,410402,410403,410404,410411,410421,410422,410423,410425,410481,410482,410501,410502,410503,410504,410511,410522,410523,410526,410527,410581,410601,410602,410603,410611,410621,410622,410701,410702,410703,410704,410711,410721,410724,410725,410726,410727,410728,410781,410782,410801,410802,410803,410804,410811,410821,410822,410823,410825,410881,410882,410883,410901,410902,410922,410923,410926,410927,410928,411001,411002,411023,411024,411025,411081,411082,411101,411102,411121,411122,411123,411201,411202,411221,411222,411224,411281,411282,411301,411302,411303,411321,411322,411323,411324,411325,411326,411327,411328,411329,411330,411381,411401,411402,411403,411421,411422,411423,411424,411425,411426,411481,411501,411502,411503,411521,411522,411523,411524,411525,411526,411527,411528,411601,411602,411621,411622,411623,411624,411625,411626,411627,411628,411681,411701,411702,411721,411722,411723,411724,411725,411726,411727,411728,411729,420101,420102,420103,420104,420105,420106,420107,420111,420112,420113,420114,420115,420116,420117,420201,420202,420203,420204,420205,420222,420281,420301,420302,420303,420321,420322,420323,420324,420325,420381,420501,420502,420503,420504,420505,420521,420525,420526,420527,420528,420529,420581,420582,420583,420601,420602,420606,420621,420624,420625,420626,420682,420683,420684,420701,420702,420703,420704,420801,420802,420821,420822,420881,420901,420902,420921,420922,420923,420981,420982,420984,421001,421002,421003,421022,421023,421024,421081,421083,421087,421101,421102,421121,421122,421123,421124,421125,421126,421127,421181,421182,421201,421202,421221,421222,421223,421224,421281,421301,421302,421381,422801,422802,422822,422823,422825,422826,422827,422828,429004,429005,429006,429021,430101,430102,430103,430104,430105,430111,430121,430122,430124,430181,430201,430202,430203,430204,430211,430221,430223,430224,430225,430281,430301,430302,430304,430321,430381,430382,430401,430402,430403,430404,430411,430412,430421,430422,430423,430424,430426,430481,430482,430501,430502,430503,430511,430521,430522,430523,430524,430525,430527,430528,430529,430581,430601,430602,430603,430611,430621,430623,430624,430626,430681,430682,430701,430702,430703,430721,430722,430723,430724,430725,430726,430781,430801,430802,430811,430821,430822,430901,430902,430903,430921,430922,430923,430981,431001,431002,431003,431021,431022,431023,431024,431025,431026,431027,431028,431081,431101,431102,431103,431121,431122,431123,431124,431125,431126,431127,431128,431129,431201,431202,431221,431222,431223,431224,431225,431226,431227,431228,431229,431230,431281,431301,431302,431321,431322,431381,431382,433101,433122,433123,433124,433125,433126,433127,433130,440101,440102,440103,440104,440105,440106,440107,440111,440112,440113,440114,440183,440184,440201,440202,440203,440204,440221,440222,440224,440229,440232,440233,440281,440282,440301,440303,440304,440305,440306,440307,440308,440401,440402,440421,440501,440506,440507,440508,440509,440510,440523,440582,440583,440601,440602,440603,440681,440682,440683,440684,440701,440703,440704,440781,440782,440783,440784,440785,440801,440802,440803,440804,440811,440823,440825,440881,440882,440883,440901,440902,440923,440981,440982,440983,441201,441202,441203,441223,441224,441225,441226,441283,441284,441301,441302,441322,441323,441324,441381,441401,441402,441421,441422,441423,441424,441426,441427,441481,441501,441502,441521,441523,441581,441601,441602,441621,441622,441623,441624,441625,441701,441702,441721,441723,441781,441801,441802,441821,441823,441825,441826,441827,441881,441882,441901,441902,441903,441904,442001,442002,442003,442004,442005,445101,445102,445121,445122,445201,445202,445221,445222,445224,445281,445301,445302,445321,445322,445323,445381,450101,450102,450103,450104,450105,450106,450111,450121,450122,450201,450202,450203,450204,450205,450211,450221,450222,450301,450302,450303,450304,450305,450311,450321,450322,450323,450324,450325,450326,450327,450328,450329,450330,450331,450332,450401,450403,450404,450411,450421,450422,450423,450481,450501,450502,450503,450512,450521,450601,450602,450603,450621,450681,450701,450702,450703,450721,450722,450801,450802,450803,450821,450881,450901,450902,450921,450922,450923,450924,450981,452101,452122,452123,452124,452126,452127,452128,452129,452130,452131,452132,452133,452201,452223,452224,452225,452226,452227,452228,452229,452230,452231,452402,452424,452427,452428,452601,452622,452623,452624,452625,452626,452627,452628,452629,452630,452631,452632,452701,452702,452723,452724,452725,452726,452727,452728,452729,452730,452731,460101,460102,460103,460104,460105,460106,460107,460125,460126,460127,460128,460130,460131,460133,460134,460135,460136,460137,460138,460139,460201,460202,460203,460204,460301,500101,500102,500103,500104,500105,500106,500107,500108,500109,500110,500111,500112,500113,500114,500221,500222,500223,500224,500225,500226,500227,500228,500229,500230,500231,500232,500233,500234,500235,500236,500237,500238,500240,500241,500242,500243,500381,500382,500383,500384,510101,510103,510104,510105,510106,510107,510108,510112,510113,510121,510122,510123,510124,510125,510129,510131,510132,510181,510182,510183,510184,510301,510302,510303,510304,510311,510321,510322,510401,510402,510403,510411,510421,510422,510501,510502,510503,510504,510521,510522,510524,510525,510601,510603,510623,510626,510681,510682,510683,510701,510703,510704,510710,510722,510723,510724,510725,510726,510727,510781,510801,510802,510811,510812,510821,510822,510823,510824,510901,510902,510921,510922,510923,511001,511002,511011,511024,511025,511028,511101,511102,511111,511112,511113,511123,511124,511126,511129,511132,511133,511181,511301,511302,511303,511304,511321,511322,511323,511324,511325,511381,511401,511402,511421,511422,511423,511424,511425,511501,511502,511521,511522,511523,511524,511525,511526,511527,511528,511529,511601,511602,511621,511622,511623,511681,511701,511702,511721,511722,511723,511724,511725,511781,511801,511802,511821,511822,511823,511824,511825,511826,511827,511901,511902,511921,511922,511923,512001,512002,512021,512022,512081,513221,513222,513223,513224,513225,513226,513227,513228,513229,513230,513231,513232,513233,513321,513322,513323,513324,513325,513326,513327,513328,513329,513330,513331,513332,513333,513334,513335,513336,513337,513338,513401,513422,513423,513424,513425,513426,513427,513428,513429,513430,513431,513432,513433,513434,513435,513436,513437,520101,520102,520103,520111,520112,520113,520114,520121,520122,520123,520181,520201,520203,520221,520222,520301,520302,520321,520322,520323,520324,520325,520326,520327,520328,520329,520330,520381,520382,520401,520402,520421,520422,520423,520424,520425,522201,522222,522223,522224,522225,522226,522227,522228,522229,522230,522301,522322,522323,522324,522325,522326,522327,522328,522401,522422,522423,522424,522425,522426,522427,522428,522601,522622,522623,522624,522625,522626,522627,522628,522629,522630,522631,522632,522633,522634,522635,522636,522701,522702,522722,522723,522725,522726,522727,522728,522729,522730,522731,522732,530101,530102,530103,530111,530112,530113,530121,530122,530124,530125,530126,530127,530128,530129,530181,530301,530302,530321,530322,530323,530324,530325,530326,530328,530381,530401,530402,530421,530422,530423,530424,530425,530426,530427,530428,530501,530502,530521,530522,530523,530524,532101,532122,532123,532124,532125,532126,532127,532128,532129,532130,532131,532301,532322,532323,532324,532325,532326,532327,532328,532329,532331,532501,532502,532522,532523,532524,532525,532526,532527,532528,532529,532530,532531,532532,532621,532622,532623,532624,532625,532626,532627,532628,532701,532722,532723,532724,532725,532726,532727,532728,532729,532730,532801,532822,532823,532901,532922,532923,532924,532925,532926,532927,532928,532929,532930,532931,532932,533102,533103,533122,533123,533124,533221,533222,533223,533224,533321,533323,533324,533325,533421,533422,533423,533521,533522,533523,533524,533525,533526,533527,533528,540101,540102,540121,540122,540123,540124,540125,540126,540127,542121,542122,542123,542124,542125,542126,542127,542128,542129,542132,542133,542221,542222,542223,542224,542225,542226,542227,542228,542229,542231,542232,542233,542301,542322,542323,542324,542325,542326,542327,542328,542329,542330,542331,542332,542333,542334,542335,542336,542337,542338,542421,542422,542423,542424,542425,542426,542427,542428,542429,542430,542521,542522,542523,542524,542525,542526,542527,542621,542622,542623,542624,542625,542626,542627,610101,610102,610103,610104,610111,610112,610113,610114,610115,610121,610122,610124,610125,610126,610201,610202,610203,610221,610222,610301,610302,610303,610321,610322,610323,610324,610326,610327,610328,610329,610330,610331,610401,610402,610403,610404,610422,610423,610424,610425,610426,610427,610428,610429,610430,610431,610481,610501,610502,610521,610522,610523,610524,610525,610526,610527,610528,610581,610582,610601,610602,610621,610622,610623,610624,610625,610626,610627,610628,610629,610630,610631,610632,610701,610702,610721,610722,610723,610724,610725,610726,610727,610728,610729,610730,610801,610802,610821,610822,610823,610824,610825,610826,610827,610828,610829,610830,610831,610901,610902,610921,610922,610923,610924,610925,610926,610927,610928,610929,612501,612522,612523,612524,612525,612526,612527,620101,620102,620103,620104,620105,620111,620121,620122,620123,620201,620301,620302,620321,620401,620402,620403,620421,620422,620423,620501,620502,620503,620521,620522,620523,620524,620525,622101,622102,622103,622123,622124,622125,622126,622201,622222,622223,622224,622225,622226,622301,622322,622323,622326,622421,622424,622425,622426,622427,622428,622429,622621,622623,622624,622625,622626,622627,622628,622629,622630,622701,622722,622723,622724,622725,622726,622727,622801,622821,622822,622823,622824,622825,622826,622827,622901,622921,622922,622923,622924,622925,622926,622927,623001,623021,623022,623023,623024,623025,623026,623027,630101,630102,630103,630104,630105,630121,630122,630123,632121,632122,632123,632126,632127,632128,632221,632222,632223,632224,632321,632322,632323,632324,632521,632522,632523,632524,632525,632621,632622,632623,632624,632625,632626,632721,632722,632723,632724,632725,632726,632801,632802,632821,632822,632823,640101,640102,640103,640111,640121,640122,640201,640202,640203,640204,640221,640222,640223,640301,640302,640321,640322,640323,640324,640381,640382,642221,642222,642223,642224,642225,642226,650101,650102,650103,650104,650105,650106,650107,650108,650121,650201,650202,650203,650204,650205,652101,652122,652123,652201,652222,652223,652301,652302,652303,652323,652324,652325,652327,652328,652701,652722,652723,652801,652822,652823,652824,652825,652826,652827,652828,652829,652901,652922,652923,652924,652925,652926,652927,652928,652929,653001,653022,653023,653024,653101,653121,653122,653123,653124,653125,653126,653127,653128,653129,653130,653131,653201,653221,653222,653223,653224,653225,653226,653227,654001,654101,654121,654122,654123,654124,654125,654126,654127,654128,654201,654202,654221,654223,654224,654225,654226,654301,654321,654322,654323,654324,654325,654326,659001,710101,710102,710103,810101,810102,810103,910101,910102,910103
pom.xml
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.lihaoze</groupId>
<artifactId>hadoop</artifactId>
<version>1.0.0</version>
<packaging>jar</packaging>
<name>hadoop</name>
<url>http://maven.apache.org</url>
<properties>
<jdk.version>1.8</jdk.version>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<project.reporting.outputEncoding>UTF-8</project.reporting.outputEncoding>
<maven.test.failure.ignore>true</maven.test.failure.ignore>
<maven.test.skip>true</maven.test.skip>
</properties>
<dependencies>
<!-- junit-jupiter-api -->
<dependency>
<groupId>org.junit.jupiter</groupId>
<artifactId>junit-jupiter-api</artifactId>
<version>5.9.2</version>
<scope>test</scope>
</dependency>
<!-- junit-jupiter-engine -->
<dependency>
<groupId>org.junit.jupiter</groupId>
<artifactId>junit-jupiter-engine</artifactId>
<version>5.9.2</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.18.26</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-slf4j-impl</artifactId>
<version>2.20.0</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>3.3.5</version>
</dependency>
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>31.1-jre</version>
</dependency>
<!-- commons-pool2 -->
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-pool2</artifactId>
<version>2.11.1</version>
</dependency>
<dependency>
<groupId>com.janeluo</groupId>
<artifactId>ikanalyzer</artifactId>
<version>2012_u6</version>
</dependency>
<dependency>
<groupId>com.github.binarywang</groupId>
<artifactId>java-testdata-generator</artifactId>
<version>1.1.2</version>
</dependency>
<dependency>
<groupId>commons-io</groupId>
<artifactId>commons-io</artifactId>
<version>2.11.0</version>
</dependency>
</dependencies>
<build>
<finalName>${project.artifactId}</finalName>
<!--<outputDirectory>../package</outputDirectory>-->
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.11.0</version>
<configuration>
<!-- 设置编译字符编码 -->
<encoding>UTF-8</encoding>
<!-- 设置编译jdk版本 -->
<source>${jdk.version}</source>
<target>${jdk.version}</target>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-clean-plugin</artifactId>
<version>3.2.0</version>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-resources-plugin</artifactId>
<version>3.3.1</version>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-war-plugin</artifactId>
<version>3.3.2</version>
</plugin>
<!-- 编译级别 -->
<!-- 打包的时候跳过测试junit begin -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-surefire-plugin</artifactId>
<version>2.22.2</version>
<configuration>
<skip>true</skip>
</configuration>
</plugin>
</plugins>
</build>
</project>
工具类
package com.lihaozhe.mock;
import cn.binarywang.tools.generator.ChineseIDCardNumberGenerator;
import cn.binarywang.tools.generator.ChineseMobileNumberGenerator;
import cn.binarywang.tools.generator.ChineseNameGenerator;
import cn.binarywang.tools.generator.base.GenericGenerator;
import org.apache.commons.io.FileUtils;
import org.junit.jupiter.api.Test;
import java.io.File;
import java.io.IOException;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.List;
import java.util.ListIterator;
/**
* @author 李昊哲
* @version 1.0.0
* @create 2023/4/25 20:18
*/
public class MockTest {
private static List<String> provinceCodes = new ArrayList<>();
static {
provinceCodes.add("11");
provinceCodes.add("12");
provinceCodes.add("13");
provinceCodes.add("14");
provinceCodes.add("15");
provinceCodes.add("21");
provinceCodes.add("22");
provinceCodes.add("23");
provinceCodes.add("31");
provinceCodes.add("32");
provinceCodes.add("33");
provinceCodes.add("34");
provinceCodes.add("35");
provinceCodes.add("36");
provinceCodes.add("37");
provinceCodes.add("41");
provinceCodes.add("42");
provinceCodes.add("43");
provinceCodes.add("44");
provinceCodes.add("45");
provinceCodes.add("46");
provinceCodes.add("51");
provinceCodes.add("52");
provinceCodes.add("53");
provinceCodes.add("54");
provinceCodes.add("61");
provinceCodes.add("62");
provinceCodes.add("63");
provinceCodes.add("64");
provinceCodes.add("65");
provinceCodes.add("71");
provinceCodes.add("81");
provinceCodes.add("91");
}
@Test
public void test01() throws IOException {
String suffix = ".csv";
String[] rcs = FileUtils.readFileToString(new File("region_code.txt"), "UTF-8").split(",");
List<String> codes = Arrays.asList(rcs);
ChineseNameGenerator nameGenerator = ChineseNameGenerator.getInstance();
GenericGenerator idCardGenerator = ChineseIDCardNumberGenerator.getInstance();
ChineseMobileNumberGenerator mobileNumberGenerator = ChineseMobileNumberGenerator.getInstance();
StringBuilder content = new StringBuilder();
for (long i = 0; i < 10000000; i++) {
String idCard = idCardGenerator.generate();
if (idCard.startsWith("82")){
continue;
}
if (codes.contains(idCard.substring(0,6))){
content.append(idCard).append(",");
content.append(nameGenerator.generate()).append(",");
content.append(mobileNumberGenerator.generate()).append("\n");
File file = new File(idCard.substring(0, 2) + suffix);
FileUtils.write(file, content.toString(), "UTF-8", true);
System.out.println(content.toString());
content.delete(0, content.length());
}
}
System.out.println("success");
}
@Test
public void test02() throws IOException {
String suffix = ".csv";
List<String> list = FileUtils.readLines(new File("22.csv"), "UTF-8");
File file;
for (String content : list) {
String city_code = content.substring(0, 4);
file = new File(city_code + suffix);
FileUtils.write(file,content + "\n","UTF-8",true);
System.out.println(content);
}
System.out.println("success");
}
}
创建数据库
hdfs dfs -mkdir -p /partition
create database pt location '/partition';
内部分区表
内部分区表
create table partition_1(
id_card string,
real_name string,
mobile string
)partitioned by (province_code string)
row format delimited fields terminated by ','
lines terminated by '\n'
stored as textfile;
导入数据
load data local inpath '/root/region/11.csv' into table partition_1 partition(province_code='11');
load data local inpath '/root/region/12.csv' into table partition_1 partition(province_code='12');
load data local inpath '/root/region/13.csv' into table partition_1 partition(province_code='13');
load data local inpath '/root/region/14.csv' into table partition_1 partition(province_code='14');
load data local inpath '/root/region/15.csv' into table partition_1 partition(province_code='15');
load data local inpath '/root/region/21.csv' into table partition_1 partition(province_code='21');
load data local inpath '/root/region/22.csv' into table partition_1 partition(province_code='22');
load data local inpath '/root/region/23.csv' into table partition_1 partition(province_code='23');
load data local inpath '/root/region/31.csv' into table partition_1 partition(province_code='31');
load data local inpath '/root/region/32.csv' into table partition_1 partition(province_code='32');
load data local inpath '/root/region/33.csv' into table partition_1 partition(province_code='33');
load data local inpath '/root/region/34.csv' into table partition_1 partition(province_code='34');
load data local inpath '/root/region/35.csv' into table partition_1 partition(province_code='35');
load data local inpath '/root/region/36.csv' into table partition_1 partition(province_code='36');
load data local inpath '/root/region/37.csv' into table partition_1 partition(province_code='37');
load data local inpath '/root/region/41.csv' into table partition_1 partition(province_code='41');
load data local inpath '/root/region/42.csv' into table partition_1 partition(province_code='42');
load data local inpath '/root/region/43.csv' into table partition_1 partition(province_code='43');
load data local inpath '/root/region/44.csv' into table partition_1 partition(province_code='44');
load data local inpath '/root/region/45.csv' into table partition_1 partition(province_code='45');
load data local inpath '/root/region/46.csv' into table partition_1 partition(province_code='46');
load data local inpath '/root/region/51.csv' into table partition_1 partition(province_code='51');
load data local inpath '/root/region/52.csv' into table partition_1 partition(province_code='52');
load data local inpath '/root/region/53.csv' into table partition_1 partition(province_code='53');
load data local inpath '/root/region/54.csv' into table partition_1 partition(province_code='54');
load data local inpath '/root/region/61.csv' into table partition_1 partition(province_code='61');
load data local inpath '/root/region/62.csv' into table partition_1 partition(province_code='62');
load data local inpath '/root/region/63.csv' into table partition_1 partition(province_code='63');
load data local inpath '/root/region/64.csv' into table partition_1 partition(province_code='64');
load data local inpath '/root/region/65.csv' into table partition_1 partition(province_code='65');
load data local inpath '/root/region/71.csv' into table partition_1 partition(province_code='71');
load data local inpath '/root/region/81.csv' into table partition_1 partition(province_code='81');
load data local inpath '/root/region/91.csv' into table partition_1 partition(province_code='91');
外部分区表
创建外部分区表关联目录
hdfs dfs -mkdir -p /partition/partition_2
创建外部分区表
create external table partition_2(
id_card string,
real_name string,
mobile string
)partitioned by (province_code string)
row format delimited fields terminated by ','
lines terminated by '\n'
stored as textfile
location '/partition/partition_2';
导入数据
load data local inpath '/root/region/11.csv' into table partition_2 partition(province_code='11');
load data local inpath '/root/region/12.csv' into table partition_2 partition(province_code='12');
load data local inpath '/root/region/13.csv' into table partition_2 partition(province_code='13');
load data local inpath '/root/region/14.csv' into table partition_2 partition(province_code='14');
load data local inpath '/root/region/15.csv' into table partition_2 partition(province_code='15');
load data local inpath '/root/region/21.csv' into table partition_2 partition(province_code='21');
load data local inpath '/root/region/22.csv' into table partition_2 partition(province_code='22');
load data local inpath '/root/region/23.csv' into table partition_2 partition(province_code='23');
load data local inpath '/root/region/31.csv' into table partition_2 partition(province_code='31');
load data local inpath '/root/region/32.csv' into table partition_2 partition(province_code='32');
load data local inpath '/root/region/33.csv' into table partition_2 partition(province_code='33');
load data local inpath '/root/region/34.csv' into table partition_2 partition(province_code='34');
load data local inpath '/root/region/35.csv' into table partition_2 partition(province_code='35');
load data local inpath '/root/region/36.csv' into table partition_2 partition(province_code='36');
load data local inpath '/root/region/37.csv' into table partition_2 partition(province_code='37');
load data local inpath '/root/region/41.csv' into table partition_2 partition(province_code='41');
load data local inpath '/root/region/42.csv' into table partition_2 partition(province_code='42');
load data local inpath '/root/region/43.csv' into table partition_2 partition(province_code='43');
load data local inpath '/root/region/44.csv' into table partition_2 partition(province_code='44');
load data local inpath '/root/region/45.csv' into table partition_2 partition(province_code='45');
load data local inpath '/root/region/46.csv' into table partition_2 partition(province_code='46');
load data local inpath '/root/region/51.csv' into table partition_2 partition(province_code='51');
load data local inpath '/root/region/52.csv' into table partition_2 partition(province_code='52');
load data local inpath '/root/region/53.csv' into table partition_2 partition(province_code='53');
load data local inpath '/root/region/54.csv' into table partition_2 partition(province_code='54');
load data local inpath '/root/region/61.csv' into table partition_2 partition(province_code='61');
load data local inpath '/root/region/62.csv' into table partition_2 partition(province_code='62');
load data local inpath '/root/region/63.csv' into table partition_2 partition(province_code='63');
load data local inpath '/root/region/64.csv' into table partition_2 partition(province_code='64');
load data local inpath '/root/region/65.csv' into table partition_2 partition(province_code='65');
load data local inpath '/root/region/71.csv' into table partition_2 partition(province_code='71');
load data local inpath '/root/region/81.csv' into table partition_2 partition(province_code='81');
load data local inpath '/root/region/91.csv' into table partition_2 partition(province_code='91');
多重内部分区表
创建内部多重内部分区表
create table partition_3(
id_card string,
real_name string,
mobile string
)partitioned by (province_code string,city_code string)
row format delimited fields terminated by ','
lines terminated by '\n'
stored as textfile;
导入数据
load data local inpath '/root/dongbei/21/2101.csv' into table partition_3 partition(province_code='21',city_code='2101');
load data local inpath '/root/dongbei/21/2102.csv' into table partition_3 partition(province_code='21',city_code='2102');
load data local inpath '/root/dongbei/21/2103.csv' into table partition_3 partition(province_code='21',city_code='2103');
load data local inpath '/root/dongbei/21/2104.csv' into table partition_3 partition(province_code='21',city_code='2104');
load data local inpath '/root/dongbei/21/2105.csv' into table partition_3 partition(province_code='21',city_code='2105');
load data local inpath '/root/dongbei/21/2106.csv' into table partition_3 partition(province_code='21',city_code='2106');
load data local inpath '/root/dongbei/21/2107.csv' into table partition_3 partition(province_code='21',city_code='2107');
load data local inpath '/root/dongbei/21/2108.csv' into table partition_3 partition(province_code='21',city_code='2108');
load data local inpath '/root/dongbei/21/2109.csv' into table partition_3 partition(province_code='21',city_code='2109');
load data local inpath '/root/dongbei/21/2110.csv' into table partition_3 partition(province_code='21',city_code='2110');
load data local inpath '/root/dongbei/21/2111.csv' into table partition_3 partition(province_code='21',city_code='2111');
load data local inpath '/root/dongbei/21/2112.csv' into table partition_3 partition(province_code='21',city_code='2112');
load data local inpath '/root/dongbei/21/2113.csv' into table partition_3 partition(province_code='21',city_code='2113');
load data local inpath '/root/dongbei/21/2114.csv' into table partition_3 partition(province_code='21',city_code='2114');
load data local inpath '/root/dongbei/22/2201.csv' into table partition_3 partition(province_code='22',city_code='2201');
load data local inpath '/root/dongbei/22/2202.csv' into table partition_3 partition(province_code='22',city_code='2202');
load data local inpath '/root/dongbei/22/2203.csv' into table partition_3 partition(province_code='22',city_code='2203');
load data local inpath '/root/dongbei/22/2204.csv' into table partition_3 partition(province_code='22',city_code='2204');
load data local inpath '/root/dongbei/22/2205.csv' into table partition_3 partition(province_code='22',city_code='2205');
load data local inpath '/root/dongbei/22/2206.csv' into table partition_3 partition(province_code='22',city_code='2206');
load data local inpath '/root/dongbei/22/2207.csv' into table partition_3 partition(province_code='22',city_code='2207');
load data local inpath '/root/dongbei/22/2208.csv' into table partition_3 partition(province_code='22',city_code='2208');
load data local inpath '/root/dongbei/22/2224.csv' into table partition_3 partition(province_code='22',city_code='2224');
load data local inpath '/root/dongbei/23/2301.csv' into table partition_3 partition(province_code='23',city_code='2301');
load data local inpath '/root/dongbei/23/2302.csv' into table partition_3 partition(province_code='23',city_code='2302');
load data local inpath '/root/dongbei/23/2303.csv' into table partition_3 partition(province_code='23',city_code='2303');
load data local inpath '/root/dongbei/23/2304.csv' into table partition_3 partition(province_code='23',city_code='2304');
load data local inpath '/root/dongbei/23/2305.csv' into table partition_3 partition(province_code='23',city_code='2305');
load data local inpath '/root/dongbei/23/2306.csv' into table partition_3 partition(province_code='23',city_code='2306');
load data local inpath '/root/dongbei/23/2307.csv' into table partition_3 partition(province_code='23',city_code='2307');
load data local inpath '/root/dongbei/23/2308.csv' into table partition_3 partition(province_code='23',city_code='2308');
load data local inpath '/root/dongbei/23/2309.csv' into table partition_3 partition(province_code='23',city_code='2309');
load data local inpath '/root/dongbei/23/2310.csv' into table partition_3 partition(province_code='23',city_code='2310');
load data local inpath '/root/dongbei/23/2311.csv' into table partition_3 partition(province_code='23',city_code='2311');
load data local inpath '/root/dongbei/23/2312.csv' into table partition_3 partition(province_code='23',city_code='2312');
多重外部分区表
创建多重外部分区表关联目录
hdfs dfs -mkdir -p /partition/partition_4
创建多重外部分区表
create external table partition_4(
id_card string,
real_name string,
mobile string
)partitioned by (province_code string,city_code string)
row format delimited fields terminated by ','
lines terminated by '\n'
stored as textfile
location '/partition/partition_4';
load data local inpath '/root/dongbei/21/2101.csv' into table partition_4 partition(province_code='21',city_code='2101');
load data local inpath '/root/dongbei/21/2102.csv' into table partition_4 partition(province_code='21',city_code='2102');
load data local inpath '/root/dongbei/21/2103.csv' into table partition_4 partition(province_code='21',city_code='2103');
load data local inpath '/root/dongbei/21/2104.csv' into table partition_4 partition(province_code='21',city_code='2104');
load data local inpath '/root/dongbei/21/2105.csv' into table partition_4 partition(province_code='21',city_code='2105');
load data local inpath '/root/dongbei/21/2106.csv' into table partition_4 partition(province_code='21',city_code='2106');
load data local inpath '/root/dongbei/21/2107.csv' into table partition_4 partition(province_code='21',city_code='2107');
load data local inpath '/root/dongbei/21/2108.csv' into table partition_4 partition(province_code='21',city_code='2108');
load data local inpath '/root/dongbei/21/2109.csv' into table partition_4 partition(province_code='21',city_code='2109');
load data local inpath '/root/dongbei/21/2110.csv' into table partition_4 partition(province_code='21',city_code='2110');
load data local inpath '/root/dongbei/21/2111.csv' into table partition_4 partition(province_code='21',city_code='2111');
load data local inpath '/root/dongbei/21/2112.csv' into table partition_4 partition(province_code='21',city_code='2112');
load data local inpath '/root/dongbei/21/2113.csv' into table partition_4 partition(province_code='21',city_code='2113');
load data local inpath '/root/dongbei/21/2114.csv' into table partition_4 partition(province_code='21',city_code='2114');
load data local inpath '/root/dongbei/22/2201.csv' into table partition_4 partition(province_code='22',city_code='2201');
load data local inpath '/root/dongbei/22/2202.csv' into table partition_4 partition(province_code='22',city_code='2202');
load data local inpath '/root/dongbei/22/2203.csv' into table partition_4 partition(province_code='22',city_code='2203');
load data local inpath '/root/dongbei/22/2204.csv' into table partition_4 partition(province_code='22',city_code='2204');
load data local inpath '/root/dongbei/22/2205.csv' into table partition_4 partition(province_code='22',city_code='2205');
load data local inpath '/root/dongbei/22/2206.csv' into table partition_4 partition(province_code='22',city_code='2206');
load data local inpath '/root/dongbei/22/2207.csv' into table partition_4 partition(province_code='22',city_code='2207');
load data local inpath '/root/dongbei/22/2208.csv' into table partition_4 partition(province_code='22',city_code='2208');
load data local inpath '/root/dongbei/22/2224.csv' into table partition_4 partition(province_code='22',city_code='2224');
load data local inpath '/root/dongbei/23/2301.csv' into table partition_4 partition(province_code='23',city_code='2301');
load data local inpath '/root/dongbei/23/2302.csv' into table partition_4 partition(province_code='23',city_code='2302');
load data local inpath '/root/dongbei/23/2303.csv' into table partition_4 partition(province_code='23',city_code='2303');
load data local inpath '/root/dongbei/23/2304.csv' into table partition_4 partition(province_code='23',city_code='2304');
load data local inpath '/root/dongbei/23/2305.csv' into table partition_4 partition(province_code='23',city_code='2305');
load data local inpath '/root/dongbei/23/2306.csv' into table partition_4 partition(province_code='23',city_code='2306');
load data local inpath '/root/dongbei/23/2307.csv' into table partition_4 partition(province_code='23',city_code='2307');
load data local inpath '/root/dongbei/23/2308.csv' into table partition_4 partition(province_code='23',city_code='2308');
load data local inpath '/root/dongbei/23/2309.csv' into table partition_4 partition(province_code='23',city_code='2309');
load data local inpath '/root/dongbei/23/2310.csv' into table partition_4 partition(province_code='23',city_code='2310');
load data local inpath '/root/dongbei/23/2311.csv' into table partition_4 partition(province_code='23',city_code='2311');
load data local inpath '/root/dongbei/23/2312.csv' into table partition_4 partition(province_code='23',city_code='2312');
动态分区
-- 动态分区功能总开关(默认true,开启)
set hive.exec.dynamic.partition=true;
-- 严格模式和非严格模式
-- 动态分区的模式,默认strict(严格模式),要求必须指定至少一个分区为静态分区,
-- nonstrict(非严格模式)允许所有的分区字段都使用动态分区。
set hive.exec.dynamic.partition.mode=nonstrict;
-- 一条insert语句可同时创建的最大的分区个数,默认为1000。
set hive.exec.max.dynamic.partitions=1000;
-- 单个Mapper或者Reducer可同时创建的最大的分区个数,默认为100。
set hive.exec.max.dynamic.partitions.pernode=100;
-- 一条insert语句可以创建的最大的文件个数,默认100000。
set hive.exec.max.created.files=100000;
-- 当查询结果为空时且进行动态分区时,是否抛出异常,默认false。
set hive.error.on.empty.partition=false;
create table partition_dynamic(
id_card string,
real_name string,
mobile string
)partitioned by (region_code string)
row format delimited fields terminated by ','
lines terminated by '\n'
stored as textfile;
set hive.exec.dynamic.partition=true;
set hive.exec.dynamic.partition.mode=nonstrict;
set hive.exec.max.dynamic.partitions=1000;
set hive.exec.max.dynamic.partitions.pernode=100;
set hive.exec.max.created.files=100000;
set hive.error.on.empty.partition=false;
-- 执行动态分区插入
insert into table partition_dynamic
select id_card,real_name,mobile,substr(id_card,1,6) from partition_3
where province_code = '22' and city_code in ('2201','2202','2203');
create table dept_partition_dynamic(
id int,
name string
)
partitioned by (loc int)
row format delimited fields terminated by ','
lines terminated by '\n'
stored as textfile;
set hive.exec.dynamic.partition=true;
set hive.exec.dynamic.partition.mode=nonstrict;
set hive.exec.max.dynamic.partitions=1000;
set hive.exec.max.dynamic.partitions.pernode=100;
set hive.exec.max.created.files=100000;
set hive.error.on.empty.partition=false;
insert into table dept_partition_dynamic select dept_id,dept_name,location_code from dept;
分桶
数据抽样 提高join查询效率
- 创建普通表并导入数据
- 开启分桶
- 查询普通表将,将查询结果插入桶
- 从桶中查询数据
创建普通表并导入数据
create table bucket_source(id int);
load data local inpath '/root/bucket_source.txt' into table bucket_source;
开启分桶
set hive.enforce.bucketing=true;
创建桶表
create table bucket_tb(
id int
)clustered by (id) into 4 buckets;
载入数据到桶表
set hive.enforce.bucketing=true;
insert into table bucket_tb select id from bucket_source where id is not null;
-- 数据抽样
-- tablesample(bucket x out of y on id);
-- 注意:y>=x
-- y:表示把桶表中的数据随机分为多少桶
-- x: 表示取出第几桶的数据
select * from bucket_tb tablesample(bucket 1 out of 4 on id);
select * from bucket_tb tablesample(bucket 2 out of 4 on id);
select * from bucket_tb tablesample(bucket 3 out of 4 on id);
select * from bucket_tb tablesample(bucket 4 out of 4 on id);
视图
create view person_view as
select id,real_name, mod(substr(id_card,17,1),2) gender,mobile from person;
存储与压缩
文件格式
行式存储与列式存储
hive表中的数据选择一个合适的文件格式,对于高性能查询是比较有益的
行式存储:text file,sequence file
列式存储:ORC、Parquet
text file:
hive默认采用text file 文件存储格式;文章来源:https://www.toymoban.com/news/detail-446071.html
create table tb_user01 (id int,real_name string)
row format delimited fields terminated by ','
lines terminated by '\n'
stored as textfile;
set hive.exec.compress.output=true;
set mapred.output.compression.codec=org.apache.hadoop.io.compress.GzipCodec;
set mapred.output.compress=true;
set io.compression.codecs=org.apache.hadoop.io.compress.GzipCodec;
insert into tb_user01 values (1,'李昊哲'),(2,'李哲');
sequence file
sequence file 文件 是Hadoop用来存储二进制形式的的 key : value 键值对而设计的一种平面文件 flatmap文章来源地址https://www.toymoban.com/news/detail-446071.html
create table tb_user02 (id int,real_name string)
row format delimited fields terminated by ','
lines terminated by '\n'
stored as sequencefile;
set hive.exec.compress.output=true;
set mapreduce.output.fileoutputformat.compress=true;
set mapreduce.output.fileoutputformat.compress.codec=org.apache.hadoop.io.compress.DeflateCodec;
set io.seqfile.compression.type=BLOCK;
insert into tb_user02 values (1,'李昊哲'),(2,'李哲');
ORC
create table tb_user03 (id int,real_name string)
row format delimited fields terminated by ','
lines terminated by '\n'
stored as orc
tblproperties("orc.compress"="NONE");
create table tb_user03 (id int,real_name string)
row format delimited fields terminated by ','
lines terminated by '\n'
stored as orc
tblproperties("orc.compress"="ZLIB");
create table tb_user03 (id int,real_name string)
row format delimited fields terminated by ','
lines terminated by '\n'
stored as orc
tblproperties("orc.compress"="SNAPPY");
insert into tb_user03 values (1,'李昊哲'),(2,'李哲');
Parquet
create table tb_user04 (id int,real_name string)
row format delimited fields terminated by ','
lines terminated by '\n'
stored as parquet
tblproperties("parquet.compression"="uncompressed");
insert into tb_user03 values (1,'李昊哲'),(2,'李哲');
rcfile
create table tb_user05 (id int,real_name string)
row format delimited fields terminated by ','
lines terminated by '\n'
stored as rcfile;
set hive.exec.compress.output=true;
set mapreduce.output.fileoutputformat.compress=true;
set mapreduce.output.fileoutputformat.compress.codec=org.apache.hadoop.io.compress.DeflateCodec;
insert into tb_user05 values (1,'李昊哲'),(2,'李哲');
到了这里,关于hive 从入门到精通的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!