YOLOV7详细解读(二)论文解读
前言
继美团发布YOLOV6之后,YOLO系列原作者也发布了YOLOV7。
YOLOV7主要的贡献在于:
1.模型重参数化
YOLOV7将模型重参数化引入到网络架构中,重参数化这一思想最早出现于REPVGG中。
2.标签分配策略
YOLOV7的标签分配策略采用的是YOLOV5的跨网格搜索,以及YOLOX的匹配策略。
3.ELAN高效网络架构
YOLOV7中提出的一个新的网络架构,以高效为主。
4.带辅助头的训练
YOLOV7提出了辅助头的一个训练方法,主要目的是通过增加训练成本,提升精度,同时不影响推理的时间,因为辅助头只会出现在训练过程中。
一、YOLOV7是什么?
YOLO算法作为one-stage目标检测算法最典型的代表,其基于深度神经网络进行对象的识别和定位,运行速度很快,可以用于实时系统。
YOLOV7是目前YOLO系列最先进的算法,在准确率和速度上超越了以往的YOLO系列。
了解YOLOV7是对目标检测算法研究的一个必须步骤。
二、论文解读
0.摘要
- YOLOV7在5FPS到160FPS(帧/秒)范围内的速度和精度都超过了所有已知的目标检测器,在GPU V100所有已知的30FPS以上的实时目标检测器中,YOLOv7的准确率最高,达到56.8%AP。
- YOLOV7-E6版本的目标检测(56 FPS V100,55.9%AP)比基于transformer的检测器SWINL级联掩模R-CNN(9.2 FPS,A100,53.9%AP)速度快509%,精度高2%,和基于卷积的检测器convext-xl级联掩模R-CNN(86FPS,A100,55.2%AP)速度快551%,精度高0.7%AP。
- 此外YOLOV7在速度和精度方面优于:YOLOR,YOLO scale-yolov4,YOLOv5,DETR,Deformable DETR,DINO-5scale-R50,vita-adapter-b和许多其他对象测器。此外,我们只在MS COCO数据集上从头开始训练YOLOv7,而不使用任何其他数据集或预训练的权重。
1.引言
- 实时目标检测是计算机视觉中一个非常重要的课题,它往往是计算机视觉系统中必不可少的组成部分。
- 例如,多目标跟踪、自动驾驶、机器人、医学图像分析等。
- 运行实时对象检测的计算设备通常是一些移动CPU或GPU,以及由主要制造商开发的各种神经处理单元(NPU)。
- 例如,苹果的神经引擎(Apple),神经计算(Intel),Jetson的AI边缘设备(Nvidia),边缘TPU(谷歌),神经处理引擎(高通),AI处理单元(联发科),以及AI soc(Kneron),都是NPU。
- 上面提到的一些边缘设备主要用于加速不同的操作,如普通卷积、深度卷积或MLP操作。在本文中,我们提出的实时目标检测器主要是希望它能够同时支持移动GPU和GPU设备,从边缘到云端。
- 近年来,针对不同的边缘设备,仍在开发实时目标检测器。例如,MCUNet和NanoDe的改进主要集中在:产生低功耗的单片机和提高边缘CPU的推理速度。而YOLOX和YOLOR等方法则专注于提高各种GPU的推理速度。
- 近年来,实时目标检测器的发展主要集中在高效体系结构的设计上。至于可以在CPU上使用的实时目标检测器,它们的设计大多基于MobileNet,ShuffleNet,或GhostNet。
- 另一种主流的实时目标检测器是针对GPU开发的,它们大多使用ResNet、DarkNet或DLA,然后使用CSPNet策略来优化架构。
- 本文提出的方法的发展方向不同于目前主流的实时目标检测器。除了架构优化之外,我们提出的方法将重点放在训练过程的优化上。我们将重点讨论一些优化的模块和优化方法,这些模块和优化方法可以在不增加推理成本的情况下,加强训练成本以提高目标检测的准确性。我们把提出的模块和优化方法称为可训练的技巧包。
- 最近,模型重新参数化和动态标签分配已成为网络训练和目标检测中的重要课题。在上述新概念提出之后,目标检测器的训练出了许多新问题。在本文中,我们将介绍一些我们发现的新问题,并提出有效的解决方法。
- 在模型重参数化方面,结合梯度传播路径的概念,分析了不同网络中各层的模型重参数化策略,提出了重新规划的模型重参数化方法。
- 当我们发现使用动态标签分配技术时,多输出层模型的训练会产生新的问题。即:“如何为不同分支的输出分配动态目标?”针对这一问题,我们提出了一种新的标签分配方法,称为粗到细引导标签分配。
- 本文的主要贡献如下:
- (1)我们设计了几种可训练的免费技巧包检测方法,使实时目标检测在不增加推理成本的情况下大大提高了检测精度;
- (2)对于对象检测方法的发展,我们发现了两个新的问题,即重新参数化模块如何取代原有模块,以及动态标签分配策略如何处理对不同输出层的赋值。此外,我们还提出了解决这些问题所带来的困难的方法;
- (3)针对实时目标检测器提出了“扩展”和“复合缩放”两种有效利用参数和计算的方法;
- (4)该方法可有效减少实时目标检测器40%左右的参数和50%的计算量,具有更快的推理速度和更高的检测精度。
2.相关工作
2.1. 实时目标检测器
目前最先进的实时目标检测器主要是基于YOLO和FCOS。
能够成为最先进的实时对象检测器通常需要以下特征:
(1)更快、更强的网络架构;
(2)一种更有效的特征集成方法
(3)更精确的检测方法
(4)更鲁棒的损失函数
(5)一种更有效的标签分配方法
(6)一种更有效的训练方法。
在本文中,我们不打算探索需要额外数据或大型模型的自我监督学习或知识蒸馏方法。相反,我们将重点针对上述(4)、(5)、(6)的最新方法衍生出的问题,设计新的可训练的免费技巧包。
2.2. 模型重参数化
- 模型再参数化技术在推断阶段将多个计算模块合并为一个。
- 模型参数化技术可以看作是一种集成技术,我们可以将其分为两类:模块级集成和模型级集成。为了获得最终的推断模型,有两种常见的模型级重新参数化实践。
- 一是用不同的训练数据训练多个相同的模型。然后平均多个训练模型的权重。
- 二是对不同选代次数下的模型权值进行加权平均。
- 模级再参数化是近年来比较热门的研究课题。这种方法在训练期间将一个模块拆分为多个相同或不同的模块分支,并在推断期间将多个分支模块集成为一个完全等价的模块。然而,并不是所有提出的重新参数化的模块都能完美地应用于不同的架构。考虑到这一点,我们开发了新的重新参数化模块,并为各种架构设计了相关的应用策略。
2.3. 模型缩放
- 模型缩放是一种放大或缩小己经设计好的模型,使其适合不同的计算设备的方法。
模型缩放法通常使用不同的缩放因子,如分辨率(输入图像的大小)、深度(层数)、宽度(通道数)和阶段(特征金字塔的数量),从而在网络参数的数量、计算量、推理速度和精度方面达到良好的权衡。 - 网络架构搜索(Network architecture search,NAS)是一种常用的模型扩展方法。NAS可以从搜索空间中自动搜索合适的比例因子,而不需要定义太复杂的规则。NAS的缺点是需要非常昂贵的计算来完成模型缩放因子的搜索。
- 研究者分析了缩放因子与参数量和操作之间的关系,试图直接估计一些规则,从而得到模型缩放所需的缩放因子。通过查阅文献,我们发现几乎所有的模型缩放方法都是独立分析单个缩放因子的,甚至复合缩放类别中的方法也是独立优化缩放因子的。这是因为大多数流行的NAS架构都处理不太相关的伸缩因子。我们观察到所有基于级联的模型,如DenseNet或VoVNet,当这些模型的深度被缩放时,将改变某些层的输入宽度。由于提出的体系结构是基于级联的,我们必须为此模型设计一种新的复合缩放方法。
3.架构
3.1. 扩展高效层聚合网络
扩展高效层聚合网络在设计高效体系结构的大多数文献中,主要考虑的因素不超过参数数量、计算量和计算密度。
Ma等人还从内存访问代价的特点出发,分析了输入/输出信道比、体系结构分支数量和单元操作对网络推理速度的影响。Dollar’et 等人在执行模型缩放时还考虑了激活层,即更多地考虑卷积层输出张量中的元素数量。
图2(b)中CSPVoVNet的设计是vovnet的变体。CSPVoVNet的架构除了考虑上述的基本设计问题外,还对梯度路径进行了分析,以使不同层的权值学习到更多不同的特征。上述梯度分析方法使得推断更快、更准确。
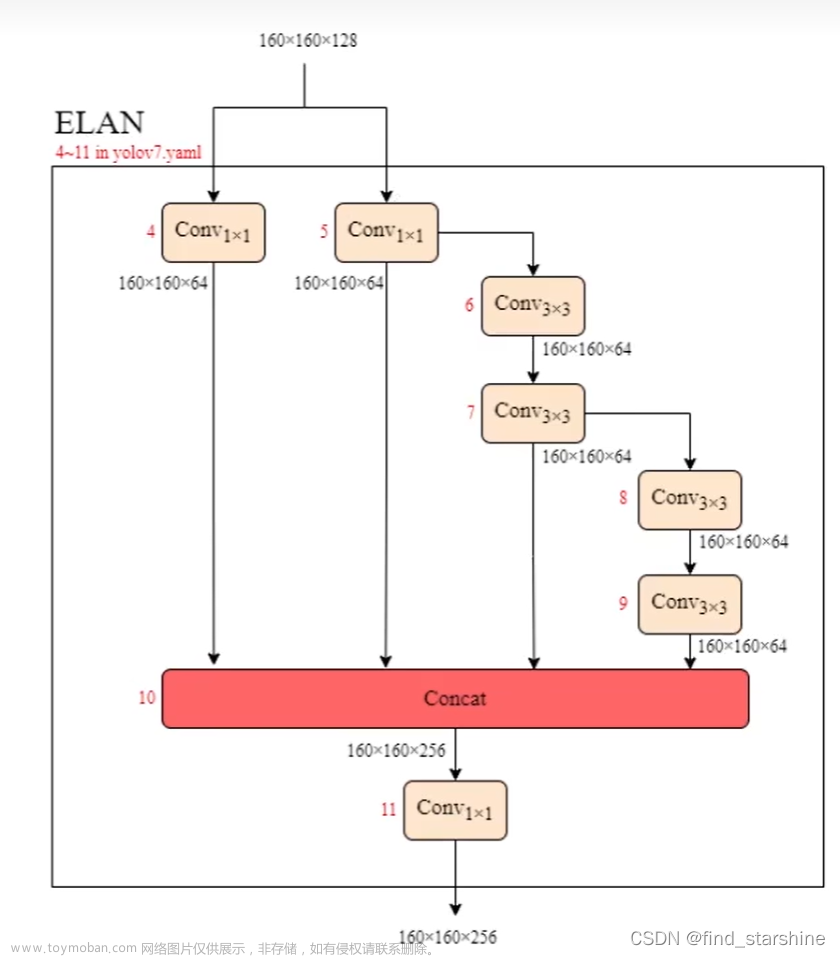
图2(c)中的ELAN[1]考虑了以下设计策略–“如何设计一个高效的网络?”他们得出了一个结论:通过控制最短最长的梯度路径,一个更深的网络可以有效地学习和收敛。本文提出了基于ELAN的Extended-ELAN(E-ELAN),其主要结构如图2(d)所示。
- 在大规模ELAN中,无论梯度路径长度和计算块的堆叠数量如何,它都达到了稳定状态。如果无限地叠加更多的计算块,可能会破坏这种稳定状态,降低参数利用率。
- E-ELAN算法利用扩展、随机打乱、合并基数来实现在不破坏原有梯度路径的情况下不断增强网络学习能力的能力。
- 在体系结构上,E ELAN只改变了计算块的体系结构,而过渡层的体系结构完全不变。我们的策略是使用分组卷积来扩展计算块的信道和基数。
- 我们将对一个计算层的所有计算块应用相同的分组卷积。然后,将每个计算块计算出的特征映射,按照设定的分组卷积组数g,随机打乱成g组,然后拼接在一起。此时,每组feature map中的通道数将与原架构中的通道数相同。最后,我们添加g组特征映射来执行合并基数。除了保持原来的ELAN设计架构,E-ELAN还可以指导不同的计算块组学习更多不同的特征。
3.2. 基于级联的模型缩放
- 基于级联的模型缩放模型缩放的主要目的是调整模型的某些属性,生成不同规模的模型,以满足不同推理速度的需要。
- 例如,effentnet的缩放模型考虑了宽度、深度和分辨率。scale-yolov4的缩放模型是调整阶段数。Dollar’等人分析了常规卷积和分组卷积在进行宽度和深度缩放时对参数量和计算量的影响,并以此设计了相应的模型缩放方法。
- 如图3:基于串联模型的模型缩放。从(a)到(b),我们观察到当对基于级联的模型进行深度缩放时,计算块的输出宽度也会增加。这种现象会导致后续传输层的输入宽度增大。因此,我们提出(c),即对基于级联的模型进行模型缩放时,只需要对计算块中的深度进行缩放,其余的传输层进行相应的宽度缩放。
- 以上方法主要应用于诸如PlainNet、ResNet等架构中。当这些架构在执行放大或缩小时,每一层的入度和出度不会发生变化,因此我们可以独立分析每个缩放因子对参数量和计算量的影响。然而,如果将这些方法应用到基于级联的体系结构中,我们会发现当对深度进行放大或缩小时,位于基于级联的计算块之后的翻译层的程度会减小或增加,如图3(a)和(b)所示。
- 从上述现象可以推断,对于基于级联的模型,我们不能单独分析不同的缩放因素,而必须一起考虑。以放大深度为例,这种行为会导致过渡层的输入通道和输出通道之间的比率变化,这可能会导致模型的硬件使用量下降。因此,对于基于级联的模型,我们必须提出相应的复合模型缩放方法。当我们缩放一个计算块的深度因子时,我们还必须计算该块的输出通道的变化。然后,我们将对过渡层进行同样数量的改变,结果显示在图3(c)中。我们提出的复合缩放方法可以保持模型在初始设计时的属性,并保持最优结构。

4.训练技巧
4.1. 重新设计模型重参数化
- 虽然模型重参数化在VGG上已经取得了优异的性能,但是当我们将其直接应用于resnet和DenseNet等架构时,其精度会显著降低。
- 利用梯度流传播路径分析了不同网络下重新参数化卷积的应用。并据此重新设计了重参数化卷积。
- RepConv实际上是在一个卷积层中结合了3 × 3卷积、1 × 1卷积和恒等连接。通过分析RepConv与不同架构的结合及其性能,我们发现RepConv中的恒等连接消除了ResNet中的残差和DenseNet中的拼接,为不同的特征映射提供了更多的梯度多样性。
- 基于上述原因,我们使用无恒等连接的RepConvN来重新设计重参数化卷积的架构。 在我们的思维中,当一个带有残差或拼接结构的卷积层被重参数化的卷积所取代时,应该没有恒等连接。 图4显示了我们设计的在PlainNet和ResNet中使用的“规划的重新参数化卷积”的示例。关于基于残差模型和基于级联模型的完整规划的重新参数化卷积实验,将在消融研究环节中进行介绍。

4.2.粗标签用于辅助头、细标签用于引导头
- 深度监督是深度网络训练中常用的一种技术。 其主要思想是在网络的中间层增加辅助头部,以浅层网络权重和辅助损失作为指导。 即使对于ResNet和densenet这样通常收敛良好的架构,深度监督仍然可以显著提高模型在许多任务上的性能。 图5 (a)和(b)分别显示了“没有”和“有”深度监督的对象检测器架构。 在本文中,我们称负责最终输出的头部为引导头,称辅助训练的头部为辅助头。
- 接下来我们要讨论标签分配的问题。
- 在过去的深度网络训练中,标签分配通常直接引用GT(真实标签),并根据给定的规则生成硬标签。 然而,近年来,以目标检测为例,研究人员往往利用网络预测输出的质量和分布,再结合GT,采用一些计算和优化方法,生成一个可靠的软标签。 例如YOLO使用了边界盒回归预测IoU和GT作为客观性的软标签。 本文将综合考虑网络预测结果和GT并分配软标签的机制称为“标签分配器”。
- 无论辅助头或引导头的情况如何,都需要对目标进行深度监督训练。 在开发软标签赋值器相关技术的过程中,我们偶然发现了一个新的衍生问题,即: ,“如何给辅助头和引导头分配软标签?”据我们所知,目前相关文献还没有探讨这个问题。 目前最常用的方法的结果如图5(c)所示,将辅助头和引导头分开,利用各自的预测结果和GT来执行标签分配。
- 本文提出的方法是一种通过引导头预测的同时引导辅助头和引导头的标签分配新方法。 换句话说,我们以引导头预测结果为指导,生成粗到细的层次标签,分别用于辅助头和引导头学习。 提出的两种深度监督标签分配策略分别如图5 (d)和(e)所示。

- 引导头引导标签分配器主要根据引导头的预测结果和GT进行计算,通过优化过程生成软标签。 这套软标签将作为辅助头和引导头的目标训练模型。 这样做的原因是引导头具有较强的学习能力,由此产生的软标签应该更能代表源数据和目标数据之间的分布和相关性。 此外,我们可以把这种学习看作一种广义残差学习。 通过让较浅的辅助头直接学习引导头已经学习过的信息,引导头将更能专注于学习尚未学习的残差信息。
- 粗到细引导头引导标签分配器还利用引导头的预测结果和GT来产生软标签。 但是在这个过程中我们产生了两套不同的软标签,即粗标签和细标签,其中细标签与引导头标签分配器产生的软标签相同,而粗标签是通过放松正样本分配过程的约束,允许更多的网格被视为正目标而产生的。 这是因为辅助头的学习能力不如引导头强,为了避免丢失需要学习的信息,我们将重点在目标检测任务中优化辅助头的召回。 对于引导头的输出,我们可以从高查全率的结果中过滤出高精度的结果作为最终输出。但是,我们必须注意,如果粗标签的权重接近细标签的权重,可能会在最终预测时产生较差的结果。 因此,为了使粗标签的影响更小,我们在解码器中加入限制,使粗网格不能完美地产生软标签。 上述机制使细标签和粗标签的重要性在学习过程中动态调整,使细标签的可优化上界始终高于粗标签。
4.3. 其他可培训的免费技巧包
在本节中,我们将列出一些可培训的免费技巧包。 这些免费技巧包是我们在培训中使用的一些技巧,但最初的概念并不是我们提出的。 这些免费技巧包的训练细节将在附录中详细阐述。
包括:
(1)convn-bn-activation 拓扑结构中的Batch归一化:这部分主要是将Batch归一化层直接连接到卷积层。 这样做的目的是在推理阶段将批处理归一化的均值和方差整合到卷积层的偏差和权重中。
(2) YOLOR中的隐式知识结合卷积特征映射加乘法的方式:在推理阶段,通过预计算,可以将YOLOR中的隐式知识简化为向量。 该向量可以与前一层或后一层的偏差和权重相结合。
(3) EMA模型:EMA是在mean teacher中使用的一种技术,在我们的系统中,我们只使用EMA模型作为最终的推断模型。
5.实验结果
5.1. 实验设置
- 我们使用Microsoft COCO数据集进行实验,验证我们的目标检测方法。 我们所有的实验都没有使用预先训练的模型。 也就是说,所有的模型都是从头开始训练的。 在开发过程中,我们使用train2017训练集进行训练,然后使用val2017测试集进行验证和超参数的选择。 最后,我们展示了对象检测在2017测试集上的性能,并与最先进的对象检测算法进行了比较。 详细的训练参数设置在附录中描述。
- 我们设计了边缘GPU、普通GPU和云GPU的基本模型,分别称为YOLOv7-tiny、YOLOv7和YOLOv7-W6。 同时,我们还利用基础模型对不同的服务需求进行模型缩放,得到不同类型的模型。
- 在YOLOv7中,我们对颈部进行了叠加缩放,并使用提出的复合缩放方法对整个模型的深度和宽度进行缩放,从而得到YOLOv7-X。
- 对于YOLOv7-W6,我们采用新提出的复合缩放法得到YOLOv7-e6和YOLOv7-D6。
- 此外,我们将提出的E-ELAN用于YOLOv7-E6,从而完成YOLOv7-E6E。 由于YOLOv7-tiny是面向边缘gpu的架构,它将使用leaky ReLU作为激活函数。 对于其他模型,我们使用SiLU作为激活函数。 我们将在附录中详细描述每个模型的比例因子。
5.2. 基线
- 基线我们选择之前版本的YOLO和最先进的对象检测器YOLOR作为我们的基线。 表1显示了我们建议的YOLOv7模型与那些使用相同设置训练的基线的比较。
- 结果表明,与YOLOv4相比,YOLOv7的参数减少了75%,计算量减少了36%,AP增加了1.5%。与现有的YOLOR-CSP相比,YOLOv7的参数减少了43%,计算量减少了15%,AP增加了0.4%。
- 在微小模型性能上,与YOLOv4-tiny-31相比,YOLOv7 -tiny的参数减少了39%,计算量减少了49%,但AP不变。我们的模型在减少19%的参数数量和33%的计算量的同时仍然可以有一个较高的ap。

5.3. 与最新技术的比较
- 我们将本文提出的方法与通用gpu和移动gpu的最先进检测器进行了比较,结果如表2所示。 从表2的结果我们知道,我们提出的方法具有最好的速度和精度的综合权衡。
- 如果我们比较YOLOv7-tiny-SILU与YOLOv5-N (r6.1),我们的方法在速度上快127帧/秒在AP上高了10.7%。
- 此外,YOLOv7在161帧/秒的帧率下有51.4%的AP,而PPYOLOE-L在相同的AP上只有78帧/秒。
- 在参数使用方面,YOLOv7比PPYOLO-L低41%。 如果我们比较YOLOv7-X与YOLOv5-L (r6.1)的114帧/秒推断速度,YOLOv7-X可以提高3.9%的AP。 如果将YOLOv7-X与类似规模的YOLOv5-X (r6.1)进行比较,YOLOv7-X的推理速度要快31FPS。
- 此外,在参数和计算量方面,与YOLOv5-X (r6.1)相比,YOLOv7-X减少了22%的参数和8%的计算量,但提高了2.2%的AP。
- 在输入分辨率为1280的条件下比较YOLOv7和YOLOR, YOLOv7-W6的推理速度比YOLOR-P6快8fps,检出率也提高了1%AP,而YOLOv7-E6和YOLOv5-X6 (r6.1)的比较,前者比后者有0.9%AP增益,参数减少45%,计算量减少63%,推理速度提高了47%。 YOLOv7-D6与YOLOR-E6的推理速度相近,但AP提高了0.8%。 YOLOv7-E6E与YOLOR-D6的推理速度相近,但AP提高0.3%。

5.4. 消融实验
5.4.1 提出的复合尺度化方法
- 表3显示了使用不同模型缩放策略进行缩放的结果。 其中,我们提出的复合缩放方法是将计算块的深度扩大1.5倍,将过渡块的宽度扩大1.25倍。
- 如果与只扩大宽度的方法相比,我们的方法在参数较少、计算量较少的情况下,可使AP提高0.5%。
- 与仅增加深度的方法相比,只需增加2.9%的参数数和1.2%的计算量,可使AP提高0.2%。
- 从表3的结果可以看出,我们提出的复合缩放策略可以更有效地利用参数和计算。

5.4.2重新设计的重参数化模型
- 为了验证提出的模型重参数化的通用性,我们将其分别用于基于级联的模型和基于残差的模型进行验证。
- 我们选择的基于级联的模型和基于残差的模型分别是3层的ELAN和CSPDarknet。
- 在基于级联的模型实验中,我们将3层ELAN中不同位置的3×3卷积层替换为RepConv,具体配置如图6所示。 从表4所示的结果中,我们看到所有较高的AP值都出现在我们建议的重参数化的模型中。

- 在基于残差模型的实验中,由于原始的Dark block没有一个符合我们设计策略的3 × 3卷积块,所以我们为实验额外设计了一个反向的Dark block,其架构如图7所示。
- 由于CSPDarknet的Dark block和反向Dark block具有完全相同的参数和操作,所以比较是公平的。 表5所示的实验结果充分证实了所提出的重新参数化模型对基于残差的模型同样有效。 我们发现RepCSPResNet的设计也符合我们的设计模式。

5.4.3 为辅助头提出的指导损失
-
在辅助头的指导损失实验中,我们比较了一般的引导头独立标签分配方法和辅助头方法,并对两种提出的引导标签分配方法进行了比较。 我们在表6中展示了比较结果。 从表6中列出的结果可以清楚地看出,任何增加指导损失的模型都可以显著提高整体性能。
-
此外,我们提出的引导标签分配策略在AP、AP50和AP75中比一般的独立标签分配策略获得更好的性能。 对于我们提出的粗标签和细标签分配策略,在所有情况下都能得到最好的结果。
-
图8展示了在辅助头和引导头用不同方法预测的物化图。 从图8中我们发现,如果辅助头学习指导的软标签,确实可以帮助引导头从一致的目标中提取残差信息。


-
在表7中,我们进一步分析了所提出的粗到细引导标签分配方法对辅助头部解码器的影响。 也就是说,我们比较了引入上界约束和不引入上界约束的结果。 从表中的数字来看,用距离物体中心的距离来约束物体的上限的方法可以达到更好的效果。

-
由于提出的YOLOv7使用多个金字塔共同预测目标检测结果,我们可以直接将辅助头连接到中间层的金字塔进行训练。
-
这种类型的训练可以弥补在下一级金字塔预测中可能丢失的信息。
-
基于上述原因,我们在提出的E-ELAN架构中设计了部分辅助头。 我们的方法是在合并基数之前,在某一特征映射集后连接辅助头,这种连接可以使新生成的特征映射集的权值不被辅助损失直接更新。
-
我们的设计允许每个金字塔仍然从不同大小的物体中获取信息。 表8显示了两种不同方法的结果。 粗至细引导法和部分粗到细引导法。 显然,部分粗到细引导法具有更好的辅助效果。

6. 结论
- 本文提出了一种新的实时目标检测器体系结构和相应的模型缩放方法。 此外,我们发现目标检测方法的发展过程产生了新的研究课题。
- 在研究过程中,我们发现了重参数化模块的替换问题和动态标签分配的分配问题。 为了解决这一问题,我们提出了可训练的免费技巧包来提高目标检测的准确性。
- 在此基础上,我们开发了YOLOv7系列目标检测系统,得到了最先进的目标检测结果。
7. 致谢
作者希望感谢国家高性能计算中心(NCHC)提供计算和存储资源。
8. 更多的对比
- 在5帧/秒到160帧/秒的范围内,YOLOV7在速度和精度上超过了所有已知的物体检测器,在GPU V100上所有已知的30FPS或更高的实时物体检测器中具有最高的56.8% AP test-dev / 56.8% AP min-val。
- YOLOv7-e6对象检测器(56 FPS V100, 55.9% AP)在速度和精度上都比基于transformer的检测器SWIN-L Cascade-Mask R-CNN (9.2 FPSA100, 53.9% AP)快509%和高2%,和基于卷积的检测器convext-xl级联掩模R-CNN(86FPS,A100,55.2%AP)速度快551%,精度高0.7%AP。
- 此外YOLOV7在速度和精度方面优于:YOLOR,YOLO scale-yolov4,YOLOv5,DETR,Deformable DETR,DINO-5scale-R50,vita-adapter-b和许多其他对象测器。此外,我们只在MS COCO数据集上从头开始训练YOLOv7,而不使用任何其他数据集或预训练的权重。
 文章来源:https://www.toymoban.com/news/detail-446270.html
文章来源:https://www.toymoban.com/news/detail-446270.html
 文章来源地址https://www.toymoban.com/news/detail-446270.html
文章来源地址https://www.toymoban.com/news/detail-446270.html
- YOLOv7-E6E (56.8%AP)实时模型的最大精度比目前COCO数据集上最精确的美团/YOLOv6-s模型(43.1% AP)高出13.7% AP。 在COCO数据集和batch=32的V100 GPU上,我们的YOLOv7-tiny (35.2% AP, 0.4ms)模型比美团/YOLOv6-n (35.0% AP, 0.5 ms)快25%,高0.2%AP。


到了这里,关于YOLOV7详细解读(二)论文解读的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!