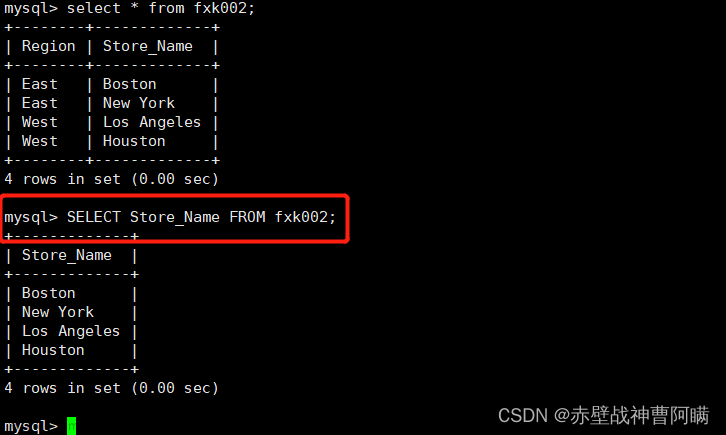
1.创建表以及数据:
DROP TABLE IF EXISTS `dealer_permissions`;
CREATE TABLE `dealer_permissions` (
`id` int(11) NOT NULL AUTO_INCREMENT COMMENT 'id',
`name` varchar(10) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL COMMENT '模块名称',
`parent_Id` int(11) NULL DEFAULT NULL COMMENT '父id',
`operation_value` int(1) NULL DEFAULT NULL COMMENT '操作值',
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 12 CHARACTER SET = utf8mb4 COLLATE = utf8mb4_general_ci ROW_FORMAT = Dynamic;
INSERT INTO `dealer_permissions` VALUES (1, '系统', NULL, NULL);
INSERT INTO `dealer_permissions` VALUES (2, '代理商', 1, NULL);
INSERT INTO `dealer_permissions` VALUES (3, '查询', 2, 100);
INSERT INTO `dealer_permissions` VALUES (4, '新增代理商', 2, 101);
INSERT INTO `dealer_permissions` VALUES (5, '密码还原', 2, 102);
INSERT INTO `dealer_permissions` VALUES (7, '修改', 2, 103);
INSERT INTO `dealer_permissions` VALUES (8, '代理商用户详情', 2, 104);
INSERT INTO `dealer_permissions` VALUES (9, '职员', 1, NULL);
INSERT INTO `dealer_permissions` VALUES (10, '查询', 9, 105);
INSERT INTO `dealer_permissions` VALUES (11, '新增', 9, 106);2.数据以及层次关系:

层次关系:

现在的需求是把这个层级关系,在前端显示出来,后端的处理方法有两种:
1.直接把全部的数据从数据库中拿到,然后在java代码里面使用树形结构来进行解析,但是这种做法只能在数据量比较小的时候使用,然后数据量一大会造成内存溢出
2.在mysql中创建一个函数,传递一个根节点的id,把对应的所有叶子节点的数据查出来(如果对用上述的图,就是把“系统”的id传递进去,把代理商,职员,以及各自对应的下级找出来)
今天就介绍第二种,在此之前先来的学一下两个函数:
find_in_set 函数
语法:find_in_set(str,strlist)
select * from dealer_permissions where FIND_IN_SET(id,'1,2,3');结果是返回id在表中的记录,即 id = '1' ,id = '2' ,id = '3' 三条记录。
可以使用函数:以向下递归查询所有子节点为例。只要找到一个包含当前节点和所有子节点的以逗号拼接的字符串 strlist,传进 find_in_set 函数。就可以查询出所有需要的递归数据了。

group_concat 函数(CONCAT_WS函数也是差不多的功能):
使用该函数,可以把表中的所有 id 以逗号拼接(该函数不只是这个作用,更多用处自行百度)
select GROUP_CONCAT(id) from dealer_permissions;

MySQL 自定义函数,实现递归查询
自定义一个函数,通过传入根节点id,找到它的所有子节点:
delimiter $$ drop function if exists get_child_list$$ create function get_child_list(in_id varchar(10)) returns varchar(1000) begin declare ids varchar(1000) default ''; declare tempids varchar(1000); set tempids = in_id; while tempids is not null do set ids = CONCAT_WS(',',ids,tempids); select GROUP_CONCAT(id) into tempids from dealer_permissions where FIND_IN_SET(parent_Id,tempids)>0; end while; return ids; end $$ delimiter ;
(1) delimiter
用于定义结束符。我们知道MySQL默认的结束符为分号,表明指令结束并执行。但是在函数体中,有时我们希望遇到分号不结束,因此需要暂时把结束符改为一个随意的其他值。我这里设置为$$ ,用于定义结束符。
(2)drop function if exists get_child_list
若函数getchildlist已经存在了,则先删除它。注意这里需要用当前自定义的结束符 来结束并执行语句。 因为,这里需要和下边的函数体单独区分开来。
(3)create function get_child_list
创建函数。并且参数传入一个根节点的子节点id,需要注意一定要注明参数的类型和长度,如这里是 varchar(10)。然后returns varchar(1000) 用来定义返回值参数类型。
(4)begin 和 end
中间包围的就是函数体。用来写具体的逻辑。
(5)declare
用来声明变量,并且可以用 default 设置默认值。 这里定义的 ids 即作为整个函数的返回值,是用来拼接成最终我们需要的以逗号分隔的递归串的。 而 tempids 是为了记录下边 while 循环中临时生成的所有子节点以逗号拼接成的字符串。
(6) set
用来给变量赋值。此处把传进来的根节点赋值给 tempids 。
(7) while do ... end
while; 循环语句,循环逻辑包含在内。注意,end while 末尾需要加上分号。 循环体内,先用 CONCAT_WS 函数把最终结果 ids 和 临时生成的 tempids 用逗号拼接起来。 然后以 FIND_IN_SET(parent_Id,tempids)>0 为条件,遍历在 tempids 中的所有 parent_Id,寻找以此为父节点的所有子节点 id ,并且通过 GROUP_CONCAT(id) into tempids 把这些子节点 id 都用逗号拼接起来,并覆盖更新 tempids 。
等下次循环进来时,就会再次拼接 ids ,并再次查找所有子节点的所有子节点。循环往复,一层一层的向下递归遍历子节点。直到判断 tempids 为空,说明所有子节点都已经遍历完了,就结束整个循环。
这里,用 '1' 来举例,即是:(参看图1的表数据关系)
第一次循环: tempids=1 ids=1 tempids=2,9(1的所有子节点)
第二次循环: tempids=2,9 ids=1,2,9
tempids=3,4,5,6,7,8,10,11 (2和9 的所有子节点)
第三次循环: tempids=3,4,5,6,7,8,10,11 ids=1,2,9,3,4,5,6,7,8,10,11 tempids=3,4,5,6,7,8,10,11的所有子节点 因找不到任何一个子节点,所以 tempids=null,就结束循环。
(8)return ids;
用于把 ids 作为函数返回值返回。
(9)函数体结束以后,记得用结束符 $$ 来结束整个逻辑,并执行。
(10)最后别忘了,把结束符重新设置为默认的结束符分号 。
执行代码:
select * from dealer_permissions where FIND_IN_SET(id,get_child_list('1'));
可以看到,已经把需要找的数据找到了,然后在java中用代码做相对应的处理即可

手动实现递归查询(向上递归)
相对于向下递归来说,向上递归比较简单。
因为向下递归时,每一层递归一个父节点都对应多个子节点。
而向上递归时,每一层递归一个子节点只对应一个父节点,关系比较单一。
同样的,我们可以定义一个函数 get_parent_list 来获取根节点的所有父节点。
delimiter $$ drop function if exists get_parent_list$$ create function get_parent_list(in_id varchar(10)) returns varchar(1000) begin declare ids varchar(1000); declare tempid varchar(10); set tempid = in_id; while tempid is not null do set ids = CONCAT_WS(',',ids,tempid); select parent_Id into tempid from dealer_permissions where id=tempid; end while; return ids; end $$ delimiter ; select * from dealer_permissions where FIND_IN_SET(id,get_parent_list('11'));执行的结果:

注意事项:
我们用到了 group_concat 函数来拼接字符串。但是,需要注意它是有长度限制的,默认为 1024 字节。可以通过 show variables like "group_concat_max_len"; 来查看。
注意,单位是字节,不是字符。在 MySQL 中,单个字母占1个字节,而我们平时用的 utf-8下,一个汉字占3个字节。
这个对于递归查询还是非常致命的。因为一般递归的话,关系层级都比较深,很有可能超过最大长度。(尽管一般拼接的都是数字字符串,即单字节)
所以,我们有两种方法解决这个问题:
1. 修改 MySQL 配置文件 my.cnf ,增加 group_concat_max_len = 102400 #你要的最大长度. 2.执行以下任意一个语句。SET GLOBAL group_concat_max_len=102400; 或者 SET SESSION group_concat_max_len=102400;他们的区别在于,global是全局的,任意打开一个新的会话都会生效,但是注意,已经打开的当前会话并不会生效。而 session 是只会在当前会话生效,其他会话不生效。
共同点是,它们都会在 MySQL 重启之后失效,以配置文件中的配置为准。所以,建议直接修改配置文件。102400 的长度一般也够用了。假设一个id的长度为10个字节,也能拼上一万个id了。
除此之外,使用 group_concat 函数还有一个限制,就是不能同时使用 limit 。如,
本来只想查5条数据来拼接,现在不生效了。

不过,如果需要的话,可以通过子查询来实现,

查看自定义函数:
show function status;
删除自定义函数:
drop function 函数名;
在mybatis-plus中获取结果:
先把自定义的方法在mysql中执行先,然后我们在这个表对应的mapper文件中:
使用@select注解,把要执行的语句添加进去
/** * 获取id下的所有子节点 */ @Select("select * from dealer_permissions where FIND_IN_SET(id,get_child_list(#{id}));") List<DealerPermissionsModel> getAllByIdLower(@RequestParam(value = "id") Integer id);

通过代码把返回的结果转成树:
// 获取到了1节点下的所有数据(包括本节点) List<DealerPermissionsModel> allByIdLower = permissionsMapper.getAllByIdLower(1);
allByIdLower集合中就包括了以上的数据,现在通过stream流的方式,把结果转成树
先定义一个方法:
/** * 链表转树 * @return */ public static List<DealerPermissionsModel> listToTree(DealerPermissionsModel root,List<DealerPermissionsModel> list) { return list.stream() .filter(a -> Objects.equals(a.getParentId(), root.getId())) .peek(m -> m.setModelList(listToTree(m, list))) .collect(Collectors.toList()); }调用方法:
// 获取到了1节点下的所有数据(包括本节点) List<DealerPermissionsModel> allByIdLower = permissionsMapper.getAllByIdLower(1); // 排序成树的形式返回 List<DealerPermissionsModel> collect = allByIdLower .stream() .filter(a -> a.getParentId() == null) .peek(m -> m.setModelList(listToTree(m, allByIdLower))) .collect(Collectors.toList());输出collect:

方法的详解:
首先通过:
List<DealerPermissionsModel> collect = allByIdLower .stream() .filter(a -> a.getParentId() == null) .peek(m -> m.setModelList(listToTree(m, allByIdLower))) .collect(Collectors.toList());上面这段代码会进入了listToTree方法,此时的m是父节点为null的元素,因为经过了
filter(a -> a.getParentId() == null) 筛选,所以第一次进入listToTree方法的肯定是最顶层的父元素(对应到数据中,就是名称为 "系统" 的 数据)
然后就进入了listToTree,这个时候的listToTree方法的roo节点是名称为 "系统" 的数据,list是全部的数据,然后循环list集合通过filter来寻找list中有哪个元素的父节点等于root节点的id的数据(在这一步实际上就是循环找"系统"元素的一个子节点)循环到list的第二个元素的时候(第二个元素是名称为"代理商"的元素),因为“代理商”的父id是1,系统的id也是1,所以满足元素的父节点的id等于root的id条件,所以就会执行peek方法,然后把当前元素(名称为"代理商"的元素)以及list集合传递到listToTree方法
再一次进入到listToTree后,此时的root节点就是(名称为"代理商"的元素),然后又进行filter方法来循环查询父节点是代理商的元素,经过循环会找到(id为3,名称为"查询")的元素,然后就会通过peek方法来查询该元素有那个子节点,如果找不到就返回,就这样子递归寻找下去...文章来源:https://www.toymoban.com/news/detail-446497.html

以上就是全部内容,如果觉得对您有帮助,可以点个赞👍喔文章来源地址https://www.toymoban.com/news/detail-446497.html
到了这里,关于mysql数据库递归查询树形结构(适用场景:菜单多级分类,多级关联评论查询),用strea流把list转成树的方法详解的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!