目录
--------------------------------------目录------------------------------------------
图的定义和术语
图的邻接矩阵构建法
深度优先遍历算法(DFS)
广度优先遍历算法 (BFS)
全部代码
图的定义和术语
图:G = (V,E) V:顶点的有穷非空集合 E:边的有穷集合
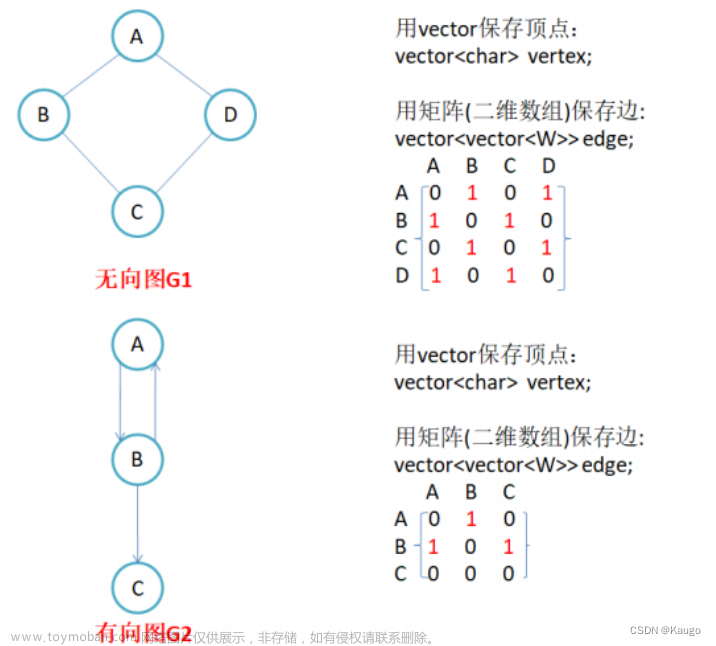
无向图:每条边都是无向的
有向图:每条边都是有方向的
邻接:有边相连的两个顶点之间的关系

图的邻接矩阵构建法
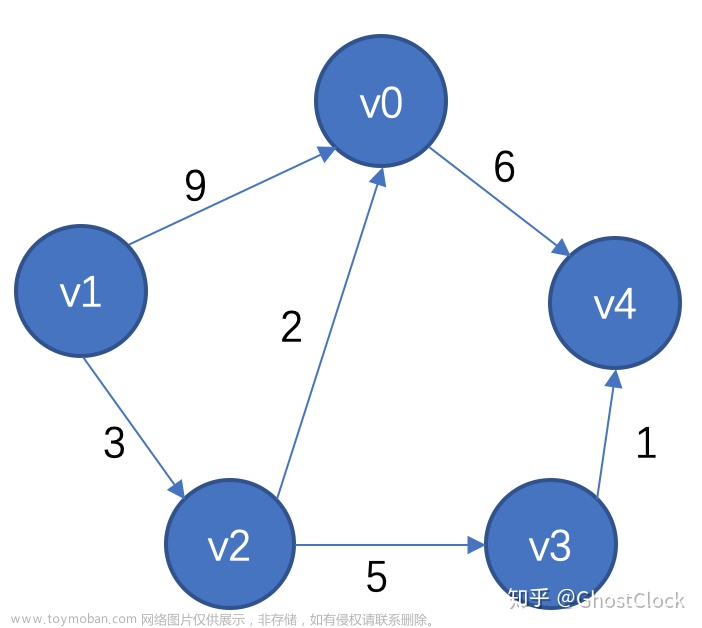
想要构建图,则首先得知道图的存储结构,从上图可以看出,我们需要有个数组存储各个顶点的数据,如v1、v2、v3等等。。再者因为我们今天要用邻接矩阵来表示图,所以我们需要个二维数组,再为了方便,我们需要再设两个变量,表示现有的结点与边,可以不难看出是个结构体结构,如下图:
#define MVNUM 100 //最大顶点数
typedef struct
{
char vexs[MVNUM]; //顶点数据数组
int arr[MVNUM][MVNUM]; //邻接矩阵
int vexnum, arcnum; //现有顶点数与边数
}AMGraph; 假设我们现在顶点数为5个,边数为5,顶点数据为 a,b,c,d,e,矩阵元素都为无穷,并定义个结构体变量则结构表示出来为:

存储结构知道后,我们就可以对它进行初始化操作啦,而我们的初始化操作,就是对照上图,其中数字,数据都是随机的,根据你的喜好,并且你还可以美化它,这里不多赘述,下面为思想:
1、确定顶点数和边数,
2、给顶点表赋值
3、arr二维数组都初始化为极大值(这里的极大值一般为int的最大值32767,而上图为了美观写成∞)表示现在每个顶点之间都没有线(关系),我们接下来构造就是加线操作而已。
#define MAXINT 32767 //极大值相当于无穷大
int initGraph(AMGraph& G)
{
cout << "please input some vexnum and arcnum!" << endl;
cin >> G.vexnum >> G.arcnum; //输入你想要的顶点数和边数
cout << "please input data of vex!" << endl;
for (int i = 0; i < G.vexnum; i++)
{
cin >>G.vexs[i]; //输入顶点数据
}
for (int i = 0; i < G.vexnum; i++)
{
for (int j = 0; j < G.vexnum; j++)
{
G.arr[i][j] = MAXINT; //邻接矩阵的初值都为无穷大
}
}
return 1;
}初始化完成后,我们就可以,看看自己邻接矩阵长什么样啦,写一个遍历二维数组的算法(比较简单,这里就不写了),而后就是构造顶点之间的联系,思想就是:
1、先输入两个点(这两个点是邻接的,就是有关系的),并赋予权值,
2、用这两个点去顶点表里去找,找到了返回对应坐标
3、找到坐标后就在矩阵(二维数组)对应下标赋值
4、因为为无向图,则为对称的,所以行列坐标对换后再赋值一遍即可(如为有向图这步省略)
int locateVex(AMGraph G, char u)
{
for (int i = 0; i < G.vexnum; i++)
{
if (u == G.vexs[i]) //如果u的值和顶点数据匹配,就返回顶点在矩阵中的下标
return i;
}
return -1;
}
int createGraph(AMGraph& G)
{
int i = 0; int j = 0;int w = 0; //i,j代表顶点下标,w代表权值
char v1 = 0; char v2 = 0; //v1,v2为顶点数据
cout << "please input w of v1 to v2 in graph!" << endl;
for (int k = 0; k < G.arcnum; k++)
{
cin >> v1 >> v2 >> w;
i = locateVex(G, v1); //找到v1在顶点表的下标,并返回赋值给i
j = locateVex(G, v2); //找到v2在顶点表的下标,并返回赋值给j
G.arr[i][j] = w;
G.arr[j][i] = G.arr[i][j]; //无向图的矩阵是对称矩阵
}
cout << endl;
return 1;
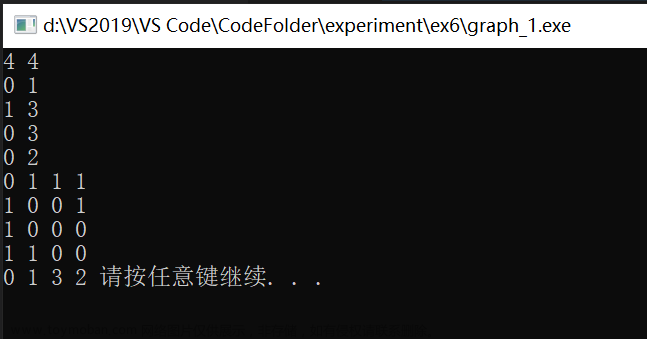
}假设我们现在按照 下面这个图来构建邻接矩阵,则结果为:


深度优先遍历算法(DFS)
深度优先算法就是一条路走到黑,走不下去就回来换条路的人性化算法,也是我这种路痴的常用探路的方法。
1、即随机选个顶点,
2、顺着与它有联系的点走下去,发现走不下去了,就回退一个顶点
3、如此如此最后再回退到当初选的第一个点
从步骤看出我们只是要去下一个顶点,然后用相同的方法再去下一个顶点,则我们可以用递归算法,可以用栈写出来(非递归),也可以用本来有的栈来做(递归)


走不下去了,退一格,再去没访问过的顶点,访问过的点不访问。

依次下去,直至最后一个点都访问了,然后顺着原路返回。

实现代码则需要一个辅助数组,这个数组作用是表示这个顶点是否被访问过了没,这里我们用0代表没访问过1反之,既然是递归,我们要有个递归的结束条件,可以不难看出走不下去即为结束条件,这时会有两种情况,一是没有邻接的顶点了,或者是邻接的顶点已经访问过了,那我们根据这个特性就不难写出代码了。
1、随机选个顶点
2、打印这个顶点,并设置为访问过了
3、如果还有邻接的顶点并且未访问过,递归函数
int visited[MVNUM] = { 0 }; //辅助数组
void dfsAM(AMGraph G, int i)
{//随机选一个顶点下标,这里为0
cout << G.vexs[i]<<" "; //输出0下标在顶点表的值
visited[i] = 1; //辅助数组对应下标i的值置为1
for (int j = 0; j < G.vexnum; j++)
{
if (G.arr[i][j] != MAXINT && (!visited[j])) //只要是邻接的顶点并且没有访问过
{ //不然就退回,也是递归结束条件
dfsAM(G, j); //递归使用函数
}
}
}

广度优先遍历算法 (BFS)
广度优先遍历也是先随机选个点,先让这个点的所有邻接点都访问一遍,然后从第一个访问的点再去访问它所有的邻接点,依次下去,到最后一个点都访问过为至。

那我们要怎么实现这个算法呢,从第二个图那个矩阵内部图结果可以看出,如果我们要使用广度优先遍历的话,救得一次性把第0行的所有邻接点都访问一遍,然后就是第1行,依次下去,那就是说我们就让这些行数排排队,只要每个行都能把邻接点都访问一遍就可以啦。
顺着这个思想,我们就要去想那怎么知道这一行的邻接点呢,答案是我们应该写个函数,去获取第一个邻接点的坐标,然后再写个函数得到下一个邻接点的坐标,直到没有邻接点了,那我们就去访问下一行,那我们怎么去访问下一行呢,上面讲到了排队,所以我们就可以写一个队列,让现在访问的行入队,因为我们知道这个矩阵是个方阵所以行和列是对应的,就是顶点数据对应的行坐标就是顶点数据的列坐标。
举个例子,现在是访问0行的1列那对应的就是顶点数据b这个元素,那我们就把b在矩阵中对应的列下标入列,虽然这是列下标,但是实际上也是数据b在矩阵中对应的行下标,所以我们出队的时候其实就是访问b在矩阵中对应的行下标。
算法步骤:
1、输出随机访问的顶点数据,并让其对应的辅助数组下标置为1
2、让顶点下标入队
3、 队不为空,出队,并把出队元素保存
4、访问第一个邻接点,并打印其顶点数据,然后让其对应的辅助数组下标置为1
5、入队,访问下一邻接点,如此反复直至队空
void bfsAM(AMGraph G, int i)
{//随机选一个顶点下标,这里为0
cout << G.vexs[i] << " "; //输出i下标在顶点表的值
visit[i] = 1; //辅助数值对应下标i的值置为1
sqQueue Q;
initQueue(Q);
enQueue(Q, i); //i为矩阵中顶点的行下标,让它入队(顶点表的下标和矩阵的列下标,行下标一致,本算法中说谁的下标都一样)
while (Q.rear != Q.front) //队不为空
{
int u = 0; //接收矩阵中顶点的行下标,因为是邻接矩阵
deQueue(Q,u); //出队并让u接收矩阵中顶点的行下标
for (int w = firstVEX(G, u); w != MAXINT; w = nextVEX(G, w, u))
{//注意在一次循环中u不变
if (!visit[w])
{
cout << G.vexs[w] << " ";
visit[w] = 1;
enQueue(Q, w);
}
}
}
}

全部代码
#define _CRT_SECURE_NO_WARNINGS 1
#include <iostream>
using namespace std;
#define MVNUM 100 //最大顶点数
#define MAXINT 32767 //极大值相当于无穷大
int visited[MVNUM] = { 0 }; //辅助数组,判断遍历过了没
int visit[MVNUM] = { 0 }; //同理
typedef struct
{
char vexs[MVNUM]; //顶点数据数组
int arr[MVNUM][MVNUM]; //邻接矩阵
int vexnum, arcnum; //现有顶点数与边数
}AMGraph;
typedef struct
{
int* base; //队列数组
int front; //队头的下标
int rear; //队尾的下标
}sqQueue;
int initGraph(AMGraph& G); //初始化邻接矩阵
void showGraph(AMGraph G); //打印邻接矩阵
int locatVex(AMGraph G, char u); //定位顶点在邻接矩阵的下标
int createGraph(AMGraph& G); //建立邻接矩阵
void dfsAM(AMGraph G,int i); //深度优先搜索遍历
void bfsAM(AMGraph G, int i); //广度优先搜索遍历
int initQueue(sqQueue& Q); //初始化队列
int enQueue(sqQueue& Q, int i); //入队
int firstVEX(AMGraph G, int u); //第一个邻接顶点
int nextVEX(AMGraph G,int w ,int u); //下一个邻接顶点
int main()
{
AMGraph G;
initGraph(G);
createGraph(G);
showGraph(G);
cout << "the result of dfs is:";
dfsAM(G,0);
cout << endl;
cout << "the result of bfs is:";
bfsAM(G,0);
}
int initGraph(AMGraph& G)
{
cout << "please input some vexnum and arcnum!" << endl;
cin >> G.vexnum >> G.arcnum; //输入你想要的顶点数和边数
cout << "please input data of vex!" << endl;
for (int i = 0; i < G.vexnum; i++)
{
cin >>G.vexs[i]; //输入顶点数据
}
for (int i = 0; i < G.vexnum; i++)
{
for (int j = 0; j < G.vexnum; j++)
{
G.arr[i][j] = MAXINT; //邻接矩阵的初值都为无穷大
}
}
return 1;
}
void showGraph(AMGraph G)
{
for (int i = 0; i < G.vexnum; i++)
{
for (int j = 0; j < G.vexnum; j++)
{
if (G.arr[i][j] == MAXINT) //无穷大弄得更好看点
cout << "∞" << " ";
else
cout << " " << G.arr[i][j] << " ";
}
cout << endl;
}
cout << endl;
}
int locateVex(AMGraph G, char u)
{
for (int i = 0; i < G.vexnum; i++)
{
if (u == G.vexs[i]) //如果u的值和顶点数据匹配,就返回顶点在矩阵中的下标
return i;
}
return -1;
}
int createGraph(AMGraph& G)
{
int i = 0; int j = 0;int w = 0; //i,j代表顶点下标,w代表权值
char v1 = 0; char v2 = 0; //v1,v2为顶点数据
cout << "please input w of v1 to v2 in graph!" << endl;
for (int k = 0; k < G.arcnum; k++)
{
cin >> v1 >> v2 >> w;
i = locateVex(G, v1); //找到v1在顶点表的下标,并返回赋值给i
j = locateVex(G, v2);
G.arr[i][j] = w;
G.arr[j][i] = G.arr[i][j]; //无向图的矩阵是对称矩阵
}
cout << endl;
return 1;
}
void dfsAM(AMGraph G, int i)
{//随机选一个顶点下标,这里为0
cout << G.vexs[i]<<" "; //输出0下标在顶点表的值
visited[i] = 1; //辅助数组对应下标i的值置为1
for (int j = 0; j < G.vexnum; j++)
{
if (G.arr[i][j] != MAXINT && (!visited[j])) //只要是邻接的顶点并且没有访问过
{ //不然就退回,也是递归结束条件
dfsAM(G, j); //递归使用函数
}
}
}
int initQueue(sqQueue& Q)
{
Q.base = (int *)malloc(sizeof(int) * MVNUM);
//给base动态分配一个int*类型MVNUM个int大小的一维数组空间
Q.front = Q.rear = 0; //队头和对尾下标都置为0
return 1;
}
int enQueue(sqQueue& Q, int i)
{
if ((Q.rear + 1) % MVNUM == Q.front) //队满
return 0;
Q.base[Q.rear] = i; //先赋值再加
Q.rear = (Q.rear + 1) % MVNUM;
return 1;
}
int deQueue(sqQueue& Q, int &u)
{
if (Q.rear == Q.front) //队空
return 0;
u = Q.base[Q.front]; //要删的值给u然后再加
Q.front = (Q.front + 1) % MVNUM;
return 1;
}
int firstVEX(AMGraph G, int u)
{//在邻接矩阵u行0列开始遍历,如果找到不等于无穷的,
//并且没有访问过的就返回列的下标,否则就返回无穷
for (int i = 0; i < G.vexnum; i++)
{
if (G.arr[u][i] != MAXINT && visit[i] == 0)
{
return i;
}
}
return MAXINT;
}
int nextVEX(AMGraph G, int w, int u)
{//在邻接矩阵u行w+1列开始遍历,如果找到不等于无穷的,
//并且没有访问过的就返回列的下标,否则就返回无穷
for (int i = w + 1; i < G.vexnum; i++)
{
if (G.arr[u][i] != MAXINT && visit[i] == 0)
{
return i;
}
}
return MAXINT;
}
void bfsAM(AMGraph G, int i)
{//随机选一个顶点下标,这里为0
cout << G.vexs[i] << " "; //输出i下标在顶点表的值
visit[i] = 1; //辅助数值对应下标i的值置为1
sqQueue Q;
initQueue(Q);
enQueue(Q, i); //i为矩阵中顶点的行下标,让它入队(顶点表的下标和矩阵的列下标,行下标一致,本算法中说谁的下标都一样)
while (Q.rear != Q.front) //队不为空
{
int u = 0; //接收矩阵中顶点的行下标,因为是邻接矩阵
deQueue(Q,u); //出队并让u接收矩阵中顶点的行下标
for (int w = firstVEX(G, u); w != MAXINT; w = nextVEX(G, w, u))
{//注意在一次循环中u不变
if (!visit[w])
{
cout << G.vexs[w] << " ";
visit[w] = 1;
enQueue(Q, w);
}
}
}
}

发这个也是为了理清自己的思路,顺带一起学习下,继续学习咯,加油陌生人!!文章来源:https://www.toymoban.com/news/detail-446607.html
学自严老师的教材---------------------------------------------------------------------------------------------------------文章来源地址https://www.toymoban.com/news/detail-446607.html
到了这里,关于利用邻接矩阵进行的深度优先和广度优先遍历(含全部代码+图解)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!