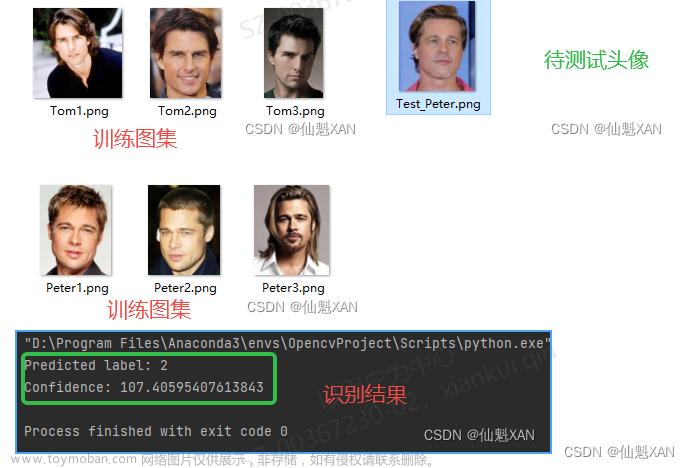
一、准备数据
1.利用人脸检测方法,先将图像的人脸部分截取成图像
2.批量读取图像,制作成图像与标签对应的列表
二、开始训练
3.训练(使用opencv自带的训练方法)
4.调用
HOG人脸检测器
1.利用人脸检测方法,先将图像的人脸部分截取成图像
选用HOG的目的是为了方便而已,你完全可以使用别的方法。
代码文件名:SB1
# 人脸检测:
# 输入 一张图像
# 输出:零至多张人脸图像列表
import cv2
import dlib
def cv_show(neme, img):
cv2.namedWindow(neme, cv2.WINDOW_NORMAL)
cv2.imshow(neme, img)
cv2.waitKey(0)
cv2.destroyAllWindows()
class d():
def __init__(self):
# 构造HOG人脸检测器
self.hog_face_detetor = dlib.get_frontal_face_detector()
def d1(self, img):
# 检测人脸
# scale 类似haar的scaleFactor
detections = self.hog_face_detetor(img, 1)
# 人脸图像列表
img_list = []
# 解析矩形结果
for face in detections:
# 根据测试 出现了一次 x是负值的情况,所以采用绝对值
x = abs(face.left())
y = abs(face.top())
r = abs(face.right())
b = abs(face.bottom())
# 截取人脸
img_crop = img[y:b, x:r]
# 缩放解决冲突
img_crop = cv2.resize(img_crop, (120, 120))
# 绘制 人脸矩形框
# cv2.rectangle(img, (x, y), (r, b), (0, 255, 0), 5)
# 显示 绘制后的图像
# cv_show('neme', img_crop)
img_list.append(img_crop)
return img_list
if __name__ == '__main__':
# 读取图片
img = cv2.imread('./images_1/Yamy/Yamy_0.jpg')
p = d().d1(img)
for i in p:
print(i.shape)
批量读取图像
2.批量读取图像,制作成图像与标签对应的列表
这里是我自己手写的,没有考虑 时间复杂度与空间复杂度,你可以用其他现有的库的API,或者自己写个更好的。
文件目录结构:images_1文件夹下,存放n个文件夹,对应着n个类别,
代码文件名:SB2
# 批量读取数据
# 训练人脸识别
import os
import cv2
import SB1
def cv_show(neme, img):
cv2.namedWindow(neme, cv2.WINDOW_NORMAL)
cv2.imshow(neme, img)
cv2.waitKey(0)
cv2.destroyAllWindows()
def r_path_name(path):
list_img = os.listdir(path)
# 人脸检测 创建
p = SB1.d()
# 人脸列表
person = []
# 标签列表
lab = []
# 标签号
lab_n = 0
for i in range(len(list_img)):
list_img_name = os.listdir(path + list_img[i])
lab_n += 1
for j in list_img_name:
path_n = path + list_img[i] + "/" + j
# 读取图片
img = cv2.imread(path_n)
# 灰度化 训练要求使用单通道图像:
# 转为灰度图
img = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# cv_show('neme', img)
# 人脸检测
img_ = p.d1(img)
if len(img_) != 0:
for img in img_:
# 放入人脸列表
person.append(img)
# 放入标签列表
lab.append(lab_n)
# print(person)
# print(lab)
#
# print(len(lab))
# print(len(person))
return person, lab
if __name__ == '__main__':
path = "./images_1/"
img, lab = r_path_name(path)
print(len(img))
print(len(lab))
训练
读取的图像目录名:images_1
保存模型路径与名称:./weights/LBPH1.yml
代码文件名:SB3文章来源:https://www.toymoban.com/news/detail-446647.html
import cv2
import numpy as np
import SB2
# 构造分类器
face_cls = cv2.face.LBPHFaceRecognizer_create()
# cv2.face.EigenFaceRecognizer_create()
# cv2.face.FisherFaceRecognizer_create()
path = "./images_1/"
img_list, label_list = SB2.r_path_name(path)
# 训练 图像列表、标签列表、
face_cls.train(img_list, np.array(label_list))
# 保存模型
face_cls.save('./weights/LBPH1.yml')
调用
读取训练好的模型,进行加载,预测文章来源地址https://www.toymoban.com/news/detail-446647.html
# 进行人脸识别
import cv2
import SB1
img = cv2.imread('./images_1/Angelababy/a1.jpg')
# 转为灰度图
img = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# 调用模型
new_cls = cv2.face.LBPHFaceRecognizer_create()
new_cls.read('./weights/LBPH1.yml')
# 人脸检测
img_list = SB1.d().d1(img)
if len(img_list) != 0:
for i in img_list:
# 预测
predict_id, distance = new_cls.predict(img)
# 类别
print(predict_id)
# 置信度 低于50最优 高于80很差
print(distance)
# 基于LBPH的人脸识别操作原理
#
# 1、LBPH(Local Binary Pattern Histogram)将检测到的人脸分为小单元,并将其与模型中的对应单元进行比较,对每个区域的匹配值产生一个直方图。
#
# 由于这种方法的灵活性,LBPH 是唯一允许模型样本人脸和检测到的人脸在形状、大小上可以不同的人脸识别算法。
#
# 2、调整后的区域中调用 predict()函数
#
# predict()函数返回两个元素的数组:第一个元素是所识别 个体的标签,第二个是置信度评分。
#
# 3、所有的算法都有一个置信度评分阈值,置信度评分用来衡量所识别人脸与原模型的差距,0 表示完全匹配。可能有时不想保留所有的识别结果,则需要进一步处理,因此可用自己的算法来估算识别的置信度评分。
#
# 4、LBPH一个好的识别参考值要低于 50 ,任何高于 80 的参考值都会被认为是低的置信度评分。
到了这里,关于人脸识别(opencv--LBPH方法训练)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!