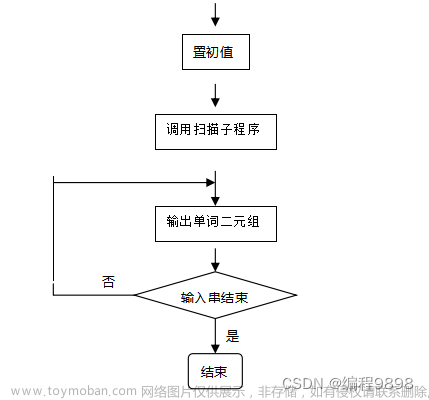
LR语法分析器
- 自顶向下的、不断归约的、基于句柄识别自动机的、适用于LR(∗) 文法的、LR(∗) 语法分析器
- 只考虑无二义性的文法
1. 构建语法树过程
- 自底向上构建语法分析树
- 根节点是文法的起始符号 S S S
- 每个中间非终结符节点表示使用它的某条产生式进行归约
- 叶节点是词法单元$w$$
- 仅包含终结符号与特殊的文件结束符$$$
1.1. 自顶向下的"推导"与自底向上的"归约"
E ⇒ r m T ⇒ r m T ∗ F ⇒ r m T ∗ i d ⇒ r m F ∗ i d ⇒ r m i d ∗ i d E \xRightarrow[rm]{} T \xRightarrow[rm]{} T * F \xRightarrow[rm]{} T * id \xRightarrow[rm]{} F * id \xRightarrow[rm]{} id * id ErmTrmT∗FrmT∗idrmF∗idrmid∗id

E ⇐ T ⇐ T ∗ F ⇐ T ∗ i d ⇐ F ∗ i d ⇐ i d ∗ i d E \Leftarrow T \Leftarrow T * F \Leftarrow T * id \Leftarrow F * id \Leftarrow id * id E⇐T⇐T∗F⇐T∗id⇐F∗id⇐id∗id
第一个生成式的左侧是开始符号
1.2. 推导与归约
- 从产生式的角度看,是推导: A → α A \rightarrow \alpha A→α
- 从输入的角度看,是规约: A ← α A \leftarrow \alpha A←α
A ≜ γ 0 ⇒ . . . γ i − 1 ⇒ γ i ⇒ γ r + 1 ⇒ . . . ⇒ r n = w A ≜ γ 0 ⇐ . . . γ i − 1 ⇐ γ i ⇐ γ r + 1 ⇐ . . . ⇐ r n = w \begin{array}{l} A \triangleq \gamma_{0} \Rightarrow ... \gamma_{i-1} \Rightarrow \gamma_i \Rightarrow \gamma_{r+1} \Rightarrow ... \Rightarrow r_n = w \\ A \triangleq \gamma_{0} \Leftarrow ... \gamma_{i-1} \Leftarrow \gamma_i \Leftarrow \gamma_{r+1} \Leftarrow ... \Leftarrow r_n = w \\ \end{array} A≜γ0⇒...γi−1⇒γi⇒γr+1⇒...⇒rn=wA≜γ0⇐...γi−1⇐γi⇐γr+1⇐...⇐rn=w
- 自底向上语法分析器为输入构造反向推导
1.3. LR(∗)语法分析器
-
L:从左向右(left-to-right) 扫描输入
-
R:构建反向(reverse)最右(leftmost)推导
-
在最右推导中, 最左叶节点最后才被处理
-
在反向最右推导中, 最左叶节点最先被处理(与从左到右扫描一致)
1.3.1. LR语法分析器的状态
- 在任意时刻, 语法分析树的上边缘与剩余的输入构成当前句型,也就是LR语法分析器的状态。

E ⇐ T ⇐ T ∗ F ⇐ T ∗ i d ⇐ F ∗ i d ⇐ i d ∗ i d E \Leftarrow T \Leftarrow T * F \Leftarrow T * id \Leftarrow F * id \Leftarrow id * id E⇐T⇐T∗F⇐T∗id⇐F∗id⇐id∗id
- LR语法分析器使用栈存储语法分析树的上边缘
1.3.2. 栈上操作

栈操作如下图所示:标号不是状态,仅表示顺序
| 时间序号 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 栈顶 | id | F | ||||||||||||
| * | * | * | * | |||||||||||
| 栈底 | id | F | T | T | T | T | T | T | E |
- 两大操作: 移入输入符号与按产生式归约
- 直到栈中仅剩开始符号S, 且输入已结束, 则成功停止
2. 基于栈的LR语法分析器
- Q1:何时归约? (何时移入?):要么是移入,要么是归约,而并不允许可以选择,不然是文法上的冲突。
- Q2:按哪条产生式进行归约?
- Q:为什么第二个F以 T ∗ F 整体被归约为T?
- A:这与栈的当前状态T ∗ F相关
2.1. LR分析表指导LR语法分析器
 |
 |
|---|
- 在当前状态(编号)下, 面对当前文法符号时, 该采取什么动作
- ACTION表指明动作, GOTO表仅用于归约时的状态转换
- LR(0)、SLR(1)、LR(1)、LALR(1)的分析表会略有差异,加强规则会使其可以处理更多的文法。
2.2. Definition (LR(0)文法)
- 如果文法G的LR(0)分析表是无冲突的, 则G是LR(0)文法。
- 无冲突: ACTION表中每个单元格最多只有一种动作
- 两类可能的冲突: “移入/归约” 冲突、“归约/归约” 冲突
2.3. 再次板书演示"栈" 上操作: 移入与规约
 |
|
|---|
- 状态只和栈之中的元素有关,如果弹出了,则重置状态为当前栈内状态,上面的序号只表示顺序,当前栈的状态,如()所示。
- 在5时刻遇到了$符号,进行操作
| 时间序号 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 状态 | 0 | 5 | 0 | 3 | 0 | 2 | 7 | 5 | 7 | 10 | 0 | 2 | 0 | 1 |
| 栈顶 | id | F | ||||||||||||
| * | * | * | * | |||||||||||
| 栈底 | id | F | T | T | T | T | T | T | E |
- $w = id * id$$
- 栈中存储语法分析器的状态(编号), "编码"了语法分析树的上边缘


2.4. 如何构造LR分析表?
- LR(0)分析表指导LR(0)语法分析器
- 在当前状态(编号)下, 面对当前文法符号时,该采取什么动作
2.4.1. 状态是什么? 如何跟踪状态?
- 状态是语法分析树的上边缘, 存储在栈中
- 可以用自动机跟踪状态变化(自动机中的路径 ⇔ \Leftrightarrow ⇔栈中符号/状态编号)
2.4.2. 何时归约? 使用哪条产生式进行归约?
- 必要条件: 当前状态中, 已观察到某个产生式的完整右部
- 对于LR(0) 文法, 这是当前唯一的选择
2.4.3. Definition(句柄(Handle))
在输入串的(唯一)反向最右推导中, 如果下一步是逆用产生式 A → α A \rightarrow \alpha A→α将 α \alpha α规约为 A A A, 则称 α \alpha α是当前句型的句柄。

- LR语法分析器的关键就是高效寻找每个归约步骤所使用的句柄。
2.4.4. 句柄可能在哪里?
Theorem:存在一种LR语法分析方法,保证句柄总是出现在栈顶

- 句柄出现在栈顶极大程度上方便了我们进行分析。
S ⇒ r m ∗ α A z ⇒ r m ∗ α β B y z ⇒ r m ∗ α β γ y z S ⇒ r m ∗ α B x A z ⇒ r m ∗ α B x y z ⇒ r m ∗ α γ x y \begin{array}{l} S \xRightarrow[rm]{*} \alpha Az \xRightarrow[rm]{*} \alpha\beta Byz \xRightarrow[rm]{*} \alpha\beta\gamma yz \\ S \xRightarrow[rm]{*} \alpha BxAz \xRightarrow[rm]{*} \alpha Bxyz \xRightarrow[rm]{*} \alpha\gamma xy \\ \end{array} S∗rmαAz∗rmαβByz∗rmαβγyzS∗rmαBxAz∗rmαBxyz∗rmαγxy
- 对于最右推导,任何推导都只有如上两种情况(注意是两次连续推导)
- A是B的父亲(等价于B是A的父亲)
- 或者A和B平级
- 情况2中的x必然为终结符(最右推导),每次规约后我们都可以在栈顶找到终结符。
- 可以用自动机跟踪状态变化(自动机中的路径 ⇔ \Leftrightarrow ⇔ 栈中符号/状态编号)
Theorem:存在一种LR语法分析方法, 保证句柄总是出现在栈顶。
- 在自动机的当前状态识别可能的句柄(观察到的完整右部)(自动机的当前状态 ⇔ \Leftrightarrow ⇔ 栈顶)
- LR(0) 句柄识别有穷状态自动机(Handle-Finding Automaton)

红色框出来的就是接受状态。
2.5. 状态刻画了"当前观察到的针对所有产生式的右部的前缀"
2.5.1. Definition (LR(0) 项(Item))
- 一个文法G的一个LR(0)项是G的一个产生式再加上一个位于体部某处的点。
A → X Y Z [ A → ⋅ X Y Z ] [ A → X ⋅ Y Z ] [ A → X Y ⋅ Z ] [ A → X Y Z ⋅ ] \begin{array}{l} A \rightarrow XYZ \\ [A \rightarrow ·XYZ] \\ [A \rightarrow X·YZ]\\ [A \rightarrow XY·Z] \\ [A \rightarrow XYZ·] \\ \end{array} A→XYZ[A→⋅XYZ][A→X⋅YZ][A→XY⋅Z][A→XYZ⋅]
- 产生式 A → ϵ A \rightarrow \epsilon A→ϵ只有一个项 [ A → ⋅ ] [A \rightarrow ·] [A→⋅]
- 项指明了语法分析器已经看到了一个产生式的哪些部分
- 点指示了栈顶, 左边(与路径) 是栈中内容, 右边是期望看到的文法符号
2.5.2. Definition (项集)
- 项集就是若干项构成的集合。
- 因此, 句柄识别自动机的一个状态可以表示为一个项集
2.5.3. Definition (项集族)
- 项集族就是若干项集构成的集合。
- 因此, 句柄识别自动机的状态集可以表示为一个项集族
2.5.4. 示例
2.5.5. Definition (增广文法(Augmented Grammar))
- 文法G 的增广文法是在G 中加入产生式 S ′ → S S' \rightarrow S S′→S得到的文法。
- 目的: 告诉语法分析器何时停止分析并接受输入符号串
- 当语法分析器面对$$ 且 要 使 用 且要使用 且要使用S’ \rightarrow S$进行归约时, 输入符号串被接受
- 注: 此"接受" (输入串) 非彼"接受" (句柄识别自动机)
3. LR(0) 句柄识别自动机
- 初始状态是什么?
- 状态之间如何转移?
3.1. 初始状态
- 点指示了栈顶, 左边(与路径) 是栈中内容, 右边是期望看到的文法符号
- S ′ → S S' \rightarrow S S′→S是增广语法添加的。
- 红色部分: S ′ → ⋅ S S' \rightarrow ·S S′→⋅S中的点表示栈顶,整句话表示栈是空的,我们找到E。
- 黑色部分:通过迭代的方式在其中添加栈顶的位置,然后计算闭包得到。

3.2. 构造LR(0)句柄识别自动机的构造过程
只有红色框中的状态为接受状态, I 5 I_5 I5状态也是接受状态
- 闭包等于自身,则终止,比如左上角接受状态,那么如果当前为E,则移动一下栈顶得到结果
- 对于会首先遇到一个非终结符,那么需要展开对应非终结符以获取闭包
- 然后对每一个状态进行递归:箭头上是看到的符号(下一个符号),找到产生式右侧中包含的项。
- 伪代码描述如下图:

J = G O T O ( I , X ) = C L O S U R E ( { [ A → α X ⋅ β ] ∣ [ A → ⋅ X β ] ∈ I } ) ( X ∈ N ∪ T ∪ { $ } ) \begin{array}{l} J = GOTO(I, X) = CLOSURE(\{[A \rightarrow \alpha X ·\beta ] | [A \rightarrow · X \beta] \in I \}) \\ (X \in N \cup T \cup \{\$\})\\ \end{array} J=GOTO(I,X)=CLOSURE({[A→αX⋅β]∣[A→⋅Xβ]∈I})(X∈N∪T∪{$})

C表示的是所有的状态的集合。
接受状态 F = { I ∈ C ∣ ∃ k . [ k : A → α ⋅ ] ∈ I } F = \{I \in C | \exist k.[k:A \rightarrow \alpha ·] \in I\} F={I∈C∣∃k.[k:A→α⋅]∈I}

点指示了栈顶,左边(与路径)是栈中内容,右边是期望看到的文法符号串
3.3. LR(0)分析表

- GOTO函数被拆分成ACTION表(针对终结符)与GOTO表(针对非终结符)
终结符,转换状态(s): ( 1 ) G O T O ( I i , a ) = I j ∧ a ∈ T ⇒ A C T I O N [ i , a ] ← s j (1) GOTO(I_i, a) = I_j \wedge a \in T \Rightarrow ACTION[i, a] \leftarrow sj (1)GOTO(Ii,a)=Ij∧a∈T⇒ACTION[i,a]←sj

非终结符,调整状态(goto): ( 2 ) G O T O ( I i , A ) = I j ∧ A ∈ N ⇒ A C T I O N [ i , A ] ← g j (2) GOTO(I_i, A) = I_j \wedge A \in N \Rightarrow ACTION[i, A] \leftarrow gj (2)GOTO(Ii,A)=Ij∧A∈N⇒ACTION[i,A]←gj

$(3) [k:A \rightarrow \alpha·] \in I_i \wedge A \neq S’ \Rightarrow \forall t \in T \cup {$}. ACTION[i, t] = rk$,假设产生式编号为k,并且不是S’开头的

$(4) [S’ \rightarrow S·] \in I_i \Rightarrow ACTION[i, $] \leftarrow acc$
接受不等于自动机中的接受状态,判断输入是否可以被接受。
3.4. LR(0)分析表构造规则
( 1 ) G O T O ( I i , a ) = I j ∧ a ∈ T ⇒ A C T I O N [ i , a ] ← s j ( 2 ) G O T O ( I i , A ) = I j ∧ A ∈ N ⇒ A C T I O N [ i , A ] ← g j ( 3 ) [ k : A → α ⋅ ] ∈ I i ∧ A ≠ S ′ ⇒ ∀ t ∈ T ∪ $ . A C T I O N [ i , t ] = r k ( 4 ) [ S ′ → S ⋅ ] ∈ I i ⇒ A C T I O N [ i , $ ] ← a c c \begin{array}{l} (1) & GOTO(I_i, a) = I_j \wedge a \in T \Rightarrow ACTION[i, a] \leftarrow sj \\ (2) & GOTO(I_i, A) = I_j \wedge A \in N \Rightarrow ACTION[i, A] \leftarrow gj \\ (3) & [k:A \rightarrow \alpha·] \in I_i \wedge A \neq S' \Rightarrow \forall t \in T \cup {\$}. ACTION[i, t] = rk \\ (4) & [S' \rightarrow S·] \in I_i \Rightarrow ACTION[i, \$] \leftarrow acc \\ \end{array} (1)(2)(3)(4)GOTO(Ii,a)=Ij∧a∈T⇒ACTION[i,a]←sjGOTO(Ii,A)=Ij∧A∈N⇒ACTION[i,A]←gj[k:A→α⋅]∈Ii∧A=S′⇒∀t∈T∪$.ACTION[i,t]=rk[S′→S⋅]∈Ii⇒ACTION[i,$]←acc
3.5. Definition (LR(0) 文法)
- 如果文法G的LR(0)分析表是无冲突的, 则G是LR(0) 文法。

- LR(0)分析表每一行(状态)所选用的归约产生式是相同的

- 归约时不需要向前看, 这就是0的含义
3.6. LR(0) 语法分析器
- L:从左向右(Left-to-right) 扫描输入
- R:构建反向(Reverse)最右推导
- 0:归约时无需向前看
- LR(0) 自动机与栈之间的互动关系
- 向前走 ⇔ \Leftrightarrow ⇔ 移入
- 回溯 ⇔ \Leftrightarrow ⇔ 归约
- 自动机才是本质, 栈是实现方式,用栈记住"来时的路", 以便回溯
4. SLR(1)分析表
- 规约:$(3) [k:A \rightarrow \alpha·] \in I_i \wedge A \neq S’ \Rightarrow \forall t \in Follow(A) \cup {$}. ACTION[i, t] = rk , 要 规 约 就 是 我 们 发 现 了 完 整 的 右 部 ( ,要规约就是我们发现了完整的右部( ,要规约就是我们发现了完整的右部(A \rightarrow \alpha , 并 且 当 前 符 号 为 ,并且当前符号为 ,并且当前符号为t$),如果t不在Follow(A)中,那么不可能有一个句型包含t。
- 处理的时候还是要看一下当前的符号来判断是否需要规约,根据当前的分析,我们可以发现下图中的被圈起来的s7是不必要的。

4.1. Definition (SLR(1)文法)
- 如果文法G 的SLR(1) 分析表是无冲突的, 则G是SLR(1) 文法。

- 无冲突: action 表中每个单元格最多只有一种动作
- 两类可能的冲突: “移入/归约” 冲突、“归约/归约” 冲突
4.2. 非SLR(1)文法举例

[ S → L ⋅ = R ] ∈ I 2 ⇒ A C T I O N ( I 2 , = ) ← s 6 = ∈ F o l l o w ( R ) ⇒ A C T I O N ( I 2 , = ) ← L 5 \begin{array}{l} [S \rightarrow L·=R] \in I_2 \Rightarrow ACTION(I_2, =) \leftarrow s6 \\ \\ = \in Follow(R) \Rightarrow ACTION(I_2, =) \leftarrow L_5 \end{array} [S→L⋅=R]∈I2⇒ACTION(I2,=)←s6=∈Follow(R)⇒ACTION(I2,=)←L5
- 即使考虑 = ∈ F o l l o w ( A ) = \in Follow(A) =∈Follow(A), 对该文法来说仍然不够,这个仅仅意味有一个句型满足推导出原式子,但不是所有句型都满足原式子。
- 该文法没有以
R=···开头的最右句型

符号是不一定一致的,仅供参考。
- 希望LR语法分析器的每个状态能尽可能精确地指明哪些输入符号可以跟在句柄 A → α A \rightarrow \alpha A→α的后面
- 在LR(0) 自动机中, 某个项集 I j I_j Ij中包含 [ A → α ⋅ ] [A \rightarrow α·] [A→α⋅],则在之前的某个项集 I i I_i Ii中包含 [ B → β ⋅ A γ ] [B \rightarrow \beta · A\gamma] [B→β⋅Aγ],只有这样子才是可以的。
- 解决方案:这表明只有 a ∈ F i r s t ( γ ) a \in First(\gamma) a∈First(γ)时, 才可以进行 A → α A \rightarrow \alpha A→α归约, t ∈ F o l l o w ( A ) t \in Follow(A) t∈Follow(A),并且是包含 t ∈ F i r s t ( γ ) t \in First(\gamma) t∈First(γ),后者条件更强。
- 但是, 对 I i I_i Ii求闭包时, 仅得到 [ A → ⋅ α ] [A \rightarrow ·\alpha] [A→⋅α], 丢失了 F i r s t ( γ ) First(\gamma) First(γ)信息,这个就是LR(0)的问题,接下来的目标就是保留下 γ \gamma γ的信息。
5. Definition (LR(1) 项(Item))
- $[A \rightarrow \alpha·\beta, a] (a \in T \cup {$}) , 此 处 , a 是 向 前 看 符 号 , 数 量 为 1 , 使 用 a 来 记 住 ,此处, a是向前看符号, 数量为1,使用a来记住 ,此处,a是向前看符号,数量为1,使用a来记住\gamma$
- 思想: α \alpha α在栈顶, 且输入中开头的是可以从 β α \beta\alpha βα推导出的符号串
5.1. LR(1)句柄识别自动机
计算闭包:$[A \rightarrow \alpha · B \beta, a] \in I (a \in T \cup {$})$

处理GOTO: ∀ b ∈ F i r s t ( β a ) . [ B → ⋅ γ , b ] ∈ I \forall b \in First(\beta a).[B \rightarrow ·\gamma, b] \in I ∀b∈First(βa).[B→⋅γ,b]∈I

处理项: J = G O T O ( I , X ) = C L O S U R E ( { [ A → α X ⋅ β ] ∣ [ A → α ⋅ X β ] ∈ I } ) ( X ∈ N ∪ T ) J = GOTO(I, X) = CLOSURE(\{[A \rightarrow \alpha X ·\beta]|[A \rightarrow \alpha · X \beta] \in I\}) (X \in N \cup T) J=GOTO(I,X)=CLOSURE({[A→αX⋅β]∣[A→α⋅Xβ]∈I})(X∈N∪T)

5.2. LR(1)自动机的构造过程

- 构造First和Follow不要出错
- 注意计算First( β a \beta a βa)
5.3. LR(1) 自动机构建LR(1) 分析表
( 1 ) G O T O ( I i , a ) = I j ∧ a ∈ T ⇒ A C T I O N [ i , a ] ← s j ( 2 ) G O T O ( I i , A ) = I j ∧ A ∈ N ⇒ A C T I O N [ i , A ] ← g j ( 3 ) [ k : A → α ⋅ , a ] ∈ I i ∧ A ≠ S ′ ⇒ A C T I O N [ i , a ] = r k ( 4 ) [ S ′ → S ⋅ , $ ] ∈ I i ⇒ A C T I O N [ i , $ ] ← a c c \begin{array}{l} (1) & GOTO(I_i, a) = I_j \wedge a \in T \Rightarrow ACTION[i, a] \leftarrow sj \\ (2) & GOTO(I_i, A) = I_j \wedge A \in N \Rightarrow ACTION[i, A] \leftarrow gj \\ (3) & [k:A \rightarrow \alpha·, a] \in I_i \wedge A \neq S' \Rightarrow ACTION[i, a] = rk \\ (4) & [S' \rightarrow S·, \$] \in I_i \Rightarrow ACTION[i, \$] \leftarrow acc \\ \end{array} (1)(2)(3)(4)GOTO(Ii,a)=Ij∧a∈T⇒ACTION[i,a]←sjGOTO(Ii,A)=Ij∧A∈N⇒ACTION[i,A]←gj[k:A→α⋅,a]∈Ii∧A=S′⇒ACTION[i,a]=rk[S′→S⋅,$]∈Ii⇒ACTION[i,$]←acc
5.4. Definition (LR(1)文法)
- 如果文法G的LR(1)分析表是无冲突的, 则G是LR(1)文法。

- LR(1) 通过不同的向前看符号, 区分了状态对(3, 6), (4, 7) 与(8, 9)
- 状态数可能会变多:将LR(0)中的一个项分裂成为两个项(根据后一个字符)
6. LR(0)、SLR(1)、LR(1)的归约条件对比
L R ( 0 ) [ k : A → α ⋅ ] ∈ I i ∧ A ≠ S ′ ⇒ ∀ t ∈ T ∪ { $ } . A C T I O N [ i , t ] = r k S L R ( 1 ) [ k : A → α ⋅ ] ∈ I i ∧ A ≠ S ′ ⇒ ∀ t ∈ F o l l o w ( A ) . A C T I O N [ i , t ] = r k L R ( 1 ) [ k : A → α ⋅ , a ] ∈ I i ∧ A ≠ S ′ ⇒ A C T I O N [ i , a ] = r k \begin{array}{l} LR(0) & [k:A \rightarrow \alpha·] \in I_i \wedge A \neq S' \Rightarrow \forall t \in T \cup \{\$\}. ACTION[i, t] = rk \\ SLR(1) & [k:A \rightarrow \alpha·] \in I_i \wedge A \neq S' \Rightarrow \forall t \in Follow(A). ACTION[i, t] = rk \\ LR(1) & [k:A \rightarrow \alpha·, a] \in I_i \wedge A \neq S' \Rightarrow ACTION[i, a] = rk \\ \end{array} LR(0)SLR(1)LR(1)[k:A→α⋅]∈Ii∧A=S′⇒∀t∈T∪{$}.ACTION[i,t]=rk[k:A→α⋅]∈Ii∧A=S′⇒∀t∈Follow(A).ACTION[i,t]=rk[k:A→α⋅,a]∈Ii∧A=S′⇒ACTION[i,a]=rk
7. LALR(1)文法
LR(1) 虽然强大, 但是生成的LR(1)分析表可能过大, 状态过多

LALR(1):Look Ahead合并具有相同核心LR(0)项的状态(忽略不同的向前看符号)
7.1. 自动机合并问题

- Q:合并 I 4 I_4 I4与 I 7 I_7 I7为 I 47 I_{47} I47(${[C \rightarrow d·, c/d/$]}$), 会怎样?会不会出现原来自动机可以识别的但是现在不可以识别,或者原来自动机不可以识别但是现在可以识别。
7.1.1. 定理
如果合并后的语法分析器无冲突, 则它的行为与原分析器一致。
- 接受原分析器所接受的句子, 且状态转移相同
- 拒绝原分析器所拒绝的句子, 但可能多一些不必要的归约动作(“实际上, 这个错误会在移入任何新的输入符号之前就被发现”)
7.1.2. 继续执行合并
继续合并( I 8 I_8 I8, I 9 I_9 I9) 以及( I 3 I_3 I3, I 6 I_6 I6)

7.1.3. GOTO 函数怎么办?
可以合并的状态的GOTO目标(状态)一定也是可以合并的
7.1.4. 对于LR(1)文法, 合并得到的LALR(1)分析表是否会引入冲突?
- Theorem:LALR(1)分析表不会引入移入/归约冲突。
- 反证法:
- 假设合并后出现 [ A → α ⋅ , a ] [A \rightarrow \alpha·, a] [A→α⋅,a]与 [ B → ⋅ α γ , b ] [B \rightarrow ·\alpha \gamma, b] [B→⋅αγ,b],
- 则在LR(1)自动机中,存在某状态同时包含 [ A → α ⋅ , a ] [A \rightarrow \alpha·, a] [A→α⋅,a] 与 [ B → ⋅ α γ , c ] [B \rightarrow ·\alpha \gamma, c] [B→⋅αγ,c](需要有一个相同的第一个分量)
- Q:对于LR(1)文法, 合并得到的LALR(1)分析表是否会引入冲突?
- Theorem:LALR(1)分析表可能会引入归约/归约冲突
L ( G ) = { a c d , a c e , b c d , b c e } S ′ → S S S → a A d ∣ b B d ∣ a B e ∣ b A e A → c B → c { [ A → c ⋅ , d ] , [ B → c ⋅ , e ] } { [ A → c ⋅ , e ] , [ B → c ⋅ , d ] } { [ A → c ⋅ , d / e ] , [ B → c ⋅ , e / e ] } \begin{array}{l} L(G) = \{ acd, ace, bcd, bce\} \\ S' \rightarrow S \\S S \rightarrow a A d | b B d | a B e | b A e \\ A \rightarrow c \\ B \rightarrow c \\ \{[A \rightarrow c·, d], [B \rightarrow c·, e]\} \\ \{[A \rightarrow c·, e], [B \rightarrow c·, d]\} \\ \{[A \rightarrow c·, d/e], [B \rightarrow c·, e/e]\} \\ \end{array} L(G)={acd,ace,bcd,bce}S′→SSS→aAd∣bBd∣aBe∣bAeA→cB→c{[A→c⋅,d],[B→c⋅,e]}{[A→c⋅,e],[B→c⋅,d]}{[A→c⋅,d/e],[B→c⋅,e/e]}
- LALR(1) 语法分析器的优点
- 状态数量与SLR(1)语法分析器的状态数量相同
- 对于LR(1) 文法, 不会产生移入/归约冲突
- 好消息: 善用LR 语法分析器, 处理二义性文法
- 从CFG来看: L R ( 1 ) ⊂ L R ( 2 ) LR(1) \subset LR(2) LR(1)⊂LR(2)
- 从语言角度来看: L R ( 1 ) = L R ( 2 ) = . . . = L R ( k ) LR(1) = LR(2) = ... = LR(k) LR(1)=LR(2)=...=LR(k)
8. 表达式文法

8.1. 使用SLR(1) 语法分析方法

我们利用结合性和优先级来避开二义性,比如 E + E ⋅ ∗ E E+E·*E E+E⋅∗E这时,我们需要将乘法移入。
8.2. 条件语句文法
 文章来源:https://www.toymoban.com/news/detail-447181.html
文章来源:https://www.toymoban.com/news/detail-447181.html
8.3. 条件语句文法: 使用SLR(1) 语法分析方法
 文章来源地址https://www.toymoban.com/news/detail-447181.html
文章来源地址https://www.toymoban.com/news/detail-447181.html
到了这里,关于编译原理-6-LR语法分析器的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!