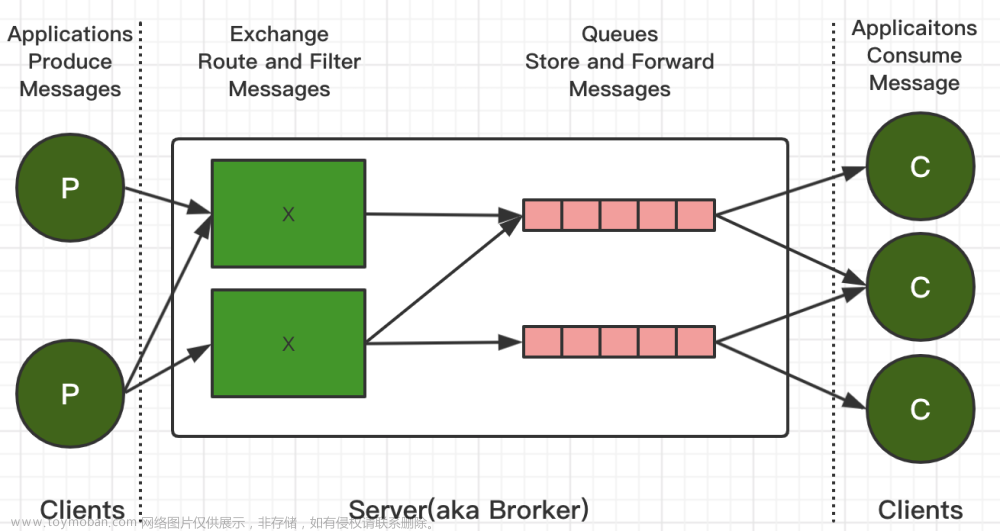
1、有哪些常见的消息队列模型?分别适用于什么场景?
消息队列是一种应用广泛的异步通信模型,可以解决分布式系统中不同组件之间的协调和通信问题。以下是一些常见的消息队列模型及其适用场景:
- 点对点模型(Point-to-Point Model):也被称为队列模型,消息生产者将消息发送到队列中,然后消息消费者从队列中获取消息并处理。适用于需要精确传递消息的场景,如订单处理、任务调度等。
- 发布/订阅模型(Publish/Subscribe Model):也被称为主题模型,消息生产者将消息发送到主题中,然后主题将消息广播给所有订阅该主题的消费者。适用于需要将消息广播给多个消费者的场景,如新闻订阅、实时数据更新等。
- 管道模型(Pipes and Filters Model):消息生产者将消息发送到管道中,然后管道中的过滤器依次处理消息并将其发送给下一个过滤器。适用于需要将消息按照一定的处理流程进行处理的场景,如日志处理、数据清洗等。
常用的消息队列产品有 Apache Kafka 、 RabbitMQ、 Apache ActiveMQ、Apache RocketMQ 和 RabbitMQ。不同的消息队列适用于不同的应用场景:
- RabbitMQ:高吞吐量的消息队列;多种语言客户端库支持;支持多种消息协议;支持复杂的路由规则;支持消息确认机制;适合任务队列、日志处理、消息通信等场景。
- Apache Kafka:高吞吐量、支持百万级别的消息每秒处理能力;分布式、高可靠、可扩展;支持持久化存储消息;数据复制至多个副本,保证数据可靠性;适合大规模数据流处理、日志系统等场景。
- Apache ActiveMQ:完全支持 JMS 规范,具有良好的跨语言支持;支持多种消息协议和多种持久化方式;具有较强的安全机制和集群管理能力;适合企业级应用、金融行业等场景。
- Apache RocketMQ:高吞吐量,低延迟,亿级消息堆积能力;支持事务消息、定时消息等高级特性;支持数据双写,保证数据可靠性;适合大规模数据流处理、金融支付等高可靠性场景。
2、如何用 Redis 中的 HyperLogLog 统计页面 UV?
HyperLogLog 是一种算法,用于在大数据集合上进行基数估计,即统计不重复元素的个数。
在处理大型数据集时,统计数据集中不同元素数量的问题十分常见。传统的做法是使用基于哈希表等结构的算法来实现,但随着数据量的增长,所需的内存空间也会随之增加,从而导致内存瓶颈问题的出现。
HyperLogLog 算法的主要思想是利用概率统计的方法对大规模数据集合的基数进行估计,并且只需要消耗非常少的内存空间。它通过在内部使用哈希函数和位运算,将数据以特定的方式映射到一个位向量中,并使用位向量中连续零位的数量来估算唯一元素的数量。
相比于传统的基数统计算法,HyperLogLog 算法具有以下优点:
- 内存占用极小:相比于使用哈希表的方法,HyperLogLog 只需要消耗极少的内存空间。
- 高度可扩展:HyperLogLog 算法可以方便地实现在分布式系统中的并行计算。
- 误差率可控:HyperLogLog 算法的误差率可以通过设置参数来调整,可以根据具体应用场景进行配置。
HyperLogLog 算法被广泛应用于数据流处理、分布式计算、搜索引擎等领域,如 Hadoop、Spark、Redis 等系统都提供了 HyperLogLog 算法的实现。
UV是一个数字营销和网站分析中经常使用的指标,表示独立访客数量。UV全称为Unique Visitor,即独立访客,通常指访问一个网站的不同电脑或移动设备用户数量。它是指浏览网站或应用程序的独特且有意识的访问者,每个独立IP地址或设备只计算一次。
与UV相对的指标是PV(Page View),即页面浏览量,或点击量。PV表示访问者在网站上打开的页面数量,无论该页面是否被同一个访问者多次打开。在统计网站流量时,UV和PV是两个非常重要的指标,它们可以帮助网站分析师和营销人员了解网站访问量、用户行为和流量来源等信息,以便更好地做出决策和优化网站内容。
在 Redis 中,HyperLogLog 是一种基数估算算法,可以用于快速计算一个集合中的不同元素数量的近似值。
在使用 HyperLogLog 统计页面 UV 时,我们可以将每个访问者的 IP 地址作为一个元素加入到 HyperLogLog 中,然后通过计算 HyperLogLog 中元素数量的近似值来估计页面的唯一访问者数量。
以下是一个示例代码,展示如何使用 Redis 的 HyperLogLog 实现页面 UV 统计:
import redis
# 连接 Redis 服务器
r = redis.Redis(host='localhost', port=6379)
# 记录访问者 IP 地址
ip_address = '192.168.0.1'
# 将 IP 地址加入到 HyperLogLog 中
r.pfadd('page_views', ip_address)
# 获取 HyperLogLog 中元素数量的近似值
uv = r.pfcount('page_views')
# 输出页面 UV
print('页面 UV:', uv)
在上面的示例代码中,我们使用 Redis 的 pfadd() 方法将每个访问者的 IP 地址加入到名为 page_views 的 HyperLogLog 中。然后,我们使用 pfcount() 方法获取 page_views 中元素数量的近似值,并将其作为页面 UV 的估计值输出到控制台。
需要注意的是,由于 HyperLogLog 是一种基数估算算法,其结果是一个近似值,并不是精确值。因此,在实际使用中,需要根据具体情况调整参数和精度等级,以获得更准确的结果。
要用 Redis 中的 HyperLogLog 统计页面 UV,可以使用以下步骤:
- 获取用户唯一标识:无论登录或未登录用户,都需要获取一个唯一标识来标识用户。可以将用户标识信息加密后存储为一个字符串,例如:“user:” + md5(user_id)。
- 统计 UV:每当有用户访问页面时,先根据用户唯一标识计算出对应的哈希值,然后使用 Redis 的 PFADD 命令将该哈希值添加到 HyperLogLog 中,代码如下:
PFADD uv:page_views:date user_id
其中,uv:page_views:date 是 HyperLogLog 的 key,表示当前这一天的页面浏览量,user_id 是获取到的用户唯一标识,每个用户只会被计数一次。
- 查询 UV:使用 Redis 的 PFCOUNT 命令查询 HyperLogLog 的基数(基数即 HyperLogLog 中不重复元素的个数),即为页面的 UV 数量,代码如下:
PFCOUNT uv:page_views:date
需要注意的是,HyperLogLog 有一定的误差,误差率约为 0.81%,但是在大多数情况下误差率非常小,可以满足统计 UV 这种业务需求。
3、有几台机器存储着几亿的淘宝搜索日志,假设你只有一台 2g 的电脑,如何选出搜索热度最高的十个关键词?
方法一
处理这么多数据是一个非常棘手的问题,但是可以考虑分布式处理来解决。如果只有一台2G的电脑,可以使用流式计算框架Storm来处理数据流。下面是一些思路:
- 首先,使用Storm搭建一个实时的数据接收及处理的框架,将日志数据源通过Kafka等消息队列发送到Storm集群上进行实时处理。
- 利用Storm提供的Bolt组件,编写一个Log Parser Bolt,对每一条日志数据进行解析,提取出搜索关键字,并发射给下一个Bolt。
- 在下一个Bolt中,可以考虑使用Redis这样的内存数据库来记录每个搜索关键词的搜索次数。假设每条日志包含一个搜索关键词,那么每当一个搜索关键词出现,就在Redis中增加该关键词的搜索次数。需要注意的是,为了保证Redis的内存能够容纳这么多数据,可以采用一些策略来缩小存储空间,如采用Bloom Filter等技术。
- 最后,查询Redis数据库,统计搜索关键词的搜索次数,选出热度最高的前10个关键词并输出。
方法二:
要选出搜索热度最高的十个关键词,需要对这些日志进行数据处理和分析。考虑以下步骤:
- 提取关键词 首先需要从搜索日志中提取出所有的关键词。可以使用分词技术,比如中文分词工具,将每条搜索记录分词,并将每个词语视为一个关键词。
- 统计关键词出现次数 将所有提取出来的关键词进行统计,计算每个关键词在搜索日志中出现的次数。
- 排序并选取前十名 将所有关键词按照出现次数进行排序,并选取出现次数最多的前十个关键词。
考虑到数据量非常大,而且只有一台 2g 的电脑,可以采用分布式处理的方式来处理数据。具体的实现可以借助一些分布式计算框架,比如 Apache Hadoop 或者 Apache Spark。
以下是一个大致的流程:文章来源:https://www.toymoban.com/news/detail-447530.html
- 使用 Hadoop 或 Spark 的分布式文件系统将所有搜索日志文件上传到集群中。
- 将搜索日志文件分成多个块,每个块的大小合适,可以使得每个块可以被一个节点处理。可以使用 Hadoop 的 HDFS 或者 Spark 的 RDD 来实现文件分块。
- 采用 MapReduce 或 Spark 的 Map-Reduce 编程模型,对每个块的搜索日志进行处理。具体来说,每个节点可以执行以下操作:
- 对于每条搜索记录,提取出其中的关键词,使用分词技术进行处理。
- 将每个关键词作为 key,出现次数作为 value,输出一个键值对 (key, value)。
- 将所有的键值对输出到一个中间文件中。
- 将所有节点输出的中间文件进行合并,以关键词为 key,将所有节点输出的值进行累加,得到每个关键词在搜索日志中出现的总次数。
- 对所有关键词按照出现次数进行排序,并选取出现次数最多的前十个关键词。
- 将结果输出到一个文件中,或者直接在终端输出。
需要注意的是,在实际操作中,还需要考虑一些细节问题,比如如何处理分词过程中的歧义、如何处理中文字符集等等。文章来源地址https://www.toymoban.com/news/detail-447530.html
到了这里,关于面试题30天打卡-day27的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!