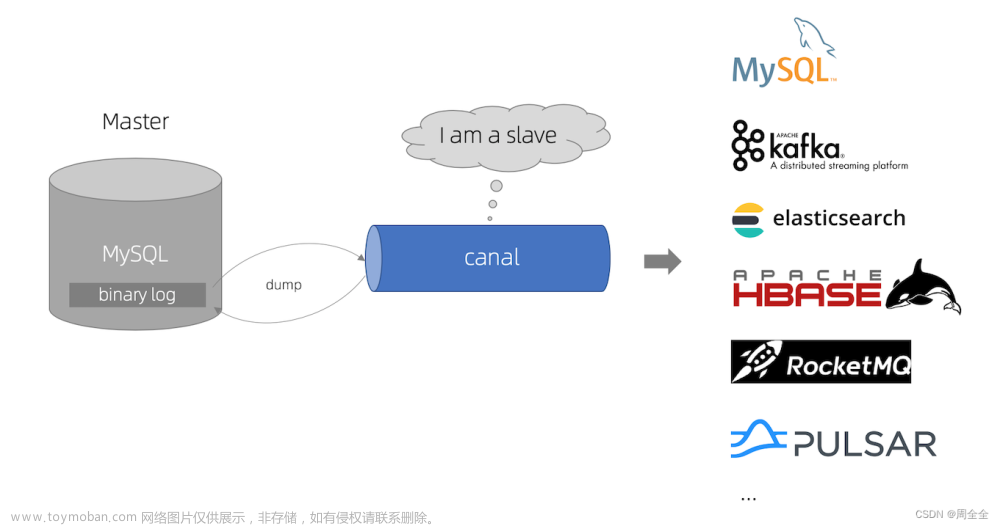
大数据工作要接触很多的数据库和查询引擎
数据库:
1、hive:用于跑批,大批量,稳定,缺点:无update。用于数仓
2、doris db:已更名starrocks。即时查询 可达千亿级别
文档:什么是 StarRocks @ StarRocks_intro @ StarRocks Docs
3、clickhouse:亿级别 局限性:主表,单表支持能力强,join能力弱
4、mysql:开源免费,十万级别查询
5、elasticsearch:不支持join,有些函数不支持 优点是检索快
6、kudu:能支持update、千万级别。数据量大(百亿级别)性能问题明显
7、postgresql:关系型数据库,支持很多分布式集群软件
8、sqlserver:windows运行,常用saas软件,数据在本地,比如医院。。
查询引擎:
1、impala:支持duku、hive,兼容性方面,对duku支持更佳,常用查询kudu
2、presto:支持duku、hive,兼容性方面,对hive支持更佳,常用查询hive
2个都属于查询引擎,其实是一样的产品,不同公司研发(其实也支持mysql,但是没必要再包一层去查询)
文章来源:https://www.toymoban.com/news/detail-447730.html
 文章来源地址https://www.toymoban.com/news/detail-447730.html
文章来源地址https://www.toymoban.com/news/detail-447730.html
到了这里,关于大数据测试-hive、doris、clickhouse、mysql、elasticsearch、kudu、postgresql、sqlserver的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!