参考:
https://github.com/CompVis/stable-diffusion
理解DALL·E 2, Stable Diffusion和 Midjourney的工作原理
Latent Diffusion Models论文解读
【生成式AI】淺談圖像生成模型 Diffusion Model 原理
【生成式AI】Stable Diffusion、DALL-E、Imagen 背後共同的套路
介绍
Stable Diffuson是潜在扩散模型(LDM)的文本转图像模型通过在一个潜在表示空间中迭代“去噪”数据来生成图像,然后将表示结果解码为完整的图像,让文图生成能够在消费级GPU上,在10秒级别时间生成图片,大大降低了落地门槛。扩散模型(Diffusion Models, DM)是基于Transformer的生成模型,它采样一段数据(例如图像)并随着时间的推移逐渐增加噪声,直到数据无法被识别。该模型尝试将图像回退到原始形式,在此过程中学习如何生成图片或其他数据。
DM存在的问题是强大的DM往往要消耗大量GPU资源,而且由于序列化评估(Sequential Evaluations),推理的成本相当高。为了使DM在有限的计算资源上进行训练而不影响其质量以及灵活性,Stable Diffusion将DM应用于强大的预训练自动编码器(Pre-trained Autoencoders)。
在这样的前提下训练扩散模型,使其有可能在降低复杂性和保留数据细节之间达到一个最佳平衡点,显著提高视觉真实程度。在模型结构中引入交叉注意力层(cross attention layer),使扩散模型成为一个强大而灵活的生成器,实现基于卷积的高分辨率图像生成。
同类:
DALL-E 2由OpenAI开发,它通过一段文本描述生成图像。其使用超过100亿个参数训练的GPT-3转化器模型,能够解释自然语言输入并生成相应的图像。DALL-E 2的工作是训练两个模型。第一个是Prior,接受文本标签并创建CLIP图像嵌入。第二个是Decoder,其接受CLIP图像嵌入并生成图像。使用
Midjourney也是一款由人工智能驱动的工具,其能够根据用户的提示生成图像。目前已经不能免费测试生成图像了。https://discord.com/channels/662267976984297473
安装
stable-diffusion-v1-5下载界面
模型地址:v1-5-pruned-emaonly.ckpt
部分包安装失败,是因为网络问题,可以多尝试几次。
由于包版本不同需要更改部分源码:
报错1:
cannot import name 'rank_zero_only' from 'pytorch_lightning.utilities.distributed'
参考:https://github.com/AUTOMATIC1111/stable-diffusion-webui/discussions/4111
解决:
from pytorch_lightning.utilities.rank_zero import rank_zero_only
报错2:
ImportError: cannot import name 'SAFE_WEIGHTS_NAME' from 'transformers.utils'
参考:https://github.com/CompVis/stable-diffusion/issues/627
pip install diffusers==0.12.1
示例代码:
python scripts/txt2img.py --prompt "a photograph of an astronaut riding a horse" --plms --ckpt /data1/Projects/stable-diffusion/models/ldm/stable-diffusion-v1/v1-5-pruned-emaonly.ckpt
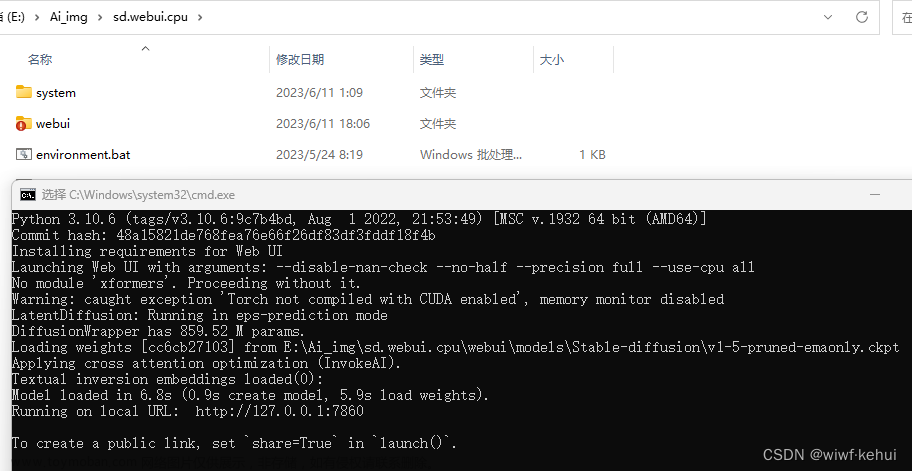
执行结果:
prompt方式可参考:入门)Stable Diffusion怎么写prompt?文章来源:https://www.toymoban.com/news/detail-447817.html
有哪些好的Stable Diffusion的prompt可以参考文章来源地址https://www.toymoban.com/news/detail-447817.html
到了这里,关于stable-diffusion安装和简单测试的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!