前言
随着网络的快速发展,分布式应用变得越来越普遍。这种类型的应用程序需要访问多个组件和服务,而这些组件可能分散在不同的物理位置上。在这种情况下,由于网络通信的高延迟和低带宽,性能问题变得尤为明显。为解决这一问题,分布式缓存应运而生。
什么是分布式缓存
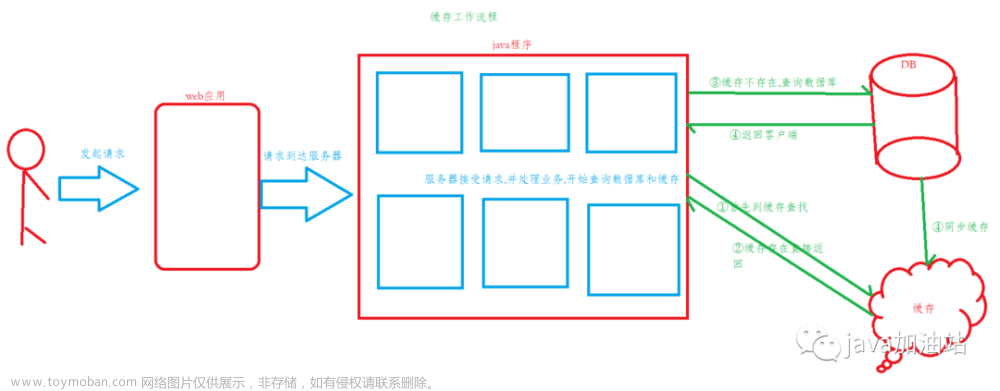
简单的说,分布式缓存是一个在不同服务器之间共享数据的系统。它是一种处理应用程序会频繁访问的数据的解决方案,将数据缓存在内存中,以此提高数据的访问速度。如果应用程序需要的数据已经被缓存在内存中,则不需要再访问数据库或其他数据源,从而大大减少了I/O负载和延迟,并改善了应用程序的响应时间和吞吐量。
通常,分布式缓存是由多个节点组成的。每个节点都具有相同的缓存副本,这些副本在不同的服务器上运行。当应用程序请求缓存数据时,分布式缓存系统会在缓存中搜索数据并返回给应用程序。如果缓存中没有所需的数据,则会从数据源中拉取数据,并将其写入缓存中以供日后使用。
分布式缓存的优势
分布式缓存具有如下优势:
-
提高了系统性能和可伸缩性。
-
通过减少对主数据库或其他资源的访问,降低了I/O负载和延迟。
-
可以解决跨多个数据中心或在不同地理位置的应用程序的性能问题。
-
提供了一个快速、高效的缓存层,减轻了服务器的工作负荷,从而提高了系统的扩展性。
-
增强了系统的容错性,即使某个节点崩溃,也不会影响整个分布式缓存系统的运行。
分布式缓存的实现
分布式缓存可以通过多种方式来实现。其中,最常见的方式是采用一致性哈希算法来划分数据,然后将其分配到不同的缓存节点上。采用这种方案,每个节点都只需要缓存部分数据,并且负责存储该数据的节点可以动态地添加或删除。当应用程序需要访问数据时,分布式缓存系统使用哈希算法来确定该数据在哪个节点上存储,并从那里获取该数据。
为了保证缓存的一致性,通常采用一些技术,如主从复制、数据刷新和版本控制等。这些机制可以确保分布式缓存中的数据始终保持最新状态,并且不会出现数据损坏或丢失的情况。
总结
分布式缓存是一种处理应用程序会频繁访问的数据的解决方案,通过将数据缓存在内存中提高了数据的访问速度。它是构建高性能、可伸缩和容错的分布式应用程序的重要组成部分。分布式缓存可以通过一致性哈希算法来实现,同时采用主从复制、数据刷新和版本控制等技术来确保数据的一致性。文章来源:https://www.toymoban.com/news/detail-447869.html
如果你正在构建一个分布式应用程序,那么你应该考虑使用分布式缓存系统。选择一个适合你的应用程序的分布式缓存系统并配置正确的缓存策略,可以显著提高应用程序的性能和可靠性。文章来源地址https://www.toymoban.com/news/detail-447869.html
到了这里,关于分布式缓存:什么是它以及为什么需要它?的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!