1 Introduction
本文建议根据样本的可学习性进行抽样,而不是从经验回放中随机抽样。如果有可能减少代理对该样本的损失,则认为该样本是可学习的。我们将可以减少样本损失的数量称为其可减少损失(ReLo)。这与Schaul等人[2016]的vanilla优先级不同,后者只是对具有高损失的样本给予高优先级,这可能会导致数据点的重复采样,而这些数据点由于噪声而无法学习。
本文首先简要描述了当前在从缓冲区中采样时进行优先级排序的方法,然后给出了在强化学习中减少损失的直觉。
这些实验表明,与Hessel等人[2017]中使用的Schaul等人[2016]的损失项相比,基于可减少的损失进行优先级排序是一种更鲁棒的方法,并且可以在不增加任何额外计算复杂度的情况下进行集成。
2 Background
基本概念
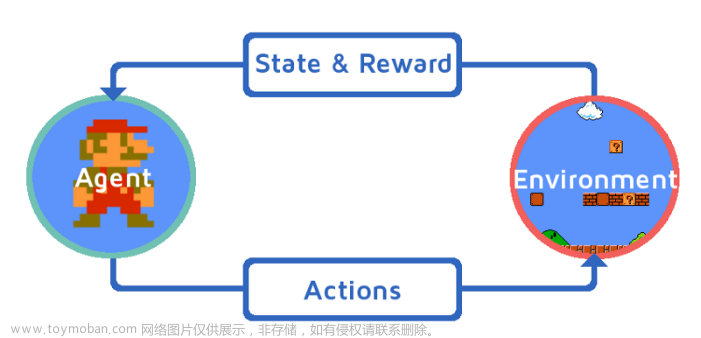
2.1 Experience Replay
2.2 Target Networks
2.3 Off-Policy Algorithms
3 Related Work
3.1 Reducible Loss
优先训练在训练开始时保留训练数据的子集来训练小容量模型θho。在训练期间,这个保留模型用于 衡量一个数据点是否可以在不经过训练的情况下学习随着持有数据集的大小增加,这种估计变得更加准确。
主模型θ和保留模型在实际训练数据上的损失之间的差异被称为可减少损失Lr,它用于小批量采样中训练数据的优先级排序

Lr被认为通过对数据点的训练来衡量信息的增益
3.2 Prioritization Schemes
Sinha-2020 提出了一种在当前策略平稳分布下,基于经验的似然度重新加权的方法,以保证重复可见状态值函数的近似误差较小
Lahire-2021介绍了大批量经验回放(LaBER),通过采用 an importance sampling view(重要性采样视图)来估计梯度,以克服PER的优先级过时及其超参数敏感性的问题。LaBER首先从回放缓冲区中采样一个大批次,然后计算梯度范数,最后按优先级向下采样到一个较小大小的小批次。
Kumar-2020提出了分布校正(DisCor),这是一种纠正反馈形式,可以使学习动态更加稳定。DisCor计算最优分布并执行加权Bellman更新以重新加权重放缓冲区中的数据分布。
受DisCor的启发, 后悔最小化经验重放(remn)-2021用an error network(误差网络)估计Q值的次优性。
拓扑经验回放(TER)-2022将智能体的experience组织成a graph(图),该图跟踪状态q值之间的依赖性。
4 Reducible Loss for Reinforcement Learning
受监督学习中优先训练的激励,我们提出了一种针对强化学习问题的优先排序方案,即智能体应该专注于具有更高的可减少TD误差的样本,而不是根据TD误差进行优先级排序,。这意味着,我们应该使用TD误差可以减少多少的度量,而不是TD误差
这意味着算法可以避免重复采样agent无法学习的点,并且可以专注于最小化可学习点的误差,从而提高样本效率
为了确定样本的学习能力,我们需要了解样本的目标是如何表现的,以及它是如何随时间变化的。
强化学习中的训练数据是由变化的策略生成的。因此,holdout model需要不时地更新。因此,在基于Q学习的强化学习方法中,hold-out模型的一个很好的代理是Eq. 8中Bellman更新中使用的目标网络:
由于目标网络仅使用在线模型参数定期更新,因此它保留了代理在使用过时策略训练的旧数据上的性能。目标网络可以很容易地用作 没有在新样本上训练的hold-out model 的近似值。

因此,我们将RL的可还原损失(ReLo)定义为数据点相对于在线网络(参数θ)和相对于目标网络(参数¯θ)的损失之差。
- 与PER相比相似之处,优先级方案在低优先级点的采样行为上
对于PER:不重要的数据点具有较低的Lθ,在ReLo中也将保持不重要。
因为如果Lθ很低,那么根据上述公式,ReLo也会很低。
这确保了我们保留了PER的理想行为,即不重复采样已经学习过的点- 不同之处在于存在较大的TD误差的采样点:
对于PER,如果由于转换本身的固有噪声,一个数据点可能具有很高的TD误差,即使在采样多次之后仍然保持很高,但它仍然具有较高的PER优先级。
但是它的优先级应该降低,因为可能有其他数据点更值得采样,因为它们有有用的信息,可以更快地学习。
对于ReLo:这样一个点会很低,因为Lθ和Lθ¯都很高
如果一个数据点被遗忘,那么Lθ将高于Lθ¯,并且ReLo将确保这些点被重新访问。
4.1 Implementation
我们应该为ReLo error创建一个映射fmap,它对所有值都是单调递增且非负的
当目标网络与主网络通过硬更新进行更新时,该值可以归零。然而,在一次更新之后,它很快变成非零
在实践中,我们发现将负值裁剪为零通过添加一个小参数来确保样本有最小概率:
- 由于不需要任何额外的训练,ReLo在计算上并不昂贵。它只涉及通过目标网络的状态的一个额外的前向传递
对于ReLo,唯一需要计算的附加项: Qtgt(st, at)计算Lθ¯。- ReLo也没有引入任何额外的超参数
- ReLo不一定依赖于确切的损失公式;只需要额外计算关于目标网络参数¯θ的Lalg。
如果损失只是均方误差,那么ReLo可以被简化,可以用Qθ和Qθ¯的差来表示。
但对非策略Q学习方法的其他扩展修改了这一目标,例如分布式学习Bellemare等人[2017]最小化KL散度,但不能以相同的方式简化两个KL散度之间的差异。
为了使ReLo成为一种可以跨这些方法使用的通用技术,我们用Lθ和Lθ¯来定义它。文章来源:https://www.toymoban.com/news/detail-447943.html
Algorithm 1
 文章来源地址https://www.toymoban.com/news/detail-447943.html
文章来源地址https://www.toymoban.com/news/detail-447943.html
到了这里,关于Jan 2023-Prioritizing Samples in Reinforcement Learning with Reducible Loss的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!