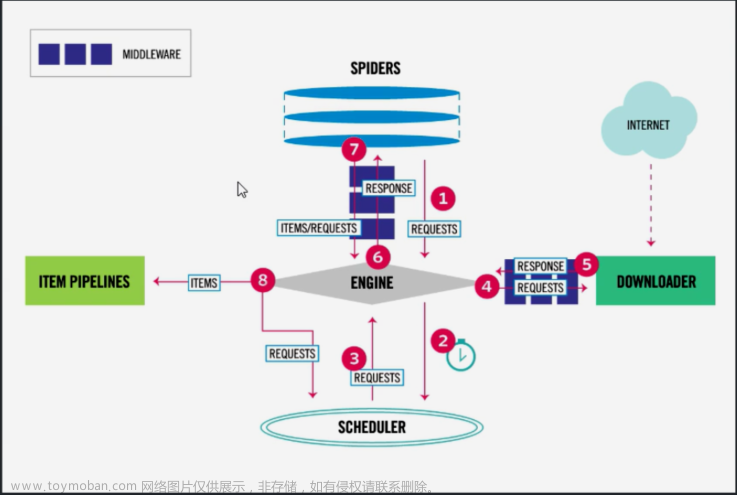
1.1获取网页
爬虫首先要做的工作就是获取网页,这里就是获取网页的源代码。源代码里包含了网页的部分有用信息,所以只要把源代码获取下来,就可以从中提取想要的信息了。
1.1.1提取信息
获取网页源代码后,接下来就是分析网页源代码,从中提取我们想要的数据。
另外,由于网页的结构有一定的规则,所以还有一些根据网页节点属性、cSS 选择器或 XPath 来提取网页信息的库,如 Beautifulsoup、pyquery、lxml等。使用这些库,我们可以高效快速地从中提取网页信息,如节点的属性、文本值等。
提取信息是爬虫非常重要的部分,它可以使杂乱的数据变得条理清晰,以便我们后续处理和分析数据。
1.1.2保存数据
提取信息后,我们一般会将提取到的数据保存到某处以便后续使用。这里保存形式有多种多样,如可以简单保存为TXT文本或了SON文本,也可以保存到数据库,如 MysQL和 MongoDB等,也可保存至远程服务器,如借助 SFTP进行操作等。
- 向起始url发送请求,并获取响应
- 对响应进行提取
- 如果提取url,则继续发送请求获取响应
- 如果提取数据,则将数据进行保存
1.2请求
请求由客户端向服务端发出,可以分为四个内容:请求方法、请求的网址、请求头、请求体。
1.2.1 请求方法
GET:请求页面,并返回页面内容
HEAD:类似于GET请求,只不过返回的响应中没有具体的内容,用于获取报头
POST:大多用于提交表单或上传文件,数据包含在请求体中
PUT:从客户端向服务器传送的数据取代指定文档中的内容
DELETE:请求服务器删除指定的页面
CONNECT:把服务器当作跳板,让服务器代替客户端访问其他网页
OPTIONS:允许客户端查看服务器的性能
TRACE:回显服务器收到的请求,主要用于测试或诊断
1.2.2 请求网址
请求的网址,即统一资源定位符URL,它可以唯一确定我们想请求的资源。
https://www.baidu.com/s?wd=python
https表示协议
www.baidu.com表示域名
s表示路径
wd=python表示查询参数
1.2.3 请求头
右键页面,检查,网络,然后点XHR,刷新页面,然后点击“headers”,找到请求标头。
接下来解释每一行都代表什么:
:Authority::请求的目标服务器的主机名或IP地址,这里是api.bilibili.com。
:Method::HTTP请求方法。这里是GET,表示获取资源。
:Path::请求的路径。这里是/x/web-interface/cdn/report?from=report。
:Scheme::请求的协议方案。这里是https,表示使用HTTPS协议进行通信。
Accept::客户端可接受的响应内容类型。这里是*/*,表示接受任意类型的响应。
Accept-Encoding::客户端可接受的响应内容编码方式。这里是gzip, deflate, br,表示支持gzip、deflate和br(Brotli)压缩方式。
Accept-Language::客户端可接受的语言类型。这里是zh-CN,zh;q=0.9,en-US;q=0.8,en;q=0.7,表示首选中文(中国大陆), 其次中文, 最后英文(美国)。
Cache-Control::控制缓存行为的指令,这里是no-cache,表示不使用缓存。
Origin::指定请求的来源,这里是https://www.bilibili.com。
Pragma::与缓存相关的指令,这里是no-cache,表示不使用缓存。
Referer::指定请求的来源页面或链接地址,这里是https://www.bilibili.com/。
Sec-Ch-Ua::指定浏览器的User-Agent字符串,表示浏览器及其版本信息。
Sec-Ch-Ua-Mobile::指定浏览器是否是移动版。
Sec-Ch-Ua-Platform::指定浏览器运行的平台,这里是Windows。
Sec-Fetch-Dest::指定请求的资源类型,这里是empty,表示空资源。
Sec-Fetch-Mode::指定请求的模式,这里是cors,表示使用CORS(跨源资源共享)请求。
Sec-Fetch-Site::指定请求的站点类型,这里是same-site,表示同源站点。
User-Agent::浏览器或客户端的用户代理标识,用于标识客户端的软件和版本信息。这里是Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Safari/537.36,表示使用的是Windows操作系统下的Chrome浏览器。
1.2.4请求体
请求体一般承载的内容是POST请求中的表单数据,但是对于GET请求,请求体为空。
先找到请求方法为POST的页面:
然后在载荷中找到相应的表单数据:
表单数据代表了每次进行访问所需要带的请求参数。
如果是GET请求带了载荷的话,那都会在URL中进行体现,比如:

可以发现,Payload中的report参数在请求的URL中体现了出来。文章来源:https://www.toymoban.com/news/detail-447948.html
1.3响应
响应的状态码在头部就可以看到,以下是相应状态码及其解释:文章来源地址https://www.toymoban.com/news/detail-447948.html
- 1xx(信息性状态码):表示请求已被接收,需要进一步处理。
100 Continue:服务器已接收到请求的起始部分,客户端应继续发送剩余的请求。
101 Switching Protocols:服务器将按照客户端请求的协议切换。 - 2xx(成功状态码):表示请求已成功处理并得到响应。
200 OK:请求成功,正常返回结果。
201 Created:请求成功,并在服务器上创建了新的资源。
204 No Content:请求成功,但响应中不包含实体的主体部分。 - 3xx(重定向状态码):表示需要进一步操作以完成请求。
301 Moved Permanently:请求的资源已永久移动到新位置。
302 Found:请求的资源临时移动到不同的位置。
304 Not Modified:客户端的缓存资源是最新的,不需要重新传输。 - 4xx(客户端错误状态码):表示请求包含错误或无法完成请求。
400 Bad Request:请求无效,服务器无法理解。
401 Unauthorized:请求需要身份验证。
403 Forbidden:服务器拒绝访问请求的资源。 - 5xx(服务器错误状态码):表示服务器无法完成请求。
500 Internal Server Error:服务器遇到了意外错误,无法完成请求。
502 Bad Gateway:作为代理或网关的服务器收到无效响应。
503 Service Unavailable:服务器暂时无法处理请求,通常是由于过载或维护。
到了这里,关于爬虫基本原理的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!



![第一个Python程序_获取网页 HTML 信息[Python爬虫学习笔记]](https://imgs.yssmx.com/Uploads/2024/01/797744-1.png)
![python爬取豆瓣电影排行前250获取电影名称和网络链接[静态网页]————爬虫实例(1)](https://imgs.yssmx.com/Uploads/2024/01/415693-1.png)