语言模型(LM)在NLP领域的发展速度非常快,特别是在大型语言模型(LLM)方面:当语言模型具有大量参数或权重/系数时,它们被称为“大型”。这些“大型”语言模型拥有处理和理解大量自然语言数据的能力。
LLM被用于一系列自然语言任务,如文本摘要、情感分析、主题分类、语言翻译、自动完成等。扩展LM的一些广泛的好处包括提高性能、泛化和效率,虽然这些模型执行的大多数任务都受益于扩展,但像算术、常识和符号推理这样的任务在扩展模型时没有看到性能的提高。

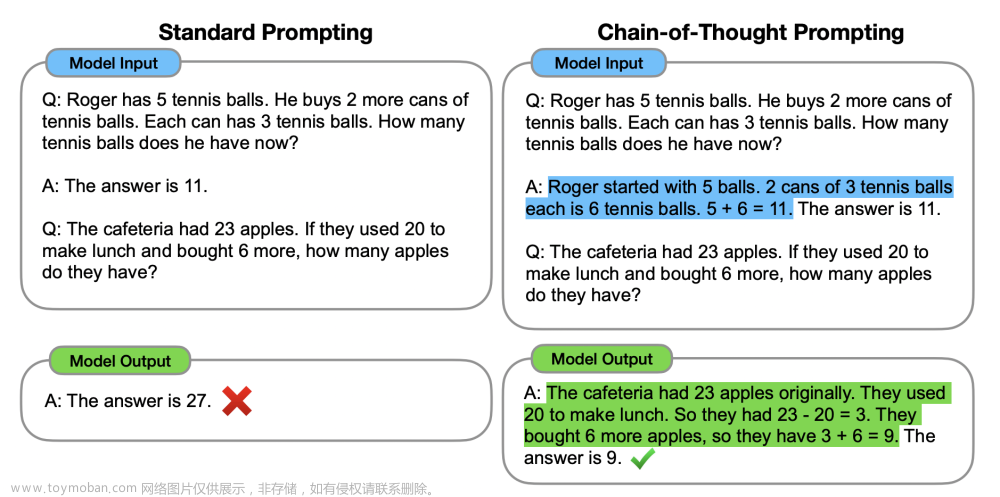
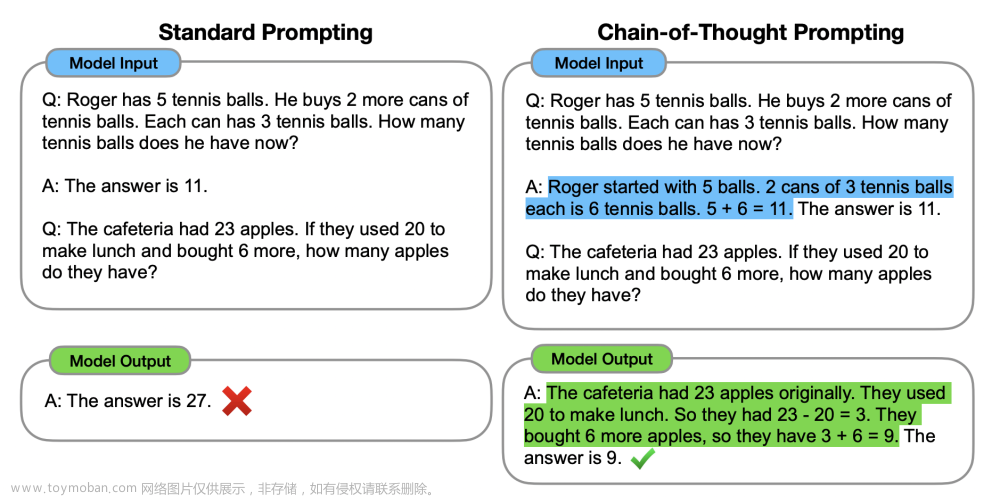
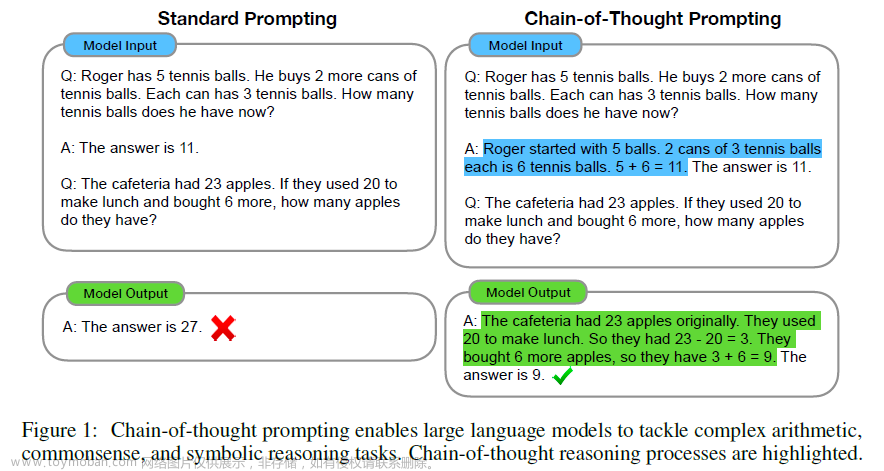
这就引出了“思维链提示”的方法,通过生成一系列中间推理步骤或思维链来提高法LLM 的复杂推理能力。这种方法基于两个想法:1、考虑到LM可以被训练来生成自然语言的中间步骤,增加自然语言的基本原理可能是一个额外的好处;2、当通过上下文少样本方法提示时,LLM在问答任务中取得了显著的成功。但在实践中,为训练训创造大量的理由是费时费力的。所以将这两种思想结合起来,就产生了一个模型,只要有几个由<input, chain-of-though, output>三元组组成的提示,模型的性能会得到改善。
思维链提示
思维链是解决推理任务时人类思维过程遵循的一系列典型步骤。它可以帮助我们将一个问题分解成一系列的子问题,然后逐个解决这些子问题,从而得出最终的答案。在大型语言模型中,思维链可以用来引出推理。思路链方法带来以下好处:
- 由于问题可以分为多个步骤,因此可以将额外的计算分配给复杂的问题
- 推理路径提供了一个调试模型可能出错的窗口
- 任何一般的 LLM 都可以通过提供思维链提示来为复杂的推理任务做准备
数学推理

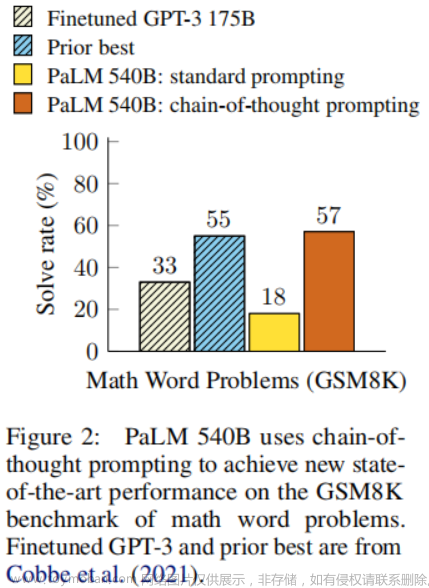
上图显示了 LLMs 在数学单词问题上使用思维链提示的表现结果。y 轴是结果表现,x 轴上是模型大小的比例。
- 只有在足够大的模型中才能看到思维链提示为 LLM 带来的好处。因此大型模型是必要的,但还不够
- 对于更复杂的推理问题,性能的提高更大。鉴于 GSM8K 与 MAWPS 中问题的复杂性降低,GSM8K 中的性能增益对于大型模型几乎翻了一番
- 大型 GPT 和 PaLM 模型中的思维链提示的性能与之前的 SOTA 方法相当,其中包括在标记的训练数据集上微调模型
- 除了上述几点外,对 PaLM 62B 错误的分析表明,当模型缩放到 540B 时,很大一部分的缺失和语义理解都得到了修复,这进一步强化了通过思维链提示提高LLM推理能力需要大模型的观点
消融实验
性能改进将根据三种不同的思维链提示进行评估
仅限方程:系统提示模型仅在响应数学应用题时输出方程式。这些模型在 GSM8K 上的这个提示上表现不佳,这表明在没有给出思维链中的步骤的情况下,这些问题的语义对于模型来说太具有挑战性,无法为它们输出方程。
仅进行变量计算:这种变化背后的思想是模型在复杂问题的计算上花费(令牌)更多。在分离提示时,提示的中间步骤是有用的。
回答后的思维链:这种变化测试思维链是否只是让模型访问预训练知识。给出答案后产生思维链的提示,其表现与基线相同,这表明在思维链的中间步骤中可用的推理比激活知识更必要。

稳健性研究
评估从GSM8K训练集到LaMDA 137B的不同注释和示例给出的思维链提示的稳健性时,所有这些思维链提示的变体都大大优于标准提示。

除算术推理外,还对模型进行了常识性和符号推理评价
常识推理
虽然PaLM模型在CSQA上的性能提升很小,但它在StrategyQA上的表现超过了之前的SOTA,对于运动理解上也超过了一个独立的人类运动爱好者。

符号推理
下图显示了PaLM模型在域内(示例和测试中的步骤数相同)和域外/OOD(测试中的步骤多于示例)上的评估结果。尽管对于域内测试,已经在思维链中提供了完美的解决方案结构,但小型模型表现不佳。

总结
虽然思维链提示假设建立在人类推理过程的基础上,但神经网络是否“推理”的问题仍然没有答案。在调优的情况下,手动提供示例的成本可能非常高,因为此过程将需要更多的示例。虽然使用示例的模型遵循“正确”推理路径的可能性很高,但不能保证这一点。为了实现思维链推理能力,模型必须“大”,这一先决条件使得它在实际应用中的使用代价高昂。
这篇论文的研究表明,思维链提示提高了模型在算术、常识和符号推理任务上的性能,但扩大模型可以执行的任务范围和降低这些模型改进推理的尺度阈值是潜在的广泛研究领域。
论文地址:https://avoid.overfit.cn/post/f281ad2e54614d029c8061cc693376ed
介绍这篇论文的另外一个原因是可以使用思维链提高ChatGPT的结果,因为思维链是一种逐步分解问题、逐步推理的思考方法,可以引导模型生成更准确、更有逻辑性的答案。文章来源:https://www.toymoban.com/news/detail-448179.html
- 对问题进行分解:将一个大问题分解成多个小问题,逐个解决。这样可以使模型更好地理解问题的结构,提高问题的细节处理能力。
- 比较和对比:将多个对象进行比较和对比,找出它们之间的共同点和不同点。这样可以使模型更好地理解对象之间的关系,提高其分类和判断能力。
- 推理和预测:根据已知的信息,推断可能的结果。这样可以使模型更好地处理复杂的问题,提高其推理和预测能力。
- 归纳和演绎:从具体情况中推导出一般规律,或者从一般规律中推导出具体情况。这样可以使模型更好地理解问题的本质和规律,提高其概括和推广能力。
- 假设实验:通过模拟实验来推断事物的本质或规律。这样可以使模型更好地理解事物的属性和行为,提高其推断和预测能力。
通过使用思维链的方法,可以帮助ChatGPT更好地理解问题,提高其推理、预测、分类和判断能力。在输入问题时,可以尝试将问题分解成多个子问题,然后逐个解决;在生成回答时,可以尝试进行比较和对比、推理和预测、归纳和演绎等操作,从而生成更准确、更有逻辑性的答案。所以无论你看不看这篇论文,它的思路对我们来说是非常重要的。文章来源地址https://www.toymoban.com/news/detail-448179.html
到了这里,关于使用思维链(Chain-of-thoughts)提示在大型语言模型中引出推理的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!