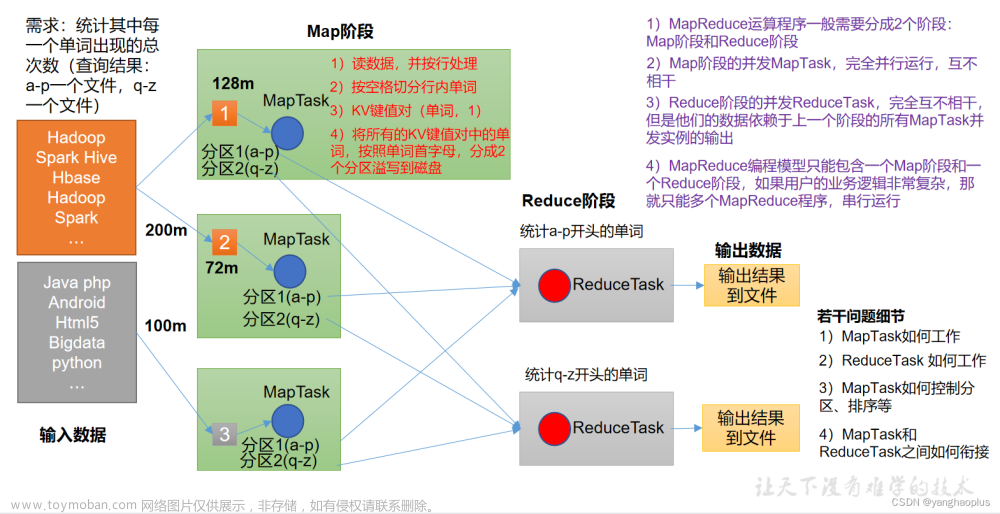
一、Hadoop-mapreduce简介
Hadoop Map/Reduce是一个使用简易的软件框架,基于它写出来的应用程序能够运行在由上千个商用机器组成的大型集群上,并以一种可靠容错的方式并行处理上T级别的数据集。一个Map/Reduce 作业(job) 通常会把输入的数据集切分为若干独立的数据块,由 map任务(task)以完全并行的方式处理它们。框架会对map的输出先进行排序, 然后把结果输入给reduce任务。通常作业的输入和输出都会被存储在文件系统中。 整个框架负责任务的调度和监控,以及重新执行已经失败的任务。通常,Map/Reduce框架和分布式文件系统是运行在一组相同的节点上的,也就是说,计算节点和存储节点通常在一起。这种配置允许框架在那些已经存好数据的节点上高效地调度任务,这可以使整个集群的网络带宽被非常高效地利用。Map/Reduce框架由一个单独的master JobTracker 和每个集群节点一个slave TaskTracker共同组成。master负责调度构成一个作业的所有任务,这些任务分布在不同的slave上,master监控它们的执行,重新执行已经失败的任务。而slave仅负责执行由master指派的任务。hadoop-mapreduce-examples则是Hadoop安装完成后自带的程序包,包含计算PI、统计单词等计算程序。
二、hadoop-mapreduce-examples包含的程序列表
| 程序名称 | 用途 |
|---|---|
| aggregatewordcount | 一个基于聚合的map/reduce程序,它对输入文件中的单词进行计数。 |
| aggregatewordhist | 一个基于聚合的map/reduce程序,用于计算输入文件中单词的直方图。 |
| bbp | 一个使用Bailey Borwein Plouffe计算PI精确数字的map/reduce程序。 |
| dbcount | 一个计算页面浏览量的示例作业,从数据库中计数。 |
| distbbp | 一个使用BBP型公式计算PI精确比特的map/reduce程序。 |
| grep | 一个在输入中计算正则表达式匹配的map/reduce程序。 |
| join | 一个影响连接排序、相等分区数据集的作业 |
| multifilewc | 一个从多个文件中计算单词的任务。 |
| pentomino | 一个地图/减少瓦片铺设程序来找到解决PotoMimo问题的方法。 |
| pi | 一个用拟蒙特卡洛方法估计PI的MAP/Relp程序。 |
| randomtextwriter | 一个map/reduce程序,每个节点写入10GB的随机文本数据。 |
| randomwriter | 一个映射/RADIUS程序,每个节点写入10GB的随机数据。 |
| secondarysort | 定义一个次要排序到减少的例子。 |
| sort | 一个对随机写入器写入的数据进行排序的map/reduce程序。 |
| sudoku | 数独求解者。 |
| teragen | 为terasort生成数据 |
| terasort | 运行terasort |
| teravalidate | terasort的检查结果 |
| wordcount | 一个映射/缩小程序,计算输入文件中的单词。 |
| wordmean | map/reduce程序,用于计算输入文件中单词的平均长度。 |
| wordmedian | map/reduce程序,用于计算输入文件中单词的中值长度。 |
三、测试样例实验
1、计算PI
[wuhs@s142 hadoop]$ ./bin/hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.1.jar pi 10 10


2、单词统计实验
1)、创建源文件和结果存储目录
[wuhs@s142 hadoop]$ hadoop fs -mkdir -p /wordcount/input
[wuhs@s142 hadoop]$ hadoop fs -mkdir -p /wordcount/output
2)、创建待计算的文本文件
[wuhs@s142 hadoop]$ cat /tmp/input/1.txt
123
321
This a test
hello hadoop
hi hadoop
Hadoop
Hadoop
hi
123
321
123
test
Test
123
test
Test
3)、将文件上传到Hadoop
[wuhs@s142 hadoop]$ hadoop fs -put /tmp/input/1.txt /wordcount/input
4)、查看文件列表
[wuhs@s142 hadoop]$ hadoop fs -ls /wordcount/input
Found 1 items
-rw-r–r-- 2 wuhs supergroup 74 2021-12-16 04:31 /wordcount/input/1.txt
5)、运行wordcount
[wuhs@s142 hadoop]$ ./bin/hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.1.jar wordcount /wordcount/input/1.txt /wordcount/output/1
…
2021-12-16 04:40:33,396 INFO mapreduce.Job: map 0% reduce 0%
2021-12-16 04:40:38,562 INFO mapreduce.Job: map 100% reduce 0%
2021-12-16 04:40:43,655 INFO mapreduce.Job: map 100% reduce 100%
2021-12-16 04:40:44,676 INFO mapreduce.Job: Job job_1639642758452_0004 completed successfully
…
File Input Format Counters
Bytes Read=58
File Output Format Counters
Bytes Written=49
6)、查看运行结果
[wuhs@s142 hadoop]$ hadoop fs -cat /wordcount/output/1/part-r-00000

7)、文件夹的创建和文件上传也可以在浏览器操作

四、QA
1、执行计算时报错/bin/bash: /bin/java: No such file or directory
- 报错信息:

解决方案:
各节点执行ln -s /usr/local/java/bin/java /bin/java
2、执行计算时报错The auxService:mapreduce_shuffle does not exist
- 报错信息

- 解决方案
修改yarn-site.xml 文件,如下,修改完成重启hadoop即可。
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
3、执行计算的时候Cannot create directory xxx Name node is in safe mode.
-
报错信息
 文章来源:https://www.toymoban.com/news/detail-448782.html
文章来源:https://www.toymoban.com/news/detail-448782.html -
解决方案
hdfs在启动开始时会进入安全模式,这时文件系统中的内容不允许修改也不允许删除,直到安全模式结束。安全模式主要是为了系统启动的时候检查各个DataNode上数据块的有效性,同时根据策略必要的复制或者删除部分数据块。运行期通过命令也可以进入安全模式。在实践过程中,系统启动的时候去修改和删除文件也会有安全模式不允许修改的出错提示,只需要等待一会儿即可。主动离开安全模式可以使用命令: $bin/hadoop dfsadmin -safemode leave文章来源地址https://www.toymoban.com/news/detail-448782.html
4、执行单词统计报错Output directory xxx already exists
- 报错信息

- 解决方案
修改输出目录,输出目录需要为空目录,所以在后面加上1,则会在/wordcount/output 目录下创建目录1,如果是多次计算每次都需要指定不同的目录用于存储结果。
到了这里,关于Hadoop之hadoop-mapreduce-examples测试执行及报错处理的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!

![【Hadoop】- MapReduce概述[5]](https://imgs.yssmx.com/Uploads/2024/04/857929-1.png)