写在前面
文档 是人们在日常生活、工作中产生的信息的重要载体,各领域从业者几乎每天都要与金融票据、商业规划、财务报表、会议记录、合同、简历、采购订单等文档或者图像“打交道”。所以让计算机具备阅读、理解和解释这些文档图像的能力,在智能金融、智能办公、电子商务等许多领域具有广阔的应用价值。但现阶段文档图像的处理过程中面临着诸多挑战:文档类型的多样产生了繁杂的版式与结构;受拍摄器材、背景环境影响,图像时常存在噪声和质量问题等。
技术论坛
为了促进文档图像分析与处理领域的技术交流及发展,中国图象图形学学会文档图像分析与识别专业委员会与合合信息共同打造了《文档图像智能分析与处理》高峰论坛。在本次论坛中,合合信息特别邀请了来自中科院自动化所、北大、中科大、华南理工大的学术专家与华为等知名企业的研究者们,围绕文档图像处理及 OCR 领域等前沿技术展开“头脑风暴”,寻找文档图像处理领域的未来进阶方向。

■ 智能文档图像处理技术
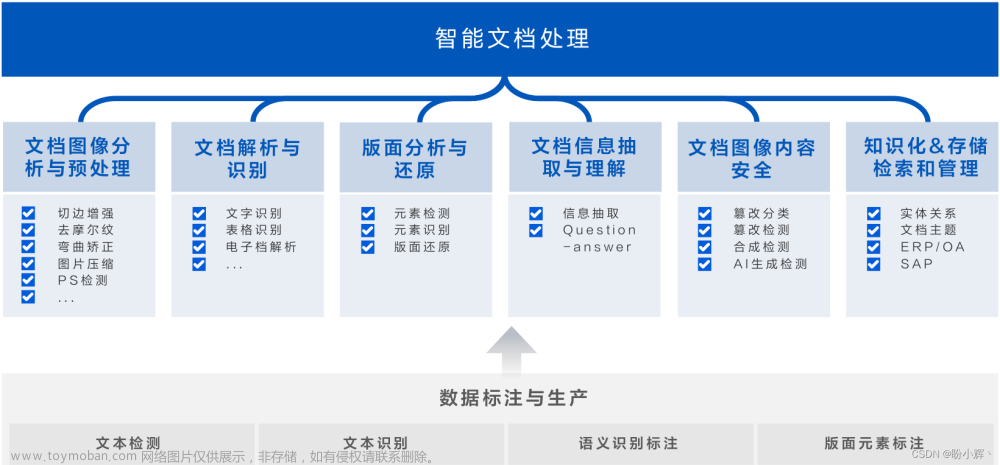
在合合信息科技丁凯博士所报告的《智能文档处理技术在工业界的应用与挑战》一题中,主要针对 智能文档图像处理 进行了探讨,而且站在合合信息的角度提出了一些技术难题的解决办法。
在文档图像的分析与预处理方面,首先对文档区域进行 ROI 提取,然后去除手指等干扰,再到形变(弯曲/倾斜透视)矫正、阴影/摩尔纹去除、图像增强等技术,实现将一张质量非常差的图片进行恢复和提升,可大幅提升文档智能扫描、文档识别分析、图转 Word/Excel 等业务性能。
这里的弯曲矫正早期的方法是基于文本行线拟合和坐标变换的方法进行的,从一个文本文档上下各找一条文本行线,将这两条线作为基线,然后通过全局变化、误差调整实现文档图像的矫正。但是这样的方式对于比较稀疏或者不均匀文档效果就很一般了,比较好的一个改进方法是基于偏移场学习的方法,先计算出每一个像素的偏移场,然后对每一个像素进行空间变换,这样就会比较好的对文档图像进行矫正。

摩尔纹去除的主要原理是先从文档背景中提取一个模块,将文档图像中的摩尔纹等干扰项进行提取,然后通过干扰去除模块对摩尔纹进行去除,最后将原图和去除干扰项的图进行融合,这样则会获得一张比较好的摩尔纹去除图。

以下是文档图像预处理的整体效果。

在文档图像篡改检测方面,传统的检测方式是基于 文件标记 进行检测,比如说该图片是否被 PS 处理过,但实际上即使经过 PS 处理,痕迹也是很容易被第三方抹除掉的。合合信息则是创新性的抓住图像篡改在像素层面的特征,将 频谱特征 和 图像特征 融合,最后通过 Position Embedding 检测篡改的位置信息。该处理方式效果显著。
针对文档图像处理和文档图像安全及落地应用方面,可以看到合合信息已经取得显著成就。我认为基于此还有一些可能的技术趋势,比如通过机器学习和自然语言处理技术,自动分类和标记文档图像,从而提高文档图像处理的准确性和效率;通过深度学习技术,自动从图像中提取关键信息,例如标题、摘要等,从而提高文档图像的信息提取效率;通过图像识别技术,自动检测文档图像中的不同信息,例如文字、标语、签名等,从而提高文档图像的识别准确率;通过语义分析技术,可以对文档图像进行语义分析和提取,从而实现自动分类和标记,例如可以根据图像中的文字内容自动分类和标记;
不仅如此,当下爆火的人工智能也完全可以与文档图像处理结合,比如自动识别和分类、文档理解、文档图像处理和安全自动化等。
■ 大模型时代的文档识别与理解
当下大模型如火如荼,比如 ChatGPT 的发布就引起了一阵热潮。在这样一个大模型时代,无论是哪个领域的研究都不可能回避大模型,包括文档识别与理解。但是在技术结合的过程当中大模型也难免会有一些不足,比如它在文档阅读的过程当中识别精度可能不高等,这些都需要去大规模的验证。而它的不足对于研究员和企业来说则是一种机遇,,是一种应用需求的增多,我们可以充分利用大模型的特征表示能力和语言能力,以及开发不同任务的专用模型和学习算法等。
在大模型的基础上,文档分析与识别的未来研究方向可以以 设计自动化 和 应用无人化 为目标,拓展文档中多元素、多内容、多语言、多场景、多类型,提升研究广度,增强文档语义理解能力、可解释性、可信度等研究深度。主要研究内容可以从版面分割、文本识别、表格识别、信息提取等方面拓展,涵盖文档电子化、人机交互、场景理解、信息检索/抽取、问答、推理决策等多个领域。
■ 篡改文本图像的生成与检测
目前图像篡改生成与检测的研究主要集中在自然图像,针对文本图像的相关研究较少。
篡改文本图像生成的主要任务是对场景图像中的指定文本进行编辑,在保留原始字体风格和背景纹理的同时使目标文本尽可能清晰,如隐私信息保护、拍照翻译等,如何做到在原来文档图像基础上修改内容且不留痕迹是主要研究内容。
早期的主流方法是 端到端场景文本擦除,通过条件对抗生成网络构建文本擦除器,该方法模型简单且提出了基本的文本擦除解决思路,但是在复杂文本图像的擦除上效果一般。到后来引入了 文本感知分支,用于提升网络对文本区域的捕捉能力,该方式引入多级擦除策略,擦除效果明显提升,但是网络结构较复杂,参数量厚重。再到后来使用基于 StyleGANg 的篡改生成框架,可同时生成原文本和目标文本模仿目标风格的图像,该方法能够在真实数据集上训练,但是网络结构依旧复杂,需依赖大量训练数据。

针对这些问题,中科大的谢教授提出的方法是 基于迭代局部擦除的场景文本擦除方法,显性解耦定位和背景重建分支,通过基于局部编辑的擦除操作防止对背景纹理的改动。构建平衡的多级擦除结构,共享多级之间的 Block 权重,并只监督最后一层输出,这样的方式在不使用对抗损失的情况下,擦除效果更好且网络结构更加简单。
圆桌讨论
在论坛的最后一个阶段是圆桌讨论,由各位与会的专家对 OCR 等技术进行深入探讨。

问题一:大模型技术对 OCR、文档图像分析和理解带来哪些机遇和挑战?
刘:gpt 仍需要大量数据量检测。邹:从技术路线来说,专业化大规模的预训练模型是可行。谢:结合 OCR、海量数据、理解能力很强,OCR 结果对模型有很大支持作用。廖:很好的机会点是将现有的 ocr 引擎、算法去和一些大模型做结合。丁:gpt 等大模型从技术路线等方面对我们很有启发,拥抱技术的革新;很多算法在一个数据集表现很好,换一个就不行,如果通过零样本、小样本等进行技术创新是值得探索的点。思考 ocr 领域的智能涌现是什么很重要。金:现有的 gpt 与现有的先进的 ocr 还是有差距的,在较难的关键信息抽取方面可能差距到五六十个点。利用大模型做 ocr 相关研究,关注技术的边界,是值得关注的。
问题二:是否需要构建 OCR 垂直领域的大模型?预计模型参数规模要有多大?什么数量级的训练数据?技术路径可能是什么?
刘:模型的能力都是有局限的,未来较好的文档预训练模型应该是多层级的、参数扩大到十亿几十个亿。邹:十个亿左右的参数在图像文本领域应该足够,一个大的趋势是集成和多任务的学习。谢:大模型应该是有垂直领域区分的,如教育、医药等,会取得更好效果。廖:数据方面,数据的数量不是最关键的,最关键的是数据的多样性。丁:大模型的参数量被广泛讨论,对比 gpt3 与 gpt4 就可以看出。数据量和样本多样性十分重要,十亿左右的参数量足够的。我用一千万的合成数据,不如十万的真实数据,这是 ocr 研究中的重要课题,在大模型框架下可能成为一个方向。
问题三:语言的大模型和视觉大模型的能力互补有怎样的关系,ocr 和 nlp 是什么关系,如果 ocr 是前处理,是不是 ocr 就会被削弱,如果 ocr 是目标,那大模型就会成为辅助?
廖:我倾向于 nlp,真正做到一个通用的人工智能,语言识别就是最核心的。如果技术发展到一定程度,人会使用工具,比如各类传感器,但是核心还是以语言逻辑思考为主,有了工具+语言,造出的人工智能跟人的差距就很小,打通感知与认知会成为人工智能的最终形态。刘:各类模型应该是并行并存的关系,如多模态的大模型 gpt,对标人也是如此,人看东西也是图像文字同时识别发挥作用的。
问题四:无监督预训练技术是构建大模型的基础性技术之一,如果要做 ocr 相关的大模型,其采用的无监督预训练技术路线可能有哪些?
丁:openai 说智能涌现就是一个算法遇到了巨大的数据量,在 gpt 出来前,大家都在关注 bert,个人猜测 gpt 还是将所有的数据输入后训练模型。金:还是通用的 ai 更被人关注使用。
…
对于本次大会深度延展的成果和未来发展方向,我们可以看出,人工智能、虚拟现实、增强现实等前沿技术已经成为当前图形图像产业的热点领域。
未来愿景
CCIG 2023 已圆满结束,这是一次非常成功的计算机图形学会议。作为一名 IT 技术博主,我本人对图像图形领域也有着极大的兴趣。所以本次论坛我全程进行了线上的参与,也产生了自己的一些想法。
技术创新是推动计算机视觉和人工智能发展的关键。在本次大会上,许多与会者展示了令人惊叹的新技术,例如由文本到图像的跨语言翻译、人工智能驱动的艺术创作等。
多学科合作是解决计算机视觉和人工智能问题的重要途径。在本次大会上,许多与会者分享了他们如何将不同领域的知识应用于计算机视觉和人工智能领域,以解决复杂问题。这表明跨学科合作是解决复杂问题的重要途径,需要各个领域的专家学者共同努力。
个人经验对计算机视觉和人工智能发展同样重要。许多优秀的研究成果都是由研究人员通过实践经验得出的,这表明个人经验对于计算机视觉和人工智能领域的研究同样重要,需要通过实践经验,才能更好地理解问题,并提出更好的解决方案。文章来源:https://www.toymoban.com/news/detail-449319.html
需要更多的教育和培训。有很多年轻的研究人员参加本次会议,这表明计算机视觉和人工智能领域需要更多的教育和培训。只有通过教育和培训,才能培养更多的优秀研究人员,推动技术的发展。文章来源地址https://www.toymoban.com/news/detail-449319.html
到了这里,关于智能图像处理技术:开启未来视觉时代的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!