optim.zero_grad() : 将模型的梯度参数设置为0,即清空之前计算的梯度值,在训练模型过程中,每次模型反向传播完成后,梯度都会累加到之前的梯度值上,如果不清空,这些过时的梯度将会影响下一次迭代的结果。因此,使用optim.zero_grad()来清空梯度避免这种情况的发生。保证每次迭代使用的都是当前轮次的新梯度,有效提高模型的训练的精度和稳定性;
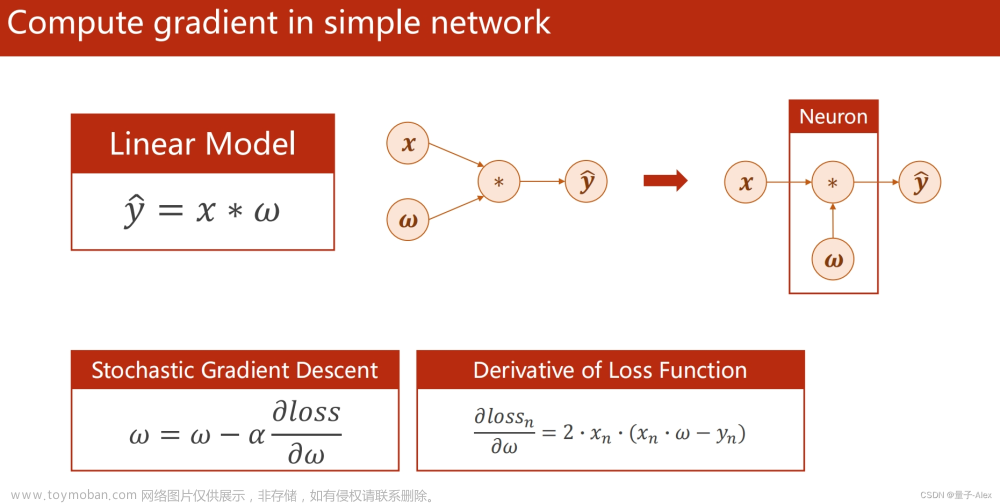
predict = model(img):这个过程被称为前向传播过程,在这个过程中,模型参数没有发生更新;
loss = crit(preds, labels): 这个是计算损失函数的过程;
loss.backward(): 这个过程是计算反向传播过程的函数,用户计算模型中所有可训练参数对于当前损失的梯度;backward函数实现了以下几个步骤:
- 根据之前定义的损失函数loss,先计算出当前模型中所有可以训练的参数对于该损失的梯度值;
- 通过链式法则将各个参数的梯度值相乘,得到整体模型中所有可训练的参数对于损失函数的梯度;
- 将梯度值应用于每一个可训练的参数,在调用该函数时,计算图中记录的各个变量的梯度值会被自动计算并累加到每个参数的.grad属性中。这个时候只会将grad参数保存在tensor中,不会去更新具体的每一个参数;在这个过程中,采用的求导方法一般是自动微分机制(Autograd),也就是利用计算图来构建一个计算过程,自动计算每一个节点的梯度,并保存在计算图中,从而方便快捷的计算反向传播过程,
optim.step(): 即对每一个参数,将其当前值减去对应的梯度乘以学习率,更新参数值;
model.zero_grad()和optim.zero_grad()的区别和联系: model.zero_grad(),指模型中包含的所有参数的梯度均被清空;optim.zero_grad(),此优化器需要更新的模型参数上的梯度被清空( optim = optim.Optimiers(model.parameters(), lr=args.lr));
在Pytorch中,当调用模型进行推理的时候,就会自动构建计算图。具体来说,每个节点表示一个操作或者一个函数,并将其输入和输出连接起来形成一个有向无环图(ADG)。在计算图中,每个节点都是一个Tensor对象,代表张量数据或梯度值;
在predict = model(img)的时候,pytorch会自动对输入数据img进行前向传播计算,构建计算图。假设模型有若干个卷积层、池化层和全连接层,并经过ReLU等激活函数激活,那么计算图将包含这些操作节点以及它们的Tensor输入和输出。图中节点之间的依赖关系表示了数据流的方向和计算过程。
在反向传播过程中,计算图会自动记录中间结果,从而可以计算每个操作节点的梯度值。这样可以非常方便地实现自动求导(auto-differentiation)和梯度下降(gradient descent)优化算法。因此,计算图是PyTorch中实现autograd机制的重要手段。
需要注意的是,如果只是进行预测而不需要计算梯度,可以使用torch.no_grad()上下文管理器来关闭自动求导功能,避免无用的计算和内存消耗。
fp16的运算
from torch.cuda.amp import autocast
model = MyModel()
optimizer = optim.Adam(model.parameters(), lr=0.01)
for epoch in range(num_epochs):
for inputs, targets in data_loader:
with autocast(True):
outputs = model(inputs)
loss = criterion(outputs, targets)
scaler.scale(loss).backward()
scaler.step(optimizer)
scaler.update()
torch.cuda.amp.autocast(True) 是PyTorch框架提供的一种混合精度训练技术,可以在保持数值精度的情况下提高模型的训练速度和内存效率。当启动autocast之后,在支持的硬件中,PyTorch会自动将float32类型的输入数据转化为float16类型,从而在相同内存下能够处理更多的数据;
在使用torch.cuda.amp.autocast(True)上下文管理的时候,这管理器内的所有浮点运算都会使用float16去进行计算,以减小内存占用,从而加快训练速度;里面包括了模型的前向传播过程和损失函数的计算,从而将这些过程中的所有浮点数运算都转换成float16的类型。
-
scaler.scale(): 用于缩放损失值、然后会执行scaler.scale().backward(), 反向传播,得到缩放后梯度值; -
scaler.step(): 执行反向传播的参数更新文章来源:https://www.toymoban.com/news/detail-449478.html -
scaler.update(): 更新GradScaler对象内部的参数,以便在下一次计算时能够正确地缩放梯度值。
计算模型参数的梯度值,并将其缩放回float32类型
使用优化器更新模型参数
重置GradScaler对象内部的状态,包括缩放后的损失值、缩放比例等文章来源地址https://www.toymoban.com/news/detail-449478.html
到了这里,关于pytorch 前向传播与反向传播代码+ fp16的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!
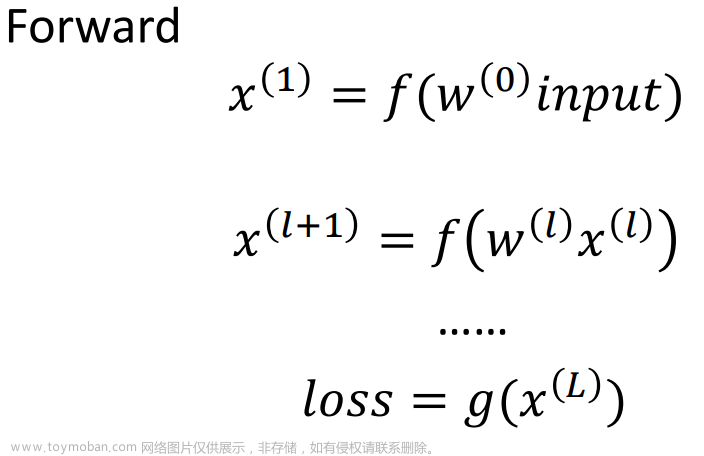

![[pytorch] 8.损失函数和反向传播](https://imgs.yssmx.com/Uploads/2024/01/823613-1.png)