1. 什么是Docker?
docker的介绍网上有很多,对于深度学习的认来讲,docker的好处就是直接把环境分享给他人,他人不需要再配置环境了。
比如我有一个目标检测的项目,我想分享给朋友,那么他首先需要在自己的电脑上配置好显卡驱动、CUDA、CuDNN,在拿到我的项目后,还需要安装各种依赖库,最后代码还不一定跑起来。
如果我是用了docker环境进行项目配置,我只需要将环境打包好后分享给朋友。他只需要安装好显卡驱动就行,什么cuda、pytorch之类的都在我分享的环境了。
实际上github很多项目都提供了docker方式,但是我们更多还是自己配置环境和安装对应的pytorch版本,自己调试代码尝试复现作者的项目。如果你使用了docker,分分钟就能将作者的环境在自己的电脑上复现,非常便捷。
2. 深度学习环境的基本要求
在本文,我将介绍docker的基本使用,以及总结可能遇到的bug的解决方法。
在dockerhub中,有很多现成的镜像可用,本文中会使用anibali/pytorch:1.10.2-cuda11.3-ubuntu20.04分享的镜像。
该镜像是ubuntu20+cuda11.3+pytorch1.10.2,根据描述(ENV NVIDIA_REQUIRE_CUDA=cuda>=11.3 brand=tesla,driver>=418,driver<419 driver>=450)我们只需要本机满足显卡驱动版本即可。其他版本的镜像可以去该作者的主页,他制作了非常多的镜像。
3. Docker的基本操作
3.1 在Windows上安装Docker
windows有桌面docker,所以安装过程比较简单,按照普通软件安装即可。
安装成功后,启动Docker Desktop软件,等待docker引擎启动后,我们就可以在cmd中使用docker命令了。比如执行sudo docker ps -a查看容器,如果没有报错证明ok了,当然现在我们还没有创建容器也不会输出什么有用的,不报错就行。
潜在的bug可能会与WSL有关,需要windows电脑安装有WSL,遇到这类bug可以参看网上的教程。
3.2 在Ubuntu上安装Docker
ubuntu可以通过apt安装,比较简单:
sudo apt-get update
sudo apt-get install \
apt-transport-https \
ca-certificates \
curl \
gnupg \
lsb-release
curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo gpg --dearmor -o /usr/share/keyrings/docker-archive-keyring.gpg
echo \
"deb [arch=$(dpkg --print-architecture) signed-by=/usr/share/keyrings/docker-archive-keyring.gpg] https://download.docker.com/linux/ubuntu \
$(lsb_release -cs) stable" | sudo tee /etc/apt/sources.list.d/docker.list > /dev/null
sudo apt-get update
sudo apt-get install docker-ce docker-ce-cli containerd.io
然后在终端执行:sudo docker ps -a查看容器,如果没有报错证明ok了,当然现在我们还没有创建容器也不会输出什么有用的,不报错就行。
3.3 拉取一个pytorch的镜像
现在docker安装好了,我们拉取一个上面这个配置好cuda和pytorch的镜像:docker pull anibali/pytorch:1.10.2-cuda11.3-ubuntu20.04
因为我之前下过,所以显示Already exists。等待镜像拉取完成,如果成功了,我们可以查询所有镜像:docker image ls
3.4 部署自己的项目
镜像我们有了,现在我们可以创建容器了。
容器就像是一个运行起来虚拟机,我们使用同一个镜像创建不同的容器,就像使用同一个windows系统安装盘(镜像),给不同电脑装系统,这些运行起来的电脑就是容器。注意容器的改变不会影响镜像,如果你在容器里部署好的项目,需要将容器导出为新的镜像分享即可。
创建容器的命令是:docker run -it --gpus all --name container_name anibali/pytorch:1.10.2-cuda11.3-ubuntu20.04 /bin/bash
在这个命令中,run是创建容器的指令,-it是交互式终端,因为创建的容器就相当于一个本机中的linux服务器,我们可以通过终端与容器交互。–gpus all这个就是使用本机的gpu,–name是给新建容器取个名字, anibali/pytorch:1.10.2-cuda11.3-ubuntu20.04就是要使用的镜像,/bin/bash是指定bash。
可以看到创建成功后,我们就直接进入了容器中,处于容器的/app目录下。
现在我们可以像使用云服务器那样部署自己的项目了,比如在本机终端中(非容器中)使用docker cp 将本机中的项目复制到容器中的/app目录下。
3.5 导出配置好项目的新镜像
现在我们假设你已经在容器中部署好自己的项目了,比如通过python train.py就可以训练,你想让你的朋友也能体验这个项目,那就需要将你的容器打包为镜像分享。
将容器打包为镜像为命令是:docker commit -m "some information" <容器ID> <image_name:version>
容器ID可以通过docker ps -a查询到,该命令可以查询所有容器信息。
image_name:version就是你自己定义的镜像的名字和版本号。
4. 分享新镜像
现在在本地已经有新镜像了,分享有两种:直接将镜像打包tar分享,或者上传到云,类似本文使用热心作者的镜像那样。
4.1 将镜像导出为tar分享给他人
打包导出的命令:docker save image_naem:version -o output_name.tar
-o就是output,也就是将镜像保存到什么文件。如果不报错在当前目录下能够看到你的镜像tar文件。
他人收到这个tar后,可以通过docker load -i xxx.tar完成加载,如果成功了可以通过docker image ls查看到该镜像。
4.2 或者将镜像推送到云仓库
云仓库可以自己去弄一个,当然dockerhub也可以免费上传分享,前提是你有一个dockerhub的账号。
首先在终端需要登录你的账号:docker login根据提示填写账号和密码。
首先给新镜像打tag:docker tag new_image:version username/new_image:version
比如sudo docker tag pt_test_image:0 thgpddl/pt_test_image:0
注意,请将thgpddl替换为自己的用户名,然后我们就可以看到新tag的镜像(实际上发现tag的和之前的镜像只是名字不一样,其ID是一样的)
然后开始上传:docker push thgpddl/pt_test_image:0
然后等待上传成功后(不过很可能出现408网络问题,可以尝试开启代理试试),在dockerhub就可以看到上传的镜像了。
5. 使用新镜像
在另一个安装了docker的电脑上使用分享的镜像很简单。如果新镜像上传到了dockerhub,则和拉取镜像一样:docker pull username/image_name:version。
如果是通过save保存到本地的,镜像是一个tar包,则可以在新电脑上通过:docker load -i new_image.tar加载。
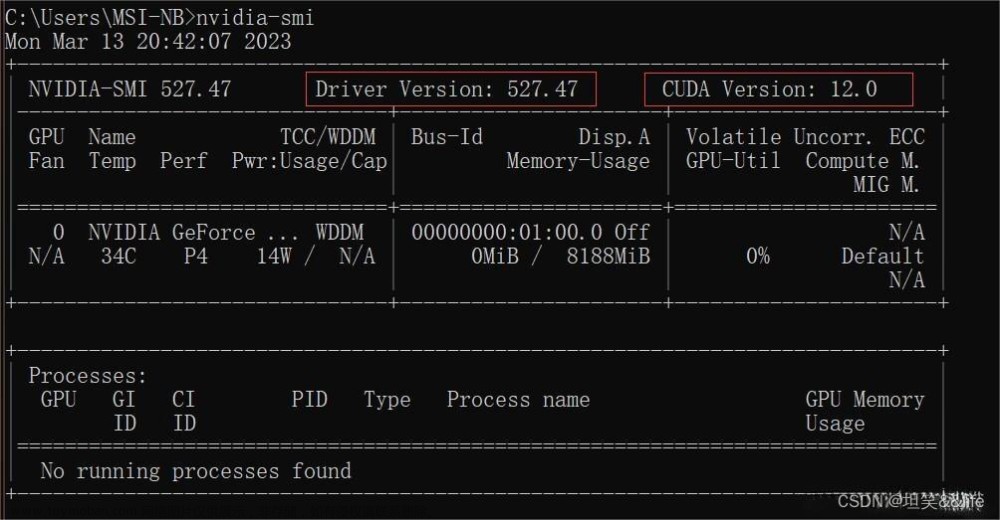
6. 跨平台造成nvidia-smi不可用的问题
注意:因为windows的docker底层使用的WSL,和Linux不一样,所以在一个平台制作导出的镜像在另一个平台使用时,可能会出现gpu不可用的问题。比如在Ubuntu系统加载Windows平台导出的镜像时,通过docker run --gpus all创建容器后,在容器中使用nvidia-smi会报错:NVIDIA-SMI couldn't find libnvidia-ml.so library in your system. Please make sure that the NVIDIA Display Driver is properly installed and present in your system.Please also try adding directory that contains li PATH. 那么接下来的内容就会详细如何解决跨平台无法使用GPU的问题
首先会出现问题的情况有(同平台是没有问题的,比如linux和linux,windows和windows):
| 取个名字 | 导出镜像的平台 | 使用镜像的平台 | 问题 |
|---|---|---|---|
| win2linux | Widnows | Ubuntu |
容器内使用nvidia-smi命令报错:NVIDIA-SMI couldn’t find libnvidia-ml.so library in your system. |
| linux2win | Ubuntu | Windows |
创建容器时使用–gpus参数就会报错:libnvidia-ml.so.1- file exists- unknown |
6.1 确认是该问题
我在windows制作的镜像在ubuntu加载后,无法使用nvidia-smi命令并报错NVIDIA-SMI couldn’t find libnvidia-ml.so library in your system.,那么我们需要先确认是不是本节要讨论的问题,所以我们要在容器中查询:
-
显卡是否存在:
lspci | grep -i nvidia(需要安装sudo apt update && sudo apt install pciutils),可以看到存在显卡2208(十六进制),然后在显卡查询查询2208得知是3080ti,就是我的显卡。
-
显卡驱动是否存在:
cat /proc/driver/nvidia/version,可以看到在容器中是可以查询到宿主机的显卡驱动的,证明没问题。
好了,说明显卡和显卡驱动都是正常的,nvida-smi就是不可用
现在请根据自己是哪一个跨平台情况按步骤解决把
6.2 win2linux问题如何解决?
本质问题如图,解决办法就是重新建立软链接,不过方法多样而已。
6.2.1 手动创建软链接
在linux加载来自windows的镜像后,进入容器后使用nvidia-smi命令会报错:
首先查询软链接情况:ldconfig,看到很多libnvidia和libcuda软链接为empty,所以我们目标就是重新建立软链接
进入目录:cd /usr/lib/x86_64-linux-gnu,通过find -name "libnvidia-ml.so"查询显卡驱动515.43.04,请记住这个。
建立libnvidia-ml.so的软链接:
# libnvidia-ml.so.515.43.04 -> libnvidia-ml.so.1
sudo rm -f libnvidia-ml.so.1
sudo ln -s libnvidia-ml.so.515.43.04 libnvidia-ml.so.1
建立libcuda.so的软链接
# libcuda.so.515.43.04->libcuda.so.1
sudo rm -f libcuda.so.1
sudo ln -s libcuda.so.515.43.04 libcuda.so.1
515.43.04是我的本机驱动,请改为自己的。
测试一下:
可以看到nvidias-mi命令可以用了,然后在python中导入torch后创建一个张量放到cuda上去没有报错,说明cuda可用了。
6.2.2 使用Dockfile自动完成
Dockfile就是创建镜像的一种方法,这里大概原理就是在镜像1的基础上,生成镜像2,而在生成过程中自动建立libnvidia-ml.so和libcuda.so的软链接。
注意,与上面方法不同在于,上面的方法是从镜像1创建容器后,到容器里手动创建软链接,然后该容器就可以使用cuda了。本节方法是在镜像1上创建软链接,得到新的镜像,然后就可以直接从镜像创建cuda可用的容器。
那么现在,比如我现在要在linux下使用来自windows的镜像thgpddl/win_1050:0,首先建立createlink.sh文件,内容如下:
# 查找libnvidia-ml.so.driver_version文件,并保存driver_version版本号
libnvidia_ml_file=$(find /usr/lib/x86_64-linux-gnu/ -name 'libnvidia-ml.so.*'|grep -v libnvidia-ml.so.1)
driver_version=${libnvidia_ml_file#/usr/lib/x86_64-linux-gnu/libnvidia-ml.so.}
echo "[success]:find GPU driver version=$driver_version"
# 删除libnvidia-ml.so.driver_version.1原本存在的软链接,并且新建软链接:libnvidia-ml.so.1.driver_version -> libnvidia-ml.so.1
rm -f /usr/lib/x86_64-linux-gnu/libnvidia-ml.so.1
ln -s "$libnvidia_ml_file" /usr/lib/x86_64-linux-gnu/libnvidia-ml.so.1
echo "[success]:create ls: libnvidia-ml.so.1.$driver_version -> libnvidia-ml.so.1"
# 删除libcuda.so.driver_version原本存在的软链接,并且新建软链接:libcuda.so.1.driver_version -> libcuda.so.1
rm -f /usr/lib/x86_64-linux-gnu/libcuda.so.1
ln -s "/usr/lib/x86_64-linux-gnu/libcuda.so.1.$driver_version" /usr/lib/x86_64-linux-gnu/libcuda.so.1
echo "[success]:create ls: libcuda.so.1.$driver_version -> libcuda.so.1 -> libcuda.so"
然后在同目录下新建Dockerfile文件(D大写且没有后缀),内容:
FROM thgpddl/win_1050:0 # 优先从docker image找,没有就从dockerhub找
WORKDIR /app # 创建工作目录/app
COPY ./createlink.sh . # 将本机的createlink.sh复制到镜像中的/app目录下,注意后面有个点,代表WORKDIR文件夹
USER root # 切换root用户
RUN cd /app && ./createlink.sh # 进入 /app执行createlink.sh
然后创建新镜像:sudo docker build -t new_image_name . 注意最后的点,是指Dockerfile所在的目录(终端应当进入Dockerfile和createlink.sh所在的目录)
该Dockerfile大概意思就是使用thgpddl/win_1050:0作为基础镜像,然后在镜像中创建/app文件夹,然后将createlink.sh复制到镜像里,切换到root用户,进入/app目录并执行createlink.sh自动创建软链接。至此得到软链接已经创建的新镜像了。
在实际使用中,createlink.sh是不用更改的,如果你想分享你的镜像,那么直接给一个文件夹,其中包含createlink.sh和Dockerfile文件,Dockerfile第一行改为你的镜像即可。
6.3 linux2win问题如何解决?
在windows加载来自linux的镜像后,进入容器后使用nvidia-smi命令会报错:
从最后一行大概是说创建这个libnvidia-ml.so.1失败,因为它已经存在。实际上这就是win2linux是我们创建的软链接,可以在windows上它不能覆盖,否则应该能自动覆盖正常运行了。既然windows的docker不能自动覆盖掉,我们帮它删除即可。
基本原理如下,其实无论下面哪种方法都是要删掉两个so软链接。
6.3.1 在WSL使用时手动删除软链接
当然很多时候镜像发布者没有考虑到这个问题,作者在ubuntu下使用–gpus配置好环境后直接发布了,所以我们需要自己去删除libnvidia-ml.so.1和libcuda.so.1文件。
因为启动命令使用–gpus all使用gpu,所以会调用libnvidia-ml.so.1,那么我们不使用gpu,应该能创建容器,然后进去删掉该文件,然后再docker commit为镜像,然后在新镜像就能使用gpu了(此时没有libnvidia-ml.so.1,docker就能创建成功了)
大概意思如下图,镜像1和镜像2的区别在于镜像2删掉了来自ubuntu的libnvidia-ml.so.1(和libcuda.so.1)
首先不使用gpu创建容器:docker run -it --name container_name image_name /bin/bash
然后删除两个so文件:
(cmd) docker run -it --name container_name image_name /bin/bash
(容器内) sudo rm -f /usr/lib/x86_64-linux-gnu/libnvidia-ml.so.1
(容器内) sudo rm -f /usr/lib/x86_64-linux-gnu/libcuda.so.1
然后形成新镜像:docker commit -m "some information" container_name new_image_name:0
现在我们得到了一个可以在windows下正常使用的镜像了:docker run -it --gpus all --name container_name new_image_name:0 /bin/bash
6.3.2 使用Dockerfile自动完成
上节是在非gpu容器中删除两个so.1文件,然后制作为新镜像就可以使用gpu。实际上我们也可以借助Dockerfile来自动在创建新镜像时删除两个so.1文件,一步到位。
Dockerfile文件的内容:
FROM thgpddl/linux2win:0
USER root
RUN rm -rf /usr/lib/x86_64-linux-gnu/libnvidia-ml.so.1 /usr/lib/x86_64-linux-gnu/libcuda.so.1
然后创建新镜像:sudo docker build -t new_image_name . 注意最后的点,是指Dockerfile所在的目录(终端应当进入Dockerfile所在的目录)
其实该Dockerfile很简单,就是使用基础镜像thgpddl/linux2win:0,然后切换root用户,删除libnvidia-ml.so.1和libcuda.so.1,得到新的镜像文件。
6.3.3 不使用–gpus all的容器打包(针对镜像发布者)
因为linux的镜像在windows使用报错是因为创建libnvidia-ml.so.1失败,因为它已经存在,libnvidia-ml.so.1是在ubuntu中使用gpu创建的。如果ubuntu中不使用gpu,就不会有libnvidia-ml.so.1文件,那么就可以直接在windows上使用而不报错。
其实不用太复杂,我们在ubuntu容器中配置好自己的项目后,然后直接删除两个so.1文件后(确保你不再使用gpu,因为删除后在当前容器就不能使用gpu),直接docker commit导出镜像即可。因为该镜像本身没有两个so.1文件,所以可以直接在Windows或者其他linux中的docker中使用–gpus。
因为ubuntu镜像在windows中报错是因为windows要产生so.1文件,但是ubuntu镜像中存在so.1文件且windows无法强制覆盖。现在好了,我发布镜像时直接打包时删除so.1文件,在win下就不会报错了。文章来源:https://www.toymoban.com/news/detail-449640.html
7. 总结
- WSL的镜像在Linux下使用需要设置软链接,Linux镜像在WSL下使用时需要删除软链接。
- libcuda.so.version和libnvidia-ml.so.version,这里的libcuda.so.derver不是安装cuda生产的,而是安装驱动生成的,提供该驱动调用cuda的api。
8. 常见问题debug
- error during connect: in the default daemon configuration on Windows, the docker client must be run with elevated privileges to connectxxxxx:
可能是docker desktop自动更新导致了一些问题,重启docker就好了 - 解决Docker 一直starting 的办法:解决Docker 一直starting 的办法
- WIN10家庭版 找不到Hyper-V的解决办法
- libGL.so.1
 一般是安装使用opencv造成的,直接
一般是安装使用opencv造成的,直接pip install opencv-python-headless - 权限问题,在run指定参数–user=root也是可以解决的,但是可能也是文件夹本身需要chmod改权限
- windows中wsl是默认放在c盘的,非常占用磁盘,【转载】Win10/11 更改 WSL Docker Desktop 存储路径
- docker 问题
 不断重启即可,要退出quit那种重启
不断重启即可,要退出quit那种重启
Reference
win10 WSL2 Docker 与 Linux Docker
WSL2上Docker打包的镜像迁移到Ubuntu服务器上无法使用GPU
libcuda.so.1: cannot open shared object file: No such file or directory
WSL启动nvidia-docker镜像:报错libnvidia-ml.so.1- file exists- unknown文章来源地址https://www.toymoban.com/news/detail-449640.html
到了这里,关于基于Docker的深度学习环境NVIDIA和CUDA部署以及WSL和linux镜像问题的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!