介绍地址:https://ai.facebook.com/research/publications/segment-anything/
演示地址:https://segment-anything.com/demo#
论文:https://scontent-akl1-1.xx.fbcdn.net/v/t39.2365-6/10000000_900554171201033_1602411987825904100_n.pdf?_nc_cat=100&ccb=1-7&_nc_sid=3c67a6&_nc_ohc=Ald4OYhL6hgAX-FZV7S&_nc_ht=scontent-akl1-1.xx&oh=00_AfDDJRfDV85B3em0zMZvyCIp882H7HaUn6lo1KzBtZ_ntQ&oe=643500E7
简介:“分割任何物体”(SA)项目:这是一个新的任务、模型和用于图像分割的数据集。我们使用高效的模型在数据收集循环中,建立了迄今为止最大的分割数据集,涵盖了超过1亿张授权和尊重隐私的图像。该模型经过设计和训练,可立即响应,因此可以在新的图像分布和任务上进行零样本迁移。
Meta评估了其在众多任务上的能力,并发现它的零样本性能令人印象深刻——通常与甚至优于以前的全监督结果相竞争。我们将发布“分割任何物体模型”(SAM)和相应的数据集(SA-1B),其中包含10亿个掩模和1100万张图像,以促进计算机视觉基础模型的研究。https://segment-anything.com

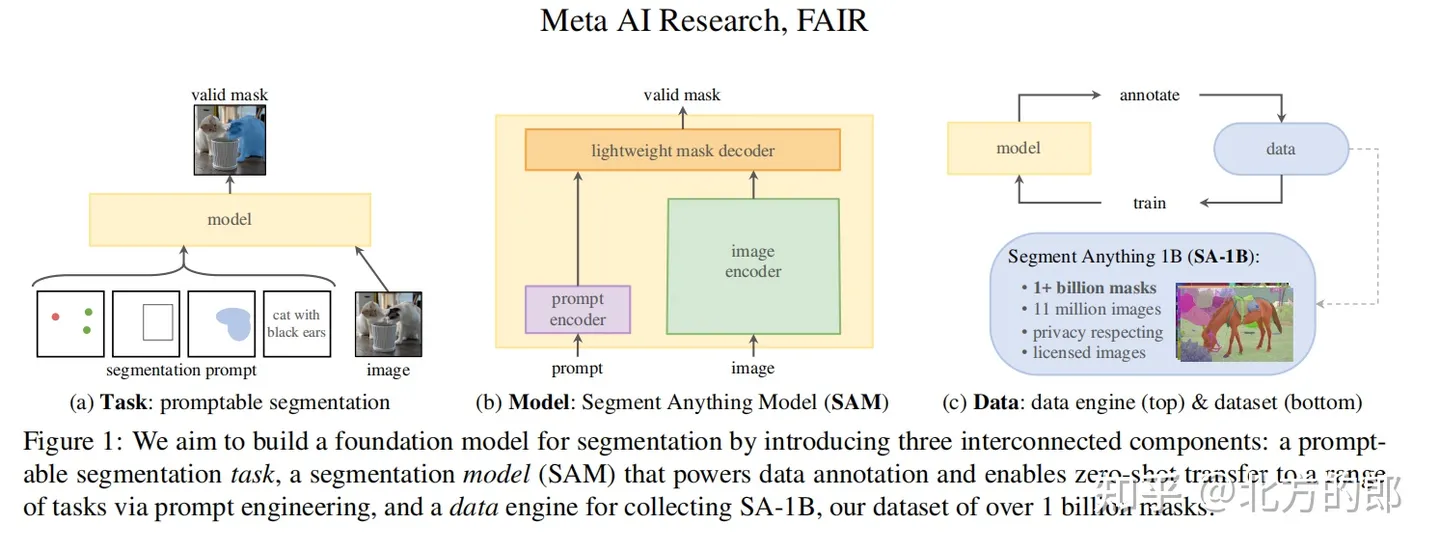
整体流程
Meta提出:大规模预训练的语言模型正在使用零-shot和少量-shot的泛化性能方面在NLP领域进行革命性的改变。这些“基础模型”可以将任务和数据分布泛化到训练期间未曾见过的领域。这种能力通常是通过prompt engineering实现的,即使用手工制作的文本来提示语言模型为当前任务生成有效的文本响应。当使用来自Web的丰富文本语料库进行扩展和训练时,这些模型的零-shot和少量-shot的性能表现出人意料的好,甚至在某些情况下与微调模型相媲美。经验趋势表明,这种行为随着模型规模、数据集大小和总的训练计算力的增加而不断改善。基础模型在计算机视觉领域也得到了探索,尽管探索程度较少。最显著的例子可能是从Web上对齐文本和图像。例如,CLIP [82]和ALIGN [55]使用对比学习来训练文本和图像编码器以对齐这两种模态。训练后,经过设计的文本提示可以实现对新的视觉概念和数据分布的零-shot泛化。这种编码器也可以有效地与其他模块组合,以实现下游任务,例如图像生成(例如DALL·E [83])。虽然在视觉和语言编码器方面取得了很多进展,但计算机视觉包括许多超出此范围的问题,对于其中许多问题,缺乏丰富的训练数据。在本研究中,我们的目标是建立一个图像分割的基础模型。也就是说,我们希望开发一个可提示的模型,并使用一个能够实现强大泛化的任务在广泛的数据集上进行预训练。利用该模型,我们旨在使用prompt engineering在新的数据分布上解决一系列下游分割问题。
关键点:
任务(§2)。在自然语言处理领域,以及近年来的计算机视觉领域,基础模型是一种有前途的发展,通常可以通过“提示”技术实现对新数据集和任务的零样本和小样本学习。受到这一工作线路的启发,我们提出了可提示分割任务,即旨在根据任何分割提示(参见图1a)返回有效的分割掩码。提示简单地指定要在图像中分割的内容,例如,提示可以包括标识对象的空间或文本信息。要求输出掩码有效意味着即使提示模棱两可并可能涉及多个对象(例如,衬衫上的一个点可能表示衬衫或穿着衬衫的人),输出也应为至少其中一个对象提供一个合理的掩码。我们使用可提示分割任务作为预训练目标,并通过提示工程来解决各种下游分割任务。
模型(§3)。可提示分割任务和实际使用目标对模型架构施加了约束。特别是,模型必须支持灵活的提示,需要在摊销实时计算掩码以允许交互式使用,并且必须具有歧义感知能力。令人惊讶的是,我们发现一个简单的设计可以满足所有三个约束条件:一个强大的图像编码器计算图像嵌入,一个提示编码器嵌入提示,然后两个信息源在一个轻量级的掩码解码器中进行组合以预测分割掩码。我们将这个模型称为“Segment Anything Model”或SAM(参见图1b)。通过将SAM分解为图像编码器和快速提示编码器/掩码解码器,可以重用相同的图像嵌入(并摊销其成本),并使用不同的提示。给定一个图像嵌入,提示编码器和掩码解码器在Web浏览器中从提示预测掩码需要约50ms。我们专注于点、框和掩码提示,并且还使用自由形式文本提示呈现初始结果。为了使SAM具有歧义感知能力,我们设计它预测单个提示的多个掩码,从而自然地处理歧义,例如衬衫与人的例子。
数据引擎(§4)。为了实现对新数据分布的强大泛化能力,我们发现有必要在大量且多样化的掩码上训练SAM,这超出了任何现有分割数据集。虽然基础模型的典型方法是在线获得数据[82],但掩码并不是自然丰富的,因此我们需要一种替代策略。我们的解决方案是构建一个“数据引擎”,即我们与模型在回路中的数据集标注一起开发(参见图1c)。我们的数据引擎分为三个阶段:辅助手动、半自动和全自动。在第一阶段,SAM协助注释者注释掩码,类似于经典的交互式分割设置。在第二阶段,SAM可以通过提示可能的对象位置自动生成部分对象的掩码,注释者专注于注释其余对象,从而增加掩码的多样性。在最后一个阶段,我们用前景点的常规网格提示SAM,每个图像平均产生约100个高质量的掩码。
数据集(§5)。我们最终的数据集SA-1B包括来自1100万个经过许可且保护隐私的图像的1亿多个掩码(见图2)。使用我们数据引擎的最终阶段完全自动地收集的SA-1B比任何现有的分割数据集[66, 44, 117, 60]都多出400倍,如我们广泛验证的那样,掩码具有高质量和多样性。除了用于训练SAM以实现强大的稳健性和泛化能力外,我们希望SA-1B成为旨在构建新基础模型的研究的有价值的资源。
负责任的AI(§6)。我们研究并报告了在使用SA-1B和SAM时可能存在的公平性问题和偏差。SA-1B中的图像涵盖了一组地理和经济多样化的国家,我们发现SAM在不同的人群中表现相似。我们希望这将使我们的工作在实际应用场景中更具公平性。我们在附录中提供了模型和数据集卡片。
实验(§7)。我们对SAM进行了广泛的评估。首先,使用23个不同的分割数据集,我们发现SAM可以从单个前景点生成高质量的掩模,通常只比手动注释的地面真实值稍微低一些。其次,我们发现在使用提示工程的零-shot转移协议下,在各种下游任务中,包括边缘检测、目标提议生成、实例分割以及文本到掩模预测的初步探索中,我们都获得了一致强劲的定量和定性结果。这些结果表明,SAM可以与提示工程一起直接用于解决涉及对象和图像分布超出SAM训练数据的各种任务。然而,仍有改进的空间,我们在§8中进行了讨论。
发布。我们将SA-1B数据集发布供研究用途,并在https://segment-anything.com上以宽松的开放许可(Apache 2.0)提供SAM。我们还通过在线演示展示了SAM的能力。
 文章来源:https://www.toymoban.com/news/detail-449856.html
文章来源:https://www.toymoban.com/news/detail-449856.html
具体请看论文文章来源地址https://www.toymoban.com/news/detail-449856.html
到了这里,关于Meta:segment anything的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!