节点数据清空处理
ES数据节点清空处理,指的就是数据的迁移,将在数据节点A的数据迁移得到其他数据节点。
可以通过动态配置cluster.routing.allocation.exclude_ip,来实现,以下是举例的操作步骤:
1、查询集群原来的配置
curl -X GET "http://{ip}:{port}/_cluster/settings?pretty"
出于某种原因,集群中原来就已经排除了某些数据节点,这些配置在未确定的情况下保持不动,数据还是排除。
{
"persistent": {
"cluster": {
"routing": {
"allocation": {
"exclude": {
"_ip": "{ip}"
}
}
}
}
},
"transient": {
"cluster": {
"routing": {
"allocation": {
"exclude": {
"_ip": "{ip}"
}
}
}
}
}
}
2、清空节点数据
清空数据节点的数据,{ip}:集群任意节点IP,{port}:http服务端口号,{ip1},{ip2}:需要排除数据的IP,将原来配置需要排除数据的节点IP加上本次排除数据的节点IP,以逗号分隔。
curl -X PUT "http://{ip}:{port}/_cluster/settings?pretty" -H 'Content-Type: application/json' -d'
{
"persistent" :{
"cluster.routing.allocation.exclude._ip" : "{ip1},{ip2}"
},
"transient" :{
"cluster.routing.allocation.exclude._ip" : "{ip1},{ip2}"
}
}'
命令结果:
{
"acknowledged": true,
"persistent": {
"cluster": {
"routing": {
"allocation": {
"exclude": {
"_ip": "{ip1},{ip2}"
}
}
}
}
},
"transient": {
"cluster": {
"routing": {
"allocation": {
"exclude": {
"_ip": "{ip1},{ip2}"
}
}
}
}
}
}
如果集群状态不好,命令可能超时。通过以下命令查询配置是否成功
curl -X GET "http://{ip}:{port}/_cluster/settings?pretty"
看结果中是否有配置的内容。
{
"persistent": {
"cluster": {
"routing": {
"allocation": {
"exclude": {
"_ip": "{ip1},{ip2}"
}
}
}
}
},
"transient": {
"cluster": {
"routing": {
"allocation": {
"exclude": {
"_ip": "{ip1},{ip2}"
}
}
}
}
}
}
3、检查是否排空数据
检查数据节点上是否存在数据,结果中的IP列没有需要下线的IP,说明数据已经排尽,满足机器下线条件了。有的集群分片可能很多,可以将结果输出到文件查询。
curl -X GET "http://{ip}:{port}/_cat/shards?v&pretty&s=ip:desc"
index shard prirep state docs store ip node
config_s-20211108 1 r STARTED 0 130b 192.168.1.1 es03-prd
config_s-20211108 2 r STARTED 0 130b 192.168.1.1 es03-prd
config_s-20211108 0 p STARTED 0 130b 192.168.1.1 es03-prd
.monitoring-data-2 0 r STARTED 5 15.7kb 192.168.1.1 es03-prd
config_s-20211107 1 r STARTED 0 130b 192.168.1.1 es03-prd
config_s-20211107 2 r STARTED 0 130b 192.168.1.1 es03-prd
config_s-20211107 0 p STARTED 0 130b 192.168.1.1 es03-prd
4、数据清空失败场景
1、集群中配置了require
GET /_cluster/settings
清空或者将需要删除节点去掉
PUT /_cluster/settings
{
"persistent" :{
"cluster.routing.allocation.require._ip" : null
},
"transient" :{
"cluster.routing.allocation.require._ip" : null
}
}
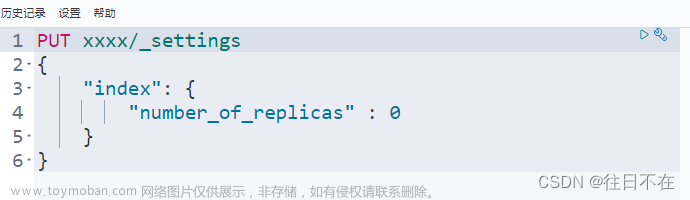
2、索引中配置了require
GET myindex/_settings
清空或者将需要删除节点去掉
PUT myindex/_settings
{
"index.routing.allocation.require._ip": null
}
5、加快分片迁移
可以通过修改索引恢复的速度,和集群可以恢复的节点数进行控制。同时在均衡的数量主节点初始化的数量也会有影响。需要结合集群压力配置。不可以过大。文章来源:https://www.toymoban.com/news/detail-450423.html
PUT _cluster/settings
{
"persistent" :{
"cluster.routing.allocation.node_concurrent_recoveries" : 20,
"cluster.routing.allocation.node_initial_primaries_recoveries": 20,
"cluster.routing.allocation.cluster_concurrent_rebalance": 20,
"indices.recovery.max_bytes_per_sec":"80mb"
},
"transient" :{
"cluster.routing.allocation.node_concurrent_recoveries" : 20,
"cluster.routing.allocation.node_initial_primaries_recoveries": 20,
"cluster.routing.allocation.cluster_concurrent_rebalance": 20,
"indices.recovery.max_bytes_per_sec":"80mb"
}
}
indices.recovery.max_bytes_per_sec默认40mb。文章来源地址https://www.toymoban.com/news/detail-450423.html
到了这里,关于【ES实战】节点数据的清空的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!