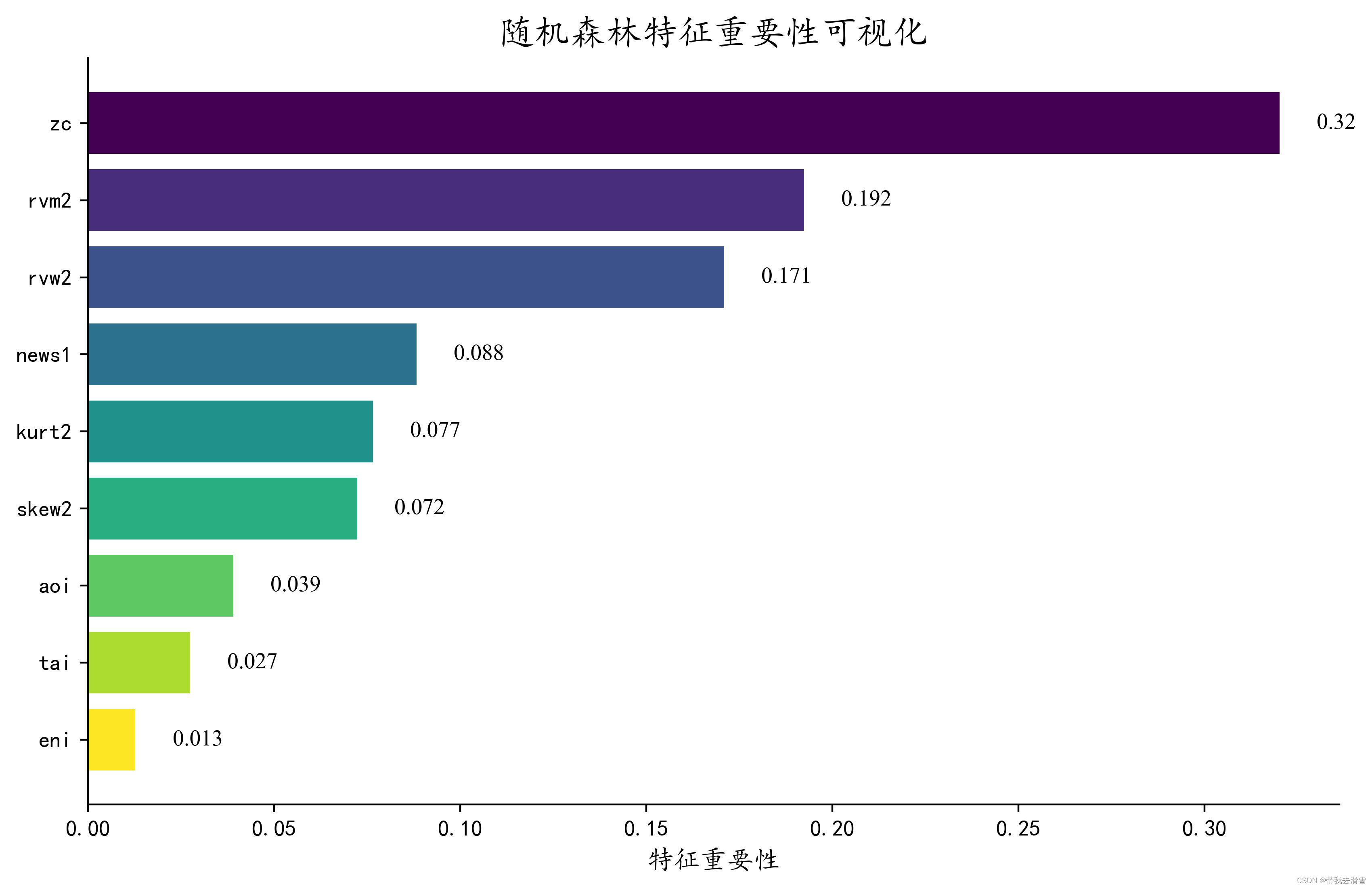
方法
特征重要性是指特征对目标变量的影响程度,即特征在模型中的重要性程度。判断特征重要性的方法有很多,下面列举几种常用的方法:
1. 基于树模型的特征重要性:例如随机森林(Random Forest)、梯度提升树(Gradient Boosting Tree)等模型可以通过计算每个特征在树模型中被使用的次数或者被用来进行分裂的重要性,来衡量特征的重要性。
2. 基于线性模型的特征重要性:例如线性回归(Linear Regression)等模型可以通过计算每个特征的系数大小来衡量特征的重要性。
3. 基于特征选择的特征重要性:例如方差分析(ANOVA)、互信息(Mutual Information)等方法可以通过分析特征与目标变量之间的关系来选择重要的特征。
4. 基于神经网络的特征重要性:例如通过计算神经网络中每个特征对输出的敏感度来衡量特征的重要性。
5. SHAP(SHapley Additive exPlanations)值方法是一种解释模型预测结果的方法,可以用来评估每个特征对于预测结果的贡献程度。SHAP值方法基于Shapley值的概念,是一种基于博弈论的特征重要性评估方法。
SHAP值方法可以为每个特征生成一个SHAP值,表示该特征对于某个样本的预测结果的影响程度。SHAP值可以通过各种模型进行计算,包括线性模型、树模型、神经网络等等。
SHAP值方法的优点是能够考虑特征之间的交互作用,同时可以针对不同类型的模型进行解释。不过,SHAP值方法也存在一些局限性,例如计算复杂度较高,对于高维数据和复杂模型的解释可能存在困难等。
需要注意的是,不同的特征重要性方法适用于不同的模型和数据类型,选择合适的方法需要根据实际情况进行选择。同时,特征重要性仅是指特征在模型中的重要性,不能用于判断特征是否有用或者是否需要进行特征工程处理。
2. 优缺点
以下是各种方法的优缺点:
特征选择方法:
优点:
可以快速筛选出对模型性能影响较大的特征,减少计算成本;
简单易懂,容易解释。
缺点:
不能考虑特征之间的相互作用;
在保留较少特征的情况下,可能会丢失一些信息。
基于树的方法:
优点:
可以考虑特征之间的相互作用;
结果易于解释,可以为每个特征给出重要性得分;
可以通过可视化来理解模型中每个特征的贡献。
缺点:
在处理高维稀疏数据时可能存在问题;
在特征之间具有强相关性的情况下,可能会出现误差;
基于模型的方法:
优点:
可以考虑特征之间的相互作用;
对各种类型的数据适用。
缺点:
通常需要较多的计算资源;
结果可能会受到特征之间的相关性影响;
可能会因为模型的选择而影响结果。
SHAP值方法:
优点:
能够考虑每个特征对每个样本的贡献;
能够处理特征之间的相关性;
可以可视化每个特征对模型输出的影响,易于解释。
缺点:
需要较多的计算资源;
结果可能会受到模型的选择和参数的影响。
总之,每种方法都有其优缺点,选择合适的方法应该根据具体问题和数据特点来决定。同时,还需要注意特征重要性只是模型解释的一部分,不能完全代替模型的评估和调整。
3. 举例说明
特征重要性分析是指在机器学习模型中,评估每个特征对模型预测结果的影响程度。以下是几种常用的特征重要性分析方法以及相应的例子:
基于树模型的特征重要性分析:
在树模型中,特征重要性通常是通过度量每个特征被选择为节点分裂的次数来衡量的。例如,在随机森林模型中,可以使用scikit-learn库中的feature_importances_属性来获取每个特征的重要性,如下所示:
from sklearn.ensemble import RandomForestRegressor
from sklearn.datasets import make_regression
X, y = make_regression(n_features=4, random_state=0)
rf = RandomForestRegressor(random_state=0)
rf.fit(X, y)
print(rf.feature_importances_)
# array([0.18146984, 0.36514659, 0.37589063, 0.07749294])
这表示第2个和第3个特征对模型的预测结果具有更高的影响力。
基于线性模型的特征重要性分析
在线性模型中,可以使用系数大小来评估每个特征的重要性。例如,在岭回归模型中,可以使用scikit-learn库中的coef_属性来获取每个特征的系数大小,如下所示:
from sklearn.linear_model import Ridge
from sklearn.datasets import make_regression
X, y = make_regression(n_features=4, random_state=0)
ridge = Ridge(alpha=1.0)
ridge.fit(X, y)
print(ridge.coef_)
# array([28.70881903, 74.85495747, 90.56271467, 11.61467289])
这表示第3个特征对模型的预测结果具有更高的影响力。
基于神经网络的特征重要性分析:
在神经网络中,可以使用反向传播算法计算每个特征对损失函数的梯度,以此来评估每个特征的重要性。例如,在PyTorch中,可以通过以下方式计算每个特征的梯度大小:
import torch
import torch.nn as nn
from torch.autograd import Variable
X = torch.randn(10, 4)
y = torch.randn(10, 1)
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.fc = nn.Linear(4, 1)
def forward(self, x):
x = self.fc(x)
return x
net = Net()
criterion = nn.MSELoss()
optimizer = torch.optim.SGD(net.parameters(), lr=0.01)
inputs = Variable(X)
labels = Variable(y)
for i in range(100):
optimizer.zero_grad()
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
print(net.fc.weight.grad.abs().mean(dim=1))
optimizer.step()
输出每个特征的梯度大小,如下所示:
tensor([0.2078, 0.4516, 0.3481, 0.3676])
tensor([0.1563, 0.4035, 0.3115, 0.3285])
tensor([0.1156, 0.3644, 0.2788, 0.2937])
...
这表示第2个特征对损失函数的梯度大小最大,因此对模型的预测结果具有更高的影响力。
基于模型不确定性的特征重要性分析:
在一些模型中,可以使用模型不确定性来评估每个特征的重要性,例如随机神经网络(Random Neural Networks)和蒙特卡洛Dropout。例如,在蒙特卡洛Dropout模型中,可以使用dropout层的标准差来评估每个特征的重要性,如下所示:
import torch
import torch.nn as nn
from torch.autograd import Variable
X = torch.randn(10, 4)
y = torch.randn(10, 1)
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.fc1 = nn.Linear(4, 10)
self.dropout = nn.Dropout(p=0.5)
self.fc2 = nn.Linear(10, 1)
def forward(self, x):
x = nn.functional.relu(self.fc1(x))
x = self.dropout(x)
x = self.fc2(x)
return x
net = Net()
criterion = nn.MSELoss()
optimizer = torch.optim.SGD(net.parameters(), lr=0.01)
inputs = Variable(X)
labels = Variable(y)
for i in range(100):
optimizer.zero_grad()
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
print(net.dropout.std(dim=0))
optimizer.step()
这将输出每个特征的标准差,如下所示:
tensor(0.4332)
tensor(0.4606)
tensor(0.4387)
tensor(0.4668)
这表示第4个特征的标准差最大,因此对模型的预测结果具有更高的影响力。
基于单变量特征分析的特征重要性分析:
该方法分析每个特征的重要性,通过对每个特征进行单变量分析,例如使用t检验或方差分析。例如,我们可以使用Python的Scikit-learn库来计算每个特征与输出之间的关系:
from sklearn.datasets import make_regression
from sklearn.linear_model import LinearRegression
from sklearn.feature_selection import f_regression
X, y = make_regression(n_samples=100, n_features=5, n_informative=2, random_state=42)
model = LinearRegression()
model.fit(X, y)
f_values, p_values = f_regression(X, y)
for i in range(len(X[0])):
print('Feature %d: f-value=%.2f, p-value=%.2f' % (i+1, f_values[i], p_values[i]))
这将输出每个特征的f值和p值,如下所示:
Feature 1: f-value=56.47, p-value=0.00
Feature 2: f-value=114.10, p-value=0.00
Feature 3: f-value=0.80, p-value=0.38
Feature 4: f-value=0.01, p-value=0.94
Feature 5: f-value=1.54, p-value=0.22
这表示第1个和第2个特征与输出之间的关系最强,因此对模型的预测结果具有更高的影响力。
总的来说,特征重要性分析是机器学习中非常重要的任务,可以帮助我们理解模型如何作出决策,并为特征工程提供指导。不同的方法适用于不同类型的模型和数据,需要根据具体情况进行选择。
6. 基于shap值的方法
SHAP(SHapley Additive exPlanations)是一种用于解释模型预测结果的方法,通过计算每个特征对预测结果的影响,来解释模型的预测过程。基于SHAP值的方法可以用来判断特征的重要性,具体步骤如下:
计算每个样本的SHAP值
使用SHAP方法,对于每个样本,计算每个特征对该样本预测结果的影响,得到该样本的SHAP值。这个过程可以使用现成的SHAP库实现,如XGBoost的shap库、LightGBM的lightgbm.plotting库等。
统计特征的平均SHAP值
对于每个特征,将所有样本的SHAP值加和并除以样本数量,得到该特征的平均SHAP值。平均SHAP值越大,表示该特征对模型预测结果的影响越大,即该特征越重要。
可视化特征的SHAP值
可以使用SHAP的可视化工具,如summary plot、dependence plot等,来直观地展示每个特征的平均SHAP值,以及特征对预测结果的影响程度。通过这些可视化工具,可以更加深入地了解每个特征的重要性。
需要注意的是,SHAP值方法适用于任何机器学习模型,包括线性模型、树模型、神经网络等。并且,与其他特征重要性评估方法相比,SHAP值方法可以提供更为准确和直观的特征重要性评估结果。
以下是使用XGBoost库和SHAP库进行特征重要性评估的示例代码:
import xgboost
import shap
# 加载数据集
X, y = shap.datasets.boston()
# 训练XGBoost模型
model = xgboost.train({"learning_rate": 0.01}, xgboost.DMatrix(X, label=y), 100)
# 计算每个样本的SHAP值
explainer = shap.Explainer(model)
shap_values = explainer(X)
# 统计特征的平均SHAP值
mean_shap_values = shap_values.mean(axis=0)
# 可视化特征的SHAP值
shap.summary_plot(mean_shap_values, X)
在这个示例中,我们使用了XGBoost库训练了一个回归模型,并使用SHAP库计算了每个特征的SHAP值。最后,我们使用了SHAP的可视化工具summary plot来展示了每个特征的平均SHAP值,并可视化了特征对预测结果的影响程度。
除了使用summary_plot可视化特征的SHAP值之外,SHAP库还提供了许多其他的可视化工具,如dependence plot、force plot等,可以更深入地了解每个特征对模型预测结果的影响。
下面是使用dependence plot展示某个特征的SHAP值对预测结果的影响的示例代码:
# 可视化某个特征的SHAP值对预测结果的影响
shap.dependence_plot("RM", shap_values, X)
这里我们选择了数据集中的一个特征"RM",通过dependence plot展示了它的SHAP值对预测结果的影响。可以看到,该特征的SHAP值与预测结果呈现出一定的线性关系,SHAP值越大,预测结果也越大。文章来源:https://www.toymoban.com/news/detail-450930.html
除此之外,SHAP库还提供了许多其他的可视化工具,如interaction plot、waterfall plot等,可以更加深入地探究每个特征对模型预测结果的影响程度。文章来源地址https://www.toymoban.com/news/detail-450930.html
到了这里,关于机器学习特征重要性分析的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!