实验三: Spark + HBase 数据处理和存储实验
1. 实验目的
- 了解Spark中的基本概念和主要思想,熟悉Spark与MapReduce的区别;
- 掌握基本的Spark编程,实现基础RDD编程;
- 了解HBase的基本特性及其适用场景;
- 熟悉HBase Shell常用命令;
- 学习使用HBase的Java API,编程实现HBase常用功能;
2. 实验环境
实验平台:基于实验一搭建的虚拟机Hadoop大数据实验平台上的Spark集群,HBase;
编程语言:JAVA(推荐使用)、Python等;
3. 实验内容
3.1 Spark
3.1.0 Spark简介
首先启动HDFS、YARN、Spark
// 启动HDFS(cluster1上)
$ start-dfs.sh
// 启动YARN(cluster1上)
$ start-yarn.sh
// 运行Spark(cluster1上) 运行spark前需启动hadoop的HDFS和YARN
$ start-master.sh
$ start-slaves.sh

3.1.1 功能实现
3.1.1.1 创建RDD
创建RDD,并熟悉RDD中的转换操作,行动操作,并给出相应实例;
// 在cluster2 上启动mysql
# /etc/init.d/mysql.server start -user=mysql
// 进入Sprk shell 进行交互式编程
$ spark-shell --master local[4]
--master选项指定分布式集群的主URL, local[4]表示在本地运行4个线程。(由于我们的数据比较小,因此先在本地进行测试)

- 转化操作
对于RDD而言,每一次转换操作都会产生不同的RDD,供给下一个操作使用。RDD的转换过程是惰性求值的,也就是说,整个转换过程只是记录了转换的轨迹,并不会发生真正的计算,只有遇到行动操作时,才会触发“从头到尾”的真正的计算。
最常用的转化操作是map() 和filter(),转化操作map() 接收一个函数,把这个函数用于RDD 中的每个元素,将函数的返回结果作为结果RDD 中对应元素的值。而转化操作filter() 则接收一个函数,并将RDD 中满足该函数的元素放入新的RDD 中返回。
常用的转换操作如下表:
| 操作 | 含义 |
|---|---|
| filter(func) | 筛选出满足函数func的元素,并返回一个新的数据集 |
| map(func) | 将每个元素传递到函数func中,并将结果返回为一个新的数据集 |
| flatMap(func) | 与map()相似,但每个输入元素都可以映射到0或多个输出结果 |
| groupByKey() | 应用于(K,V)键值对的数据集时,返回一个新的(K, Iterable)形式的数据集 |
| reduceByKey(func) | 应用于(K,V)键值对的数据集时,返回一个新的(K,V)形式的数据集,其中每个值是将每个key传递到func中进行聚合后的结果 |
下面将采用两个例子实现转换操作,具体操作如下图所示:

// 用map() 对RDD 中的所有数求平方
scala> val input = sc.parallelize(List(1, 2, 3, 4))
scala> val result = input.map(x => x * x)
scala> println(result.collect().mkString(","))
- 上述代码解释
- 可以调用SparkContext的
parallelize方法,从一个已经存在的集合(数组)上创建RDD。其中List数组中的每个元素都是一个RDD。 - map(func)操作将每个元素传递到函数func中,并将结果返回为一个新的数据集。
- input.map(x=>x*x)的含义是,依次取出input这个RDD中的每个元素,对于当前取到的元素,把它赋值给λ表达式中的变量x,然后,执行λ表达式的函数体部分“x*x”,也就是把变量x的值求平方后,作为函数的返回值,并作为一个元素放入到新的 RDD(即 result)中。最终,新生成的RDD(即result),包含了4个Int类型的元素,即1、4、9、16。
- 可以调用SparkContext的
最终打印元素1,4,9,16, 说明平方求解成功。

// 用filter过滤其中为1的值
scala> val result2 = input.filter(x => x!=1)
scala> println(result2.collect().mkString(","))
- 上述代码解释
- filter(func)操作会筛选出满足函数func的元素,并返回一个新的数据集
- lines.filter()操作,filter()的输入参数x=>x!=1是一个匿名函数,或者被称为“λ表达式”。该操作的含义是,依次取出input这个RDD中的每个元素,对于当前取到的元素,把它赋值给λ表达式中的x变量,如果x不为0,就加入到新的RDD中。
最终打印元素2,3,4 ,成功过滤掉1
-
行动操作
行动操作是真正触发计算的地方。Spark程序只有执行到行动操作时,才会执行真正的计算,从文件中加载数据,完成一次又一次转换操作,最终,完成行动操作得到结果。
常用RDD行动操作API
操作 含义 count() 返回数据集中的元素个数 collect() 以数组的形式返回数据集中的所有元素 first() 返回数据集中的第一个元素 take(n) 以数组的形式返回数据集中的前n个元素 reduce(func) 通过函数func(输入两个参数并返回一个值)聚合数据集中的元素 foreach(func) 将数据集中的每个元素传递到函数func中运行 -
reduce()reduce()接收一个函数作为参数,这个函数要操作两个RDD 的元素类型的数据并返回一个同样类型的新元素。一个简单的例子就是函数+,可以用它来对我们的RDD 进行累加。使用reduce(),可以很方便地计算出RDD中所有元素的总和、元素的个数,以及其他类型的聚合操作。scala> var rdd = sc.parallelize(List(1,2,3,4,5,6,7)) scala> var sum = rdd.reduce((x, y) => x + y)在执行rdd.reduce((x,y)=>x+y)时,系统会把rdd的第1个元素1传入给参数x,把rdd的第2个元素2传入给参数y,执行x+y计算得到求和结果3;然后,把这个求和的结果3传入给参数x,把rdd的第3个元素3传入给参数y,执行a+b计算得到求和结果6,以此类推,最终结果应该是数组中所有数字的和。
输出结果为28,成功的计算出了rdd中所有元素的求和。

-
aggregate() 函数则把我们从返回值类型必须与所操作的RDD 类型相同的限制中解放出来。与fold() 类似,使用aggregate() 时,需要提供我们期待返回的类型的初始值。然后通过一个函数把RDD 中的元素合并起来放入累加器。考虑到每个节点是在本地进行累加的,最终,还需要提供第二个函数来将累加器两两合并。
scala> var rdd = sc.parallelize(List(1,2,3,4,5,6,7)) scala> var result = rdd.aggregate((0,0))((acc,value) => (acc._1 + value,acc._2 + 1),(acc1,acc2) => (acc1._1 + acc2._1 , acc1._2 + acc2._2)) scala> var avg = result._1/result._2.toDouble
-

第二步骤输出的是一个二元组,其中第一个元素是列表中所有数的累加和,第二个元素是列表中元素的个数。
第三步骤输出的是列表的平均值。
3.1.1.2 持久化操作
了解如何将RDD中的计算过程进行持久化操作,并给出具体代码;
-
持久化操作
Spark RDD 是惰性求值的,而有时我们希望能多次使用同一个RDD。如果简单地对RDD 调用行动操作,Spark 每次都会重算RDD 以及它的所有依赖。这在迭代算法中消耗格外大,因为迭代算法常常会多次使用同一组数据。为了避免多次计算同一个RDD,可以让Spark 对数据进行持久化。当我们让Spark 持久化存储一个RDD 时,计算出RDD 的节点会分别保存它们所求出的分区数据。如果一个有持久化数据的节点发生故障,Spark 会在需要用到缓存的数据时重算丢失的数据分区。如果希望节点故障的情况不会拖累我们的执行速度,也可以把数据备份到多个节点上。出于不同的目的,我们可以为RDD 选择不同的持久化级别,具体的级别如下表所示。

测试一: 练习使用persist函数
import org.apache.spark.storage.StorageLevel
var input = sc.parallelize(List(1, 2, 3, 4, 5, 6, 7))
val result = input.map(x => x * x)
result.persist(StorageLevel.DISK_ONLY) // 使用persist函数将结果存放到磁盘中。
println(result.count())
println(result.collect().mkString(","))
- 使用persist()方法对一个RDD标记为持久化,之所以说“标记为持久化”,是因为出现persist()语句的地方,并不会马上计算生成RDD并把它持久化,而是要等到遇到第一个行动操作触发真正计算以后,才会把计算结果进行持久化,持久化后的RDD将会被保留在计算节点的内存中,被后面的行动操作重复使用。
- persist()的圆括号中包含的是持久化级别参数,可以有如下不同的级别:
- persist(MEMORY_ONLY):表示将RDD作为反序列化的对象存储于JVM中,如果内存不足,就要按照LRU原则替换缓存中的内容
- persist(MEMORY_AND_DISK):表示将RDD作为反序列化的对象存储在JVM中,如果内存不足,超出的分区将会被存放在磁盘上。
结果如下图所示:
- 测试2 : 对比持久化操作效果
# 创建test文本
touch test.txt
# 写入相应内容
echo "i am a test file,wonderful hello hello wonderful hello hello" > test.txt
# 上传到hdfs
./hdfs dfs -put test.txt user/hadoop/lab3
./hdfs dfs -put /home/hadoop/data/data8.txt /lab3
# 查看上传后的文件内容
./hdfs dfs -ls user/hadoop/lab3

// 非持久化操作
val testrdd =sc.textFile("lab3/test.txt")
testrdd.count();
val t1 =System.currentTimeMillis();
println("noCache()=testrdd.count()=" + testrdd.count());
val t2 = System.currentTimeMillis();
val t2_t1 =t2 - t1;
println("nocache()=" + t2_t1);

// 持久化操作
val testrdd =sc.textFile("lab3/test.txt"); .persist(StorageLevel.MEMORY_ONLY());
testrdd.count();
val t1 =System.currentTimeMillis();
println("noCache()=testrdd.count()=" + testrdd.count());
val t2 = System.currentTimeMillis();
val t2_t1 = t2 - t1;
println("cache()=" + t2_t1);

可以看到没有使用持久化操作的运行时间是573ms, 而使用了持久化操作的运行时间为292。因此持久化操作过程给性能带来了比较大的提升。
3.1.1.3 数据读取与保存
了解Spark的数据读取与保存操作,尝试完成csv文件的读取和保存;
# 首先上传实验数据五到hdfs文件系统中(改为英文名'test5.csv')
./hdfs dfs -put /home/hadoop/data/test5.csv /user/hadoop/lab3
# 查看上传后的文件内容
./hdfs dfs -ls /user/hadoop/lab3

import java.io.StringReader;
import au.com.bytecode.opencsv.CSVReader;
val input=sc.textFile("/user/hadoop/lab3/test5.csv");
input.foreach(println);
val result =input.map{line =>val reader =new CSVReader(new StringReader(line));reader.readNext();}
- 上述源码的解释
- Spark采用textFile()方法来从文件系统中加载数据创建RDD,该方法把文件的URI作为参数,这个URI可以是本地文件系统的地址、分布式文件系统HDFS的地址。
- 首先使用textFile()方法从文件中加载数据,然后,使用map()函数转换得到相应的键值对RDD。
- 执行
sc.textFile()方法以后,Spark 从本地文件test5.txt 中加载数据到内存,在内存中生成一个RDD对象lines,lines是org.apache.spark.rdd.RDD这个类的一个实例,这个RDD里面包含了若干个元素,每个元素的类型是 String 类型,也就是说,从 test5.txt 文件中读取出来的每一行文本内容,都成为RDD中的一个元素
如下图所示,成功的读取test5.csv的数据

并将结果保存到了result中。

3.1.2 WordCount实验
编程熟悉Spark中的键值对操作,利用Spark的API完成wordcount实验,即统计一段文本中每个单词的出现总数,如 a b c d a c, 结果为(a , 2),(b , 1),(c , 2),(d , 1)。
- 代码详细说明
- 首先使用textFile()方法从文件中加载数据
- flatmap的输入参数line => line.split(" “)是一个λ表达式。lines.map(line => line.split(” “))的含义是,依次取出lines这个RDD中的每个元素,对于当前取到的元素,把它赋值给λ表达式中的line变量,然后,执行λ表达式的函数体部分line.split(” “)。line.split(” ")的功能是,以空格作为分隔符把line拆分成一个个单词,拆分后得到的单词都封装在一个数组对象中,成为新的RDD(即words)的一个元素。
- 从input转换得到一个新的RDD(即wordArray),wordArray中的每个元素都是一个数组对象。flatmap也就是把wordArray中的每个RDD元素都“拍扁”成多个元素,最终,所有这些被拍扁以后得到的元素,构成一个新的RDD,即words。
- map(word => (word,1))函数的作用是,取出RDD中的每个元素,也就是每个单词,赋值给word,然后把word转换成(word,1)的键值对形式。
- reduceByKey(func)应用于(K,V)键值对的数据集时,返回一个新的(K, V)形式的数据集,其中的每个值是将每个key传递到函数func中进行聚合后得到的结果。
- 名称为word的RDD中包含的每个元素都是<String,Int>类型,也就是(K,V)键值对类型。words.reduceByKey((a,b)=>a+b)操作执行以后,所有key相同的键值对,它们的value首先被归并成一个新的键值对,例如(“xxx”,(1,1,1))。然后,使用func函数把(1,1,1)聚合到一起,这里的func函数是一个λ表达式,即(a,b)=>a+b,它的功能是把(1,1,1)这个value-list中的每个元素进行汇总求和,首先,把value-list中的第1个元素(即1)赋值给参数a,把value-list中的第2个元素(也是1)赋值给参数b,执行a+b得到2,然后,继续对value-list中的元素执行下一次计算,把刚才求和得到的2赋值给a,把value-list中的第3个元素(即1)赋值给b,再次执行a+b得到3。最终,就得到聚合后的结果(“xxx”,3)。
- 最后,执行了语句wordcount.foreach(elem=>println(elem)),该语句会依次遍历 rdd 中的每个元素,把当前遍历到的元素赋值给变量 elem,并使用 println(elem)打印出 elem的值。实际上,rdd.foreach(elem=>println(elem))可以被简化成rdd.foreach(println),效果是一样的。
object WordCount { //定义wordcount类,用来统计一段文本中每个单词的出现总数
def main(args: Array[String]) {
val inputFile = "/home/hadoop/data/test6.txt" // 原始数据文件
val conf = new SparkConf().setMaster("local[2]").setAppName("WordCount")
conf.set("spark.testing.memory", "500000000") // 设置配置信息
val sc = new SparkContext(conf)
val textFile = sc.textFile(inputFile) // 读取数据
val wordCount = textFile.flatMap(line => line.split(" ")).map(word => (word, 1)).reduceByKey((a, b) => a + b) // 文本分割并计数,格式为(word,number)
wordCount.foreach(println) // 打印wordCount
wordCount.saveAsTextFile("/home/hadoop/lab3/output") // 将结果保存到output文件夹下
}
}
然后将WordCount.scala代码上传到/home/hadoop/lab3 上,并编译和运行。
cd /home/hadoop/lab3
//编译
$ scalac -cp /usr/local/spark-1.6.3-bin-hadoop2.6/lib/*: WordCount.scala
//运行
$ java -cp /usr/local/spark-1.6.3-bin-hadoop2.6/lib/*: WordCount
终端输出结果如下图所示:
在/home/hadoop/lab3下会生成output文件夹,以及文件夹下的输出文件。
3.1.3 累加器和广播变量
查阅资料,了解Spark中累加器和广播变量的作用,并举例实验累加器和广播变量,尝试体会两者的区别。
在 Spark中,提供了两种类型的共享变量:累加器 (accumulator) 与广播变量 (broadcast variable)
- 累加器:用来对信息进行聚合,主要用于累计计数等场景
- 广播变量:主要用于在节点间高效分发大对象。
对于正常的累计求和,如果在集群模式中使用下面的代码进行计算,会发现执行结果并非预期:
var counter = 0
val data = Array(1, 2, 3, 4, 5)
sc.parallelize(data).foreach(x => counter += x)
println(counter)
counter 最后的结果是 0,导致这个问题的主要原因是闭包。在实际计算时,Spark 会将对 RDD 操作分解为 Task,Task 运行在 Worker Node 上。在执行之前,Spark 会对任务进行闭包,如果闭包内涉及到自由变量,则程序会进行拷贝,并将副本变量放在闭包中,之后闭包被序列化并发送给每个执行者。因此,当在 foreach 函数中引用 counter 时,它将不再是 Driver 节点上的 counter,而是闭包中的副本 counter,默认情况下,副本 counter 更新后的值不会回传到 Driver,所以 counter 的最终值仍然为零。
所以在遇到此类问题时应优先使用累加器。
3.1.3.1 累加器
累加器的原理:
就是将每个副本变量的最终值传回 Driver,由 Driver 聚合后得到最终值,并更新原始变量。
//创建一个accumulator变量
scala> val acc = sc.accumulator(0, "Accumulator")
//add方法可以相加
scala> sc.parallelize(Array(1,2,3,4,5)).foreach(x => acc.add(x))
scala> acc.value
求和结果为 1+2+3+4+5=15

//+=也可以相加
scala> sc.parallelize(Array(1,2,3,4,5)).foreach(x => acc += x)
scala> acc.value
求和的结果为15+15=30

3.1.3.2 广播变量
广播变量的做法很简单:就是不把副本变量分发到每个 Task 中,而是将其分发到每个 Executor,Executor 中的所有 Task 共享一个副本变量。Spark提供的Broadcast Variable,是只读的。并且在每个节点上只会有一份副本,而不会为每个task都拷贝一份副本。因此其最大作用,就是减少变量到各个节点的网络传输消耗,以及在各个节点上的内存消耗。此外,spark自己内部也使用了高效的广播算法来减少网络消耗。
调用SparkContext的broadcast()方法,来针对某个变量创建广播变量。然后在算子的函数内,使用到广播变量时,每个节点只会拷贝一份副本了。每个节点可以使用广播变量的value()方法获取值。Broadcast是只读的。
使用Broadcast变量的步骤:
- 调用SparkContext.broadcast方法创建一个Broadcast[T]对象。
任何序列化的类型都可以这么实现。 - 通过value属性访问改对象的值(Java之中为value()方法)
- 变量只会被发送到各个节点一次,应作为只读值处理(修改这个值不会影响到别的节点)
// 把一个数组定义为一个广播变量
val broadcastVar = sc.broadcast(Array(1, 2, 3, 4, 5))
// 之后用到该数组时应优先使用广播变量,而不是原值
sc.parallelize(broadcastVar.value).map(_ * 10).collect()
输出的结果是对应Array的元素乘以10,结果为(10,20,30,40,50)
3.2 HBase
3.2.1 创建表格
通过Hbase的shell命令创建HBase列式存储数据表格,其中每一行的数据格式如下

// 在cluster1 上启动hdfs
$ start-dfs.sh
// 在cluster1 上启动habase
$ start-yarn.sh
// 在cluster1 上启动habase
$ start-hbase.sh
$ hbase shell
// 创建表student, 列簇名分别为information,score,stat_score
> create 'student','information','score','stat_score'

// describe查看student表的基本信息
describe 'student'

// 使用put函数进行数据的插入
// student: 表名
// 1001 学号
// information:name 列簇名:列名
// Tom 值
put 'student','1001','information:name','Tom'
put 'student','1001','information:sex','male'
put 'student','1001','information:age','20'
put 'student','1001','score:123001','99'
put 'student','1001','score:123002','98'
put 'student','1001','score:123003','97'
put 'student','1001','stat_score:sum','294'
put 'student','1001','stat_score:avg','98'

// 查看student表
scan 'student'

3.2.2 插入数据
请使用HBASE提供的API编程,实现向1)创建的HBase表中插入类似于下表中的数据(完整数据在附录中),列簇3部分先用”NULL”补充。

主要思路:
- 首先构造ReadFile函数用于读取每一行的字符串,并保存到lines数组中。
- 然后allAll函数遍历lines数组,并对每一行进行分割,得到"学号|姓名|性别|年龄"
- 最后调用addRecord函数进行数据的插入
核心代码如下:
// 从文件中逐行读取数据
public static List<String> ReadFile(String filename) {
List<String> lines = null;
try {
lines = Files.readAllLines(Paths.get(filename), StandardCharsets.UTF_8);
} catch (IOException e) {
e.printStackTrace();
}
return lines;
}
// 一次性添加所有的学生信息
public static void addALL(String tableName,String[] columnFamilys) throws Exception {
// 读取data7.txt
// 文件中的数据格式:学号|姓名|性别|年龄
List<String> list7 = ReadFile("/home/hadoop/data7.txt");
//写入student information
for (String line : list7) {
String[] temp = line.split("\\s+");
String Id = temp[0];
String Name = temp[1];
String Sex = temp[2];
String Age = temp[3];
HBaseJavaAPI.addRecord(tableName, Id, columnFamilys[0],"name", Name);
HBaseJavaAPI.addRecord(tableName, Id, columnFamilys[0],"age",Age);
HBaseJavaAPI.addRecord(tableName, Id, columnFamilys[0],"sex",Sex);
//提示
System.out.println("学生学号:" + Id + ",姓名:" + Name + ",性别:" + Sex + ",年龄:" + Age);
}
//读取data8.txt
//文件中的数据格式:学号|课程号|成绩
List<String> list8 = ReadFile("/home/hadoop/data8.txt");
//写入student score
for (String line : list8) {
String[] temp = line.split("\\s+");
String Id = temp[0];
String Cno = temp[1];
String Score = temp[2];
HBaseJavaAPI.addRecord(tableName,Id, columnFamilys[1], Cno,Score);
//提示
System.out.println("学生学号:" + Id +",课程课号:" + Cno + ",成绩:" + Score);
}
}
// 调用
public static void main(String[] args) {
try {
String tableName = "student";
// 第一步:创建数据库表:“student”
String[] columnFamilys = { "information", "score","stat_score" };
HBaseJavaAPI.createTable(tableName, columnFamilys);
// 第二步:向数据表的添加数据
// 添加第一行数据
if (isExist(tableName)) {
//从文件中读取信息,添加全部的数据
addALL(tableName,columnFamilys);
} else {
System.out.println(tableName + "此数据库表不存在!");
}
} catch (Exception e) {
e.printStackTrace();
}
}
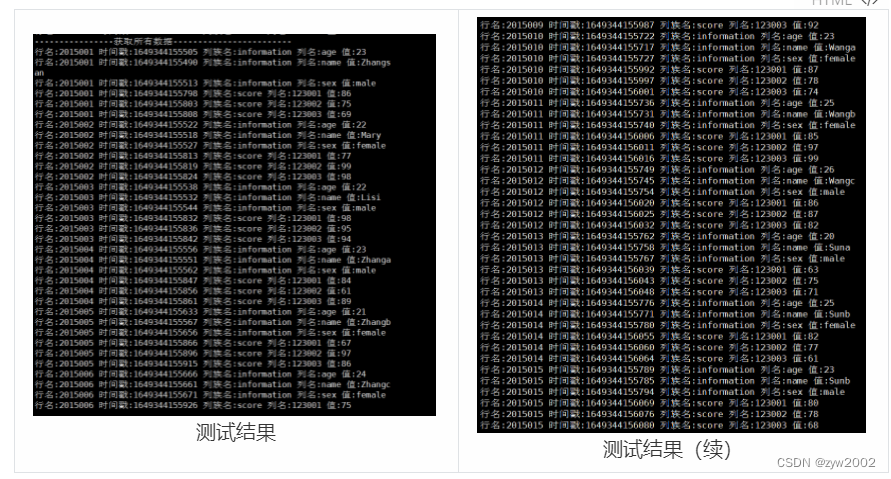

3.2.3 成绩统计
请使用Spark编程实现对每个学生所有课程总成绩与平均成绩的统计聚合,并将聚合结果存储到1)中创建的HBase表。(可以考虑将聚合后的结果先存入HDFS文件,再从HDFS文件载入数据到HBase,也可以使用API将聚合结果直接插入到HBase表。)
实验思路:成绩统计的实验是通过java编程使用Spark API实现的 , 首先采用mapTopair函数构造学号和成绩的键值对。然后再使用reduceByKey函数进行归约,实现相同学号成绩的累加。
主要参考JavaRDDLike (Spark 1.6.3 JavaDoc) (apache.org)
// 官网给的函数原型
<K2,V2> JavaPairRDD<K2,V2> mapToPair(PairFunction<T,K2,V2> f)
总成绩的代码如下:
//进行成绩总和的聚合
//输入数据类型:学号string|课程号string|成绩integer
/*
其中PairFunction中
第一个参数是call 函数中参数的输入的类型,表示从文件中读取的一行为一个RDD
第二个参数和第三个参数分别表示生成的键值对的类型。分别对应<学号,成绩>
call函数是代码的逻辑部分,通过split函数以空格为分节符进行分割,分割结果以数组的形式进行存放。
返回的结果是数组中的第一列(学号)、第三列(成绩)。
其中成绩要从字符串的类型转换成整数类型,方便后续的计算
其中reduceByKey函数要对Function2函数进行重写。
Function2中的第一个参数是返回值的类型,第二个和第三个参数是call方法的输入类型。
call方法就是实现相同key的tuple中value值的累加。
返回值是<学号,总成绩>
*/
JavaPairRDD<String,Integer> SumScore=File8.mapToPair(new PairFunction<String, String, Integer>(){
@Override
public Tuple2<String,Integer> call(String f){
String[] str=f.split(" ");// 分割
return new Tuple2<>(str[0],Integer.parseInt(str[2])); // 输出类型:key=学号|value=成绩
}
}).reduceByKey(new Function2<Integer, Integer, Integer>() { // key值相同的进行规约
@Override
public Integer call(Integer a, Integer b) throws Exception { // 学号相同的成绩求和
return a+b;
}
});
由于每个学生都是只有3门课,因此平均成绩的算法就是总成绩除以3,只需要在上一步的代码基础上再重新添加一个 mapTopair 函数实现映射,其中键值不变(学号),然后平均成绩是之前总成绩的1/3。
平均成绩的代码如下:
//进行平均成绩的聚合
//输入数据类型:学号string|课程号string|成绩integer
/*
最后一个mapTopair 参数解释:
其中第一个参数Tuple2<String,Integer>是返回值的类型<学号,平均成绩>
第二个参数String是学号
第三个参数Integer是总成绩
最后一个call函数的解释:
其中stringIntegerTuple2是上一步规约后得到的键值对
返回值类型也是一个Tuple2的键值对,stringIntegerTuple2._1代表的是学号,stringIntegerTuple2._2/3代表的是平均成绩
*/
JavaPairRDD<String,Integer> AvgScore=File8.mapToPair(new PairFunction<String, String, Integer>(){
@Override
public Tuple2<String,Integer> call(String f){
String[] str=f.split(" "); // 分割
return new Tuple2<>(str[0],Integer.parseInt(str[2])); // 输出类型:key=学号|value=成绩
}
}).reduceByKey(new Function2<Integer, Integer, Integer>() {
@Override
public Integer call(Integer a, Integer b) throws Exception {
return a+b; // 学号相同的成绩求和
}
}).mapToPair(new PairFunction<Tuple2<String, Integer>, String, Integer>() {
@Override
public Tuple2<String, Integer> call(Tuple2<String, Integer> stringIntegerTuple2) throws Exception {
return new Tuple2<>(stringIntegerTuple2._1,stringIntegerTuple2._2/3); // key=学号|value=平均成绩
}
});
# 编译
$ javac -cp
/usr/local/hbase-1.2.6/lib/*:/usr/local/spark-1.6.3-bin-hadoop2.6/lib/*: Hbase_java.java
# 运行
$ java -cp /usr/local/hbase-1.2.6/lib/*:/usr/local/spark-1.6.3-bin-hadoop2.6/lib/*: Hbase_java

3.2.4 API编程
请使用Hbase提供的API编程,完成以下指定功能:
3.2.4.1 功能一
先添加一个学生用户,再使用addRecord(String tableName, String row, String[] fields, String[] values);向表tableName、行row(用S_Name表示)和字符串数组files指定的单元格中添加对应的数据values。其中fields中每个元素如果对应的列族下还有相应的列限定符的话,用“columnFamily:column”表示。例如,同时向“Math(123001)”、“Computer Science(123002)”、“English(123003)”三列添加成绩时,字符串数组fields为{“score: 123001”,”score;123002”,”score: 123003”},数组values存储这三门课的成绩。
核心代码如下:
/*
主要采用了`put.add()` 函数实现单条数据的插入。
其中第一个参数表示列簇名
第二个参数表示列名
第三个参数表示值
*/
// 添加一条数据
public static void addRecord(String tableName, String row,
String columnFamily, String column, String value) throws Exception {
HTable table = new HTable(conf, tableName);
Put put = new Put(Bytes.toBytes(row));// 指定行
// 参数分别:列族、列、值
put.add(Bytes.toBytes(columnFamily), Bytes.toBytes(column),
Bytes.toBytes(value));
table.put(put);
}
3.2.4.2 功能二
scanColumn(String tableName, String column);浏览表tableName某一列的数据,如果某一行记录中该列数据不存在,则返回null。要求当参数column为某一列族名称时,如果底下有若干个列限定符,则要列出每个列限定符代表的列的数据;当参数column为某一列具体名称(例如“Score:Math”)时,只需要列出该列的数据。
- 主要思路
- 首先用split函数对数据进行分割,并把分隔结果保存在字符串数组中。
- 通过判断数组的长度来执行不同的操作,当长度为2时,说明参数是某一列族名称时, 只返回该列族的所有值。否则返回该列簇下的所有数据
public static void scanColumn(String tableName,String column) throws Exception{
Table table = connection.getTable(TableName.valueOf(tableName));
String[] str= column.split(":"); //将数据分割
if(str.length == 2) { // 当column为某一列族名称时, 只返回该列族的所有值
ResultScanner scan = table.getScanner(str[0].getBytes(), str[1].getBytes());
for (Result result : scan) { //遍历该列族所有数据
System.out.println(new String(result.getValue(str[0].getBytes(), str[1].getBytes())));
}
scan.close(); // 关闭扫描器
}
else{ // 否则返回列簇下的所有数据
ResultScanner scan = table.getScanner(str[0].getBytes());
for(Result result :scan){ // 首先遍历列簇下的不同行
Map<byte[],byte[]> myMap = result.getFamilyMap(Bytes.toBytes(column));
ArrayList<String> cols = new ArrayList<String>();
for(Map.Entry<byte[],byte[]> entry:myMap.entrySet()){
cols.add(Bytes.toString(entry.getKey()));
}
for(String st :cols){ // 然后遍历该列簇下的不同列族,并打印输出结果
System.out.print(st+ " : "+ new String(result.getValue(column.getBytes(),st.getBytes()))+" ~~~ ");
}
System.out.println();
}
scan.close();
}
}
3.2.4.3 功能三
deleteRow(String tableName, String row);删除表tableName中row指定的行的记录。
主要思路:
采用Delete函数完成单条数据的删除,其中参数row是学号值
// 删除一条(行)数据
public static void deleteRow(String tableName, String row) throws Exception {
HTable table = new HTable(conf, tableName);
Delete del = new Delete(Bytes.toBytes(row));
table.delete(del);
}
3.2.5 测试结果
运行如下命令,对代码进行编译测试
cd ~/lab3
// 编译运行
javac -cp /usr/local/hbase-1.2.6/lib/*: HBaseJavaAPI.java
java -cp /usr/local/hbase-1.2.6/lib/*: HBaseJavaAPI
-
创建表
成功创建student表
-
获取表中的数据
可以根据学号获取单个学生的数据,也可以获取所有学生的数据。

获取列簇和列族的值。

-
删除表中的数据
如下图所示,可以根据学号删除一条记录。最后也可以删除整个数据表。

4. 踩坑记录
- Debug1
【问题描述】 启动spark-shell的时候会报如下错误not found: value sqlContext

【问题背景】在网上查了很多资料,翻遍了stackoverflow,能尝试的方法都试过了,但都没有奏效。因此我又仔细的查看了报错的信息,发现它原来是连接不到cluster2上安装的数据库。

【解决方案】在启动spark前,现在cluster2上开启mysql服务,然后终于成功解决了这个报错!

- Debug2
【问题描述】报错illegal character '\u00a0'
【问题背景】去网上查了下\u00a0 的含义,发现是空格的意思,因此推测应该是有不合法的空格。
【解决方案】删去等号后的第一个空格,成功解决。

- Debug3
【问题描述】在编译运行WordCount程序时,报错Permission denied。

【问题背景】因为我用的是xftp传输文件,然后将本地数据文件上传到clster1后,默认所有者是root,因此导致权限出错。
【解决方案】运行如下命令,修改所有者为hadoop用户,然后再次编译成功。
su root
chown -R hadoop:hadoop /home/hadoop/
- Debug4
【问题描述】在编译HBaseJavaAPI时报错如下:
【问题背景】原先在编写代码,得到行号采用的方式是rowKV.scanColumn() 会报错
【解决方案】在网上查了一些资料,采用了另一种方式来获取行号,修改代码如下:
import org.apache.hadoop.hbase.Cell;
import org.apache.hadoop.hbase.CellUtil;
System.out.print("行名:" + new String(CellUtil.cloneRow(rowKV)) + " ");
然后重新编译运行,成功解决该问题。
- Debug5
【问题描述】在用javac编译代码时报错如下no source files

【解决方案】在小组同学的热心帮助下,我发现是我在HBaseJavaAPI前少写了一个空格。长记性,下次不会这么粗心了。
javac -cp /usr/local/hbase-1.2.6/lib/*:/usr/local/spark-1.6.3-bin-hadoop2.6/lib/*: HBaseJavaAPI.java
java -cp /usr/local/hbase-1.2.6/lib/*:/usr/local/spark-1.6.3-bin-hadoop2.6/lib/*: HBaseJavaAPI
- Debug6
【问题描述】由于一开始一开始在本地调试maven项目时,导入jar包的时间非常慢。
【问题背景】在网上查资料应该是网速的问题,而且我检查过我已经配置过了阿里云镜像,按理说不会这么慢。
【解决方案】后来,我检查一下发现原来是该项目的marven没有配置,导入到本地配置的setting.xml文件后,1分钟就下载完了所需的所有依赖。

- Debug7
【问题描述】在本地编译成功的代码放到linux上运行就会报错。
【问题背景】在同组同学的提示下,我发现是因为Java版本不一致造成的。本地maven默认配置是java1.8 但是我们的实验环境是java1.7。
【解决方案】修改apache-maven-3.8.4\conf目录下的setting.xml文件中的JDK的版本修改为1.7, 修改完成后,由于版本不一致,还需要对代码进行进一步的修改。
<profiles>
<profile>
<id>JDK-1.7</id>
<activation>
<activeByDefault>true</activeByDefault>
<jdk>1.7</jdk>
</activation>
<properties>
<maven.compiler.source>1.7</maven.compiler.source>
<maven.compiler.target>1.7</maven.compiler.target>
<maven.compiler.compilerVersion>1.7</maven.compiler.compilerVersion>
</properties>
</profile>
- Debug8
【问题描述】由于java的版本不同因此在用spark api编程时,写法法不一样。
【解决方案】在使用mapToPair函数时,java7和java8 有不同的写法。以下举一个简单的例子:把数字类型转换成<奇数/偶数,数字> 的类型。

//java8
JavaPairRDD <String,Integer> pairRDD=intRDD.mapToPair(i->(i%2==0)? new Tuple2<String,Integer>("even",i):new Tuple2<String,Integer>("odd",i));
如果用java8的话,一行代码使用匿名函数就可以搞定,但是在java7中要复杂的多。需要重写PairFunction 函数, 代码的逻辑放在call 函数中实现。
// Java7
JavaPairRDD <String,Integer> pairRDD=intRDD.mapToPair(new PairFunction<Integer,String, Integer>(){
@Override
public Tuple2<String,Integer> call (Integer i) throws Exception{
return (i%2 ==0)? new Tuple2<String,Integer>("even",i):new Tuple2<String,Integer>("odd",i);
}
});
除此之外,还有reduceBykey函数也有变化,不能使用匿名函数,而是要重写Function2中的call方法实现
-
Debug9
【问题描述】当采用集群模式执行时,rdd.foreach(println)语句无法打印元素
【问题背景】当采用 Local 模式在单机上执行时,rdd.foreach(println)语句会打印出一个RDD中的所有元素。但是,当采用集群模式执行时,在Worker节点上执行打印语句是输出到Worker节点的stdout中,而不是输出到任务控制节点Driver中,因此,任务控制节点Driver中的stdout是不会显示打印语句的这些输出内容的
【解决方案】为了能够把所有 Worker 节点上的打印输出信息也显示到Driver中,就需要使用collect()方法。例如,rdd.collect().foreach(println)。
5. 心得体会
这次实验比上次实验难度要大一点,前前后后花了很多的时间去做。这次实验感觉收获最大的就是自己在编程的时候,一开始在csdn上找资料,但是讲的都不是很全面。最后逼着自己读了官方的英文文档,以及阅读了英文版《Apache Spark 2.x for java Developers》的部分章节。虽然一开始读起来挺费劲的,但是读完之后确实对于整个原理和代码的理解会清晰很多,觉得也不是特别的难。除此之外就是,在一开始走了很多弯路,比如说尝试用sbt打包,但是后来发现虚拟机内存太小无法安装。后来受到小组同学的启发,觉得可以先在本地sbt打包再传上去,接下来还会再尝试下这种方法。最后还是十分感谢小组同学在本次实验过程中对我的帮助!
6. 附录
6.1 实验数据
实验可以使用“附件2-实验数据”文件夹中的附录实验数据,也可使用自己生成的数据。具体数据如下:
附录实验数据五:SPARK编程一(3.1.1)使用的CSV数据文件;
附录实验数据六:SPARK编程二(3.1.2)使用的数据文本;
附录实验数据七:HBase编程(3.2.2)使用的学生表数据;文章来源:https://www.toymoban.com/news/detail-451016.html
附录实验数据八:HBase编程(3.2.2)及SPARK编程三(3.2.3)使用的选课表数据;文章来源地址https://www.toymoban.com/news/detail-451016.html
6.2 实验源码
6.2.1 WordCount.scala
import org.apache.spark.SparkContext
import org.apache.spark.SparkContext._
import org.apache.spark.SparkConf
import scala.collection.Map
object WordCount {
def main(args: Array[String]) {
val inputFile = "/home/hadoop/data/test6.txt" // 原始数据文件
val conf = new SparkConf().setMaster("local[2]").setAppName("WordCount")
conf.set("spark.testing.memory", "500000000") // 设置配置信息
val sc = new SparkContext(conf)
val textFile = sc.textFile(inputFile) // 读取数据
val wordCount = textFile.flatMap(line => line.split(" ")).map(word => (word, 1)).reduceByKey((a, b) => a + b) // 文本分割并计数,格式为(word,number)
wordCount.foreach(println) // 打印wordCount
wordCount.saveAsTextFile("/home/hadoop/lab3/output") // 将结果保存到output文件夹下
}
}
6.2.2 HBaseJavaAPI
/*
* 创建一个students表,并进行相关操作
*/
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
import java.nio.charset.StandardCharsets;
import java.nio.file.Files;
import java.nio.file.Paths;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.HColumnDescriptor;
import org.apache.hadoop.hbase.HTableDescriptor;
import org.apache.hadoop.hbase.KeyValue;
import org.apache.hadoop.hbase.client.Delete;
import org.apache.hadoop.hbase.client.Get;
import org.apache.hadoop.hbase.client.HBaseAdmin;
import org.apache.hadoop.hbase.client.HTable;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.client.Result;
import org.apache.hadoop.hbase.client.ResultScanner;
import org.apache.hadoop.hbase.client.Scan;
import org.apache.hadoop.hbase.util.Bytes;
import org.apache.hadoop.hbase.Cell;
import org.apache.hadoop.hbase.CellUtil;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.function.Function2;
import org.apache.spark.api.java.function.PairFunction;
import org.apache.spark.storage.StorageLevel;
import scala.Tuple2;
import org.apache.commons.math3.util.Pair;
public class HBaseJavaAPI {
// 声明静态配置
private static Configuration conf = null;
static {
conf = HBaseConfiguration.create();
conf.set("hbase.zookeeper.quorum", "192.168.56.121");
conf.set("hbase.zookeeper.property.clientPort", "2181");
}
//判断表是否存在
private static boolean isExist(String tableName) throws IOException {
HBaseAdmin hAdmin = new HBaseAdmin(conf);
return hAdmin.tableExists(tableName);
}
// 创建数据库表
public static void createTable(String tableName, String[] columnFamilys)
throws Exception {
// 新建一个数据库管理员
HBaseAdmin hAdmin = new HBaseAdmin(conf);
if (hAdmin.tableExists(tableName)) {
System.out.println("表 "+tableName+" 已存在!");
//System.exit(0);
} else {
// 新建一个students表的描述
HTableDescriptor tableDesc = new HTableDescriptor(tableName);
// 在描述里添加列族
for (String columnFamily : columnFamilys) {
tableDesc.addFamily(new HColumnDescriptor(columnFamily));
}
// 根据配置好的描述建表
hAdmin.createTable(tableDesc);
System.out.println("创建表 "+tableName+" 成功!");
}
}
// 删除数据库表
public static void deleteTable(String tableName) throws Exception {
// 新建一个数据库管理员
HBaseAdmin hAdmin = new HBaseAdmin(conf);
if (hAdmin.tableExists(tableName)) {
// 关闭一个表
hAdmin.disableTable(tableName);
hAdmin.deleteTable(tableName);
System.out.println("删除表 "+tableName+" 成功!");
} else {
System.out.println("删除的表 "+tableName+" 不存在!");
System.exit(0);
}
}
// 添加一条数据
public static void addRecord(String tableName, String row,
String columnFamily, String column, String value) throws Exception {
HTable table = new HTable(conf, tableName);
Put put = new Put(Bytes.toBytes(row));// 指定行
// 参数分别:列族、列、值
put.add(Bytes.toBytes(columnFamily), Bytes.toBytes(column),
Bytes.toBytes(value));
table.put(put);
}
// 从文件中逐行读取数据
public static List<String> ReadFile(String filename) {
List<String> lines = null;
try {
lines = Files.readAllLines(Paths.get(filename), StandardCharsets.UTF_8);
} catch (IOException e) {
e.printStackTrace();
}
return lines;
}
// 一次性添加所有的学生信息
public static void addALL(String tableName,String[] columnFamilys) throws Exception {
// 读取data7.txt
// 文件中的数据格式:学号|姓名|性别|年龄
List<String> list7 = ReadFile("/home/hadoop/data/data7.txt");
//写入student information
for (String line : list7) {
String[] temp = line.split("\\s+");
String Id = temp[0];
String Name = temp[1];
String Sex = temp[2];
String Age = temp[3];
HBaseJavaAPI.addRecord(tableName, Id, columnFamilys[0],"name", Name);
HBaseJavaAPI.addRecord(tableName, Id, columnFamilys[0],"age",Age);
HBaseJavaAPI.addRecord(tableName, Id, columnFamilys[0],"sex",Sex);
//提示
System.out.println("学生学号:" + Id + ",姓名:" + Name + ",性别:" + Sex + ",年龄:" + Age);
}
//读取data8.txt
//文件中的数据格式:学号|课程号|成绩
List<String> list8 = ReadFile("/home/hadoop/data/data8.txt");
//写入student score
for (String line : list8) {
String[] temp = line.split("\\s+");
String Id = temp[0];
String Cno = temp[1];
String Score = temp[2];
HBaseJavaAPI.addRecord(tableName,Id, columnFamilys[1], Cno,Score);
//提示
System.out.println("学生学号:" + Id +",课程课号:" + Cno + ",成绩:" + Score);
}
}
// 删除一条(行)数据
public static void deleteRow(String tableName, String row) throws Exception {
HTable table = new HTable(conf, tableName);
Delete del = new Delete(Bytes.toBytes(row));
table.delete(del);
}
// 删除多条数据
public static void delMultiRows(String tableName, String[] rows)
throws Exception {
HTable table = new HTable(conf, tableName);
List<Delete> delList = new ArrayList<Delete>();
for (String row : rows) {
Delete del = new Delete(Bytes.toBytes(row));
delList.add(del);
}
table.delete(delList);
}
// 获取一行的数据
public static void scanColumn(String tableName, String row) throws Exception {
HTable table = new HTable(conf, tableName);
Get get = new Get(Bytes.toBytes(row));
Result result = table.get(get);
// 输出结果,raw方法返回所有keyvalue数组
for (KeyValue rowKV : result.raw()) {
System.out.print("行名:" + new String(CellUtil.cloneRow(rowKV)) + " ");
System.out.print("时间戳:" + rowKV.getTimestamp() + " ");
System.out.print("列族名:" + new String(rowKV.getFamily()) + " ");
System.out.print("列名:" + new String(rowKV.getQualifier()) + " ");
System.out.println("值:" + new String(rowKV.getValue()));
}
}
// 获取一列的数据
public static void scanColumn(String tableName,String column) throws Exception{
Table table = connection.getTable(TableName.valueOf(tableName));
String[] str= column.split(":"); //将数据分割
if(str.length == 2) { // 当column为某一列族名称时, 只返回该列族的所有值
ResultScanner scan = table.getScanner(str[0].getBytes(), str[1].getBytes());
for (Result result : scan) {
System.out.println(new String(result.getValue(str[0].getBytes(), str[1].getBytes())));
}
scan.close();
}
else{ // 否则返回列族下的所有数据
ResultScanner scan = table.getScanner(str[0].getBytes());
for(Result result :scan){
Map<byte[],byte[]> myMap = result.getFamilyMap(Bytes.toBytes(column));
ArrayList<String> cols = new ArrayList<String>();
for(Map.Entry<byte[],byte[]> entry:myMap.entrySet()){
cols.add(Bytes.toString(entry.getKey()));
}
for(String st :cols){
System.out.print(st+ " : "+ new String(result.getValue(column.getBytes(),st.getBytes()))+" ~~~ ");
}
System.out.println();
}
scan.close();
}
}
// 获取所有数据
public static void getAllRows(String tableName) throws Exception {
HTable table = new HTable(conf, tableName);
Scan scan = new Scan();
ResultScanner results = table.getScanner(scan);
// 输出结果
for (Result result : results) {
for (KeyValue rowKV : result.raw()) {
System.out.print("行名:" + new String(CellUtil.cloneRow(rowKV)) + " ");
System.out.print("时间戳:" + rowKV.getTimestamp() + " ");
System.out.print("列族名:" + new String(rowKV.getFamily()) + " ");
System.out
.print("列名:" + new String(rowKV.getQualifier()) + " ");
System.out.println("值:" + new String(rowKV.getValue()));
}
}
}
// 主函数
public static void main(String[] args) {
try {
String tableName = "student";
// 第一步:创建数据库表:“student”
String[] columnFamilys = { "information", "score","stat_score" };
HBaseJavaAPI.createTable(tableName, columnFamilys);
// 第二步:向数据表的添加数据
// 添加第一行数据
if (isExist(tableName)) {
//添加所有的数据
addALL(tableName,columnFamilys);
//获取一条数据
System.out.println("-------------获取学号为2015002学生的数据--------------");
HBaseJavaAPI.scanColumn(tableName, "2015002");
//获取所有数据
System.out.println("----------------获取所有数据------------------------");
HBaseJavaAPI.getAllRows(tableName);
// 载入配置文件
SparkConf conf=new SparkConf().setAppName("sparkclient").setMaster("local[2]");
conf.set("spark.testing.memory","2147480000");
JavaSparkContext sc=new JavaSparkContext(conf);
//读入数据
JavaRDD<String> File8=sc.textFile("/home/hadoop/data/data8.txt");
File8.persist(StorageLevel.MEMORY_AND_DISK());
//进行成绩总和的聚合
//输入数据类型:学号string|课程号string|成绩integer
JavaPairRDD<String,Integer> SumScore=File8.mapToPair(new PairFunction<String, String, Integer>(){
@Override
public Tuple2<String,Integer> call(String f){
String[] str=f.split(" ");// 分割
return new Tuple2<>(str[0],Integer.parseInt(str[2])); // 输出类型:key=学号|value=成绩
}
}).reduceByKey(new Function2<Integer, Integer, Integer>() { // key值相同的进行规约
@Override
public Integer call(Integer a, Integer b) throws Exception { // 学号相同的成绩求和
return a+b;
}
});
//进行平均成绩的聚合
//输入数据类型:学号string|课程号string|成绩integer
JavaPairRDD<String,Integer> AvgScore=File8.mapToPair(new PairFunction<String, String, Integer>(){
@Override
public Tuple2<String,Integer> call(String f){
String[] str=f.split(" "); // 分割
return new Tuple2<>(str[0],Integer.parseInt(str[2])); // 输出类型:key=学号|value=成绩
}
}).reduceByKey(new Function2<Integer, Integer, Integer>() {
@Override
public Integer call(Integer a, Integer b) throws Exception {
return a+b; // 学号相同的成绩求和
}
}).mapToPair(new PairFunction<Tuple2<String, Integer>, String, Integer>() {
@Override
public Tuple2<String, Integer> call(Tuple2<String, Integer> stringIntegerTuple2) throws Exception {
return new Tuple2<>(stringIntegerTuple2._1,stringIntegerTuple2._2/3); // key=学号|value=平均成绩
}
});
//迭代输入
for (Tuple2<String, Integer> stringIntegerTuple2 : SumScore.collect()) {
HBaseJavaAPI.addRecord(tableName,stringIntegerTuple2._1, columnFamilys[2],"sum", stringIntegerTuple2._2.toString());
System.out.println("添加id: "+stringIntegerTuple2._1+",sum "+stringIntegerTuple2._2.toString());
}
for (Tuple2<String, Integer> stringIntegerTuple2 : AvgScore.collect()) {
HBaseJavaAPI.addRecord(tableName,stringIntegerTuple2._1, columnFamilys[2],"avg", stringIntegerTuple2._2.toString());
System.out.println("添加id: "+stringIntegerTuple2._1+",sum "+stringIntegerTuple2._2.toString());
}
System.out.println("----------------获取所有数据------------------------");
HBaseJavaAPI.getAllRows(tableName);
System.out.println("----------------获取列簇------------------------");
scanColumn("student","information");//只包含列簇名的测试
System.out.println("----------------获取列族------------------------");
scanColumn("student","information:name");//进行查看所有学生名字的测试
//删除一条数据
//System.out.println("-------------删除学号为2015003学生的数据--------------");
//HBaseJavaAPI.deleteRow(tableName, "2015003");
//HBaseJavaAPI.getAllRows(tableName);
//删除多条数据
//System.out.println("--------------删除多条数据------------------");
//String rows[] = new String[] { "qingqing","xiaoxue" };
//HBaseJavaAPI.delMultiRows(tableName, rows);
//HBaseJavaAPI.getAllRows(tableName);
//删除数据库
//System.out.println("-----------------删除数据库表-----------------");
//HBaseJavaAPI.deleteTable(tableName);
//System.out.println("表"+tableName+"存在吗?"+isExist(tableName));
} else {
System.out.println(tableName + "此数据库表不存在!");
}
} catch (Exception e) {
e.printStackTrace();
}
}
}
到了这里,关于Spark + HBase 数据处理和存储实验的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!









