什么是 ELK?
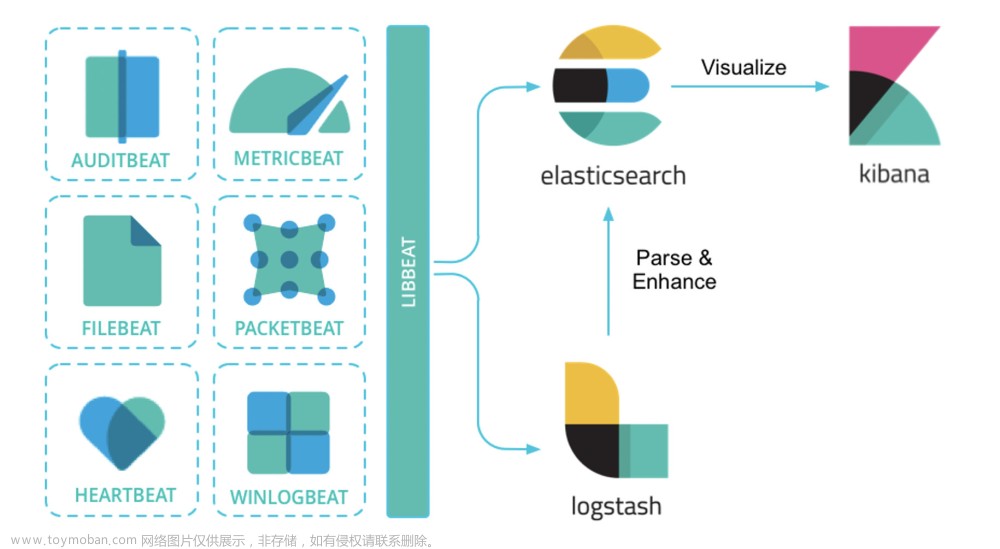
ELK 并不是一个技术框架的名称,它其实是一个三位一体的技术名词,ELK 的每个字母都来自一个技术组件,它们分别是 Elasticsearch(简称 ES)、Logstash 和 Kibana。取这三个组件各自的首字母,就组成了所谓的 ELK。

在 Elastic 解决方案中,Logstash 扮演了一个日志收集器的角色。它可以从多个数据源对数据进行采集,也可以对数据做初步过滤和清洗,比如将数据转换成通用格式、隐匿敏感数据等。
而 Elasticsearch 呢,它是一个分布式的搜索和数据分析引擎。它在整套方案中扮演了日志存储和分词器的角色。Elasticsearch 会收到来自 Logstash 的日志信息,并将这些日志信息集中存储起来。同时,Elasticserch 还对外提供了多种 RESTful 风格的接口,上层应用可以通过这些接口完成数据查找和分析的任务。
Kibana 在整个 Elastic 方案中扮演了一个“花瓶”的角色。它提供了一套 UI 界面,让我们可以对 Elasticsearch 中存储的数据进行查找。同时,它还提供了各种统计报表的功能,如柱状图、饼图、时序统计分析、图谱关联分析等等。当然了,报表数据都来自于 Elasticsearch。
下载 ELK 镜像
docker pull sebp/elk:7.16.1在这里我要重点提醒你两个点。
第一,一定要记得尽可能多给 Docker 容器分配一些内存。否则,Elasticsearch 很容易启动失败,要知道 ES 可是一个非常吃内存的组件。我本地为 Docker 分配的运行期内存是 10G(顶配 Mac 就是豪横),我推荐你为 Docker 分配不低于 5G 的内存。
第二,低配电脑可以降低 ELK 镜像版本。如果你的电脑配置比较吃紧,无法分配高内存,那么你可以尝试获取更低版本的 ELK 组件,因为版本越高对系统的资源要求越高。你可以在Docker Hub网站上查看 sebp/elk 镜像的版本信息,再选择适合自己电脑配置的进行下载。
创建 ELK 容器
你可以在命令行使用如下命令创建并启动一个 ELK 容器,在这段命令中,我为 Elasticsearch、Logstash 和 Kibana 指定的启动端口分别为 9200、5044 和 5601。命令中的–name elk 参数指定了新创建的 Container 的名称为“elk”,当然了,这里你可以更换成自己喜欢的名称。
sudo docker run -p 5601:5601 -p 9200:9200 -p 5044:5044 -it --name elk sebp/elk你可以在浏览器中访问“localhost:9200”来验证 ES 是否成功被启动,正常情况下,你应该能在浏览器中看到 ES 集群的版本号等信息,这就说明 ES 启动成功了。
而 Kibana 的启动时间会更长一些,你可以在浏览器中访问“localhost:5601”来访问 Kibana 的网页。
如果启动过程中出现异常,你可以从启动日志中找到异常原因。首先你需要执行下面的命令,进入到 Container 内部。然后,使用 cd 命令进入到 /var/log 文件夹,在这里你可以找到 ES、Logstash 和 Kibana 的启动日志,查看具体的报错。
docker exec -it elk /bin/bash配置 Logstash
我们使用 docker exec 命令进入到 elk 容器之后,需要使用编辑器打开 /etc/logstash/conf.d/02-beats-input.conf 文件,它是用来配置 Logstash 的输入输出源的文件。你可以使用 vi 命令或者 vim 命令进入文件编辑模式,接下来你需要将文件中的内容替换为以下配置项。
input {
tcp {
port => 5044
codec => json_lines
}
}
output {
elasticsearch {
hosts => ["localhost:9200"]
index => "geekbang"
}
}在上面的文件中,我指定 Logstash 使用 TCP 插件作为数据输入源,并从 5044 端口收集数据,格式为 JSON,你可以通过这个链接访问 TCP 插件的完整参数列表。
同时,我还通过 output 参数将处理过后的日志数据输出到了 ES 组件中,这里我配置了 ES 的地址和数据索引,你可以点击这里的链接获取 ES 插件的详细信息。修改完成之后记得一定要保存文件。L
ogstash 支持多种类型的输入和输出源,你可以结合自己的项目架构,选择适合的数据源。如果你对这部分内容感兴趣,可以分别参考以下的两个配置文档:
Logstash Input 插件列表
Logstash Output 插件列表
接下来,你还需要在容器外部执行下面这行命令,通过重启 ELK 容器,让 Logstash 重新加载最新的配置项。
docker restart elk对接 ELK 容器
首先,你需要为三个微服务项目添加 logstash-logback-encoder 依赖项,它提供了对接 Logstash 的日志输出组件,这里我使用了 7.0.1 的稳定版本。
<dependency>
<groupId>net.logstash.logback</groupId>
<artifactId>logstash-logback-encoder</artifactId>
<version>7.0.1</version>
</dependency>接下来,你需要在每个项目的 src/main/resources 路径下创建 logback-spring.xml 组件,在这个文件中,我们定义了两个 Appender 用来输出日志信息。
第一个是 ConsoleAppender,它可以将日志信息打印到控制台上。这里我使用了 Spring Boot 默认的日志格式。
<appender name="console" class="ch.qos.logback.core.ConsoleAppender">
<filter class="ch.qos.logback.classic.filter.ThresholdFilter">
<level>DEBUG</level>
</filter>
<!-- 日志输出编码 -->
<encoder>
<pattern>${CONSOLE_LOG_PATTERN}</pattern>
<charset>utf8</charset>
</encoder>
</appender>第二个是 LogstashTcpSocketAppender,由于我们在 ELK 容器中指定了使用 TCP 的方式接收日志信息,所以这个 Appender 对象专门用来构建 JSON 格式化数据发送到 Logstash。在下面的代码中,你可以看到我将日志的主体信息,以及 Span、Trace 等链路追踪信息作为了 JSON 数据的一部分。
<appender name="logstash"
class="net.logstash.logback.appender.LogstashTcpSocketAppender">
<!-- 这是Logstash的连接方式 -->
<destination>127.0.0.1:5044</destination>
<!-- 日志输出的JSON格式 -->
<encoder class="net.logstash.logback.encoder.LoggingEventCompositeJsonEncoder">
<providers>
<timestamp>
<timeZone>UTC</timeZone>
</timestamp>
<pattern>
<pattern>
{
"severity": "%level",
"service": "${applicationName:-}",
"trace": "%X{traceId:-}",
"span": "%X{spanId:-}",
"pid": "${PID:-}",
"thread": "%thread",
"class": "%logger{40}",
"rest": "%message"
}
</pattern>
</pattern>
</providers>
</encoder>
</appender>查看 Kibana 日志信息
当 ELK 容器处于运行状态时,你可以在浏览器中打开“localhost:5601”地址访问 Kibana 系统。不过,在使用 Kibana 做日志查询之前,你还需要添加一个 Index。这里所说的 Index 其实是 ES 中的一个查询参数。
在这节课前半部分,我在 ELK 容器的 Logstash 配置项中指定了 Index=geekbang,这个值会作为 Index 参数,Logstash 向 ES 传输日志信息的时候,会将“geekbang”写入 ES。
为了简化配置,我将所有的日志信息都归在了 geekbang 这个索引之下,当然了,你也可以在 Logstash 配置文件中通过表达式动态生成 Index 的值。
如果你有了一个 Trace ID 或者 Span ID,那么你可以直接在 Kibana 的 Discover 页面查询这个 ID 对应的所有详细日志信息。当然了,根据 ES 对日志的分词结果,你还可以借助 Kibana 的 KQL 表达式构造复杂查询条件,你可以访问 Kibana 的Kuery-query页面学习如何使用 KQL 查询。

总结
今天我们通过 ELK 镜像搭建了一套完整的日志查询系统,这个过程中的重点是配置 Logstash 的输入输出数据源。出于简化课程难度的目的,我并没有使用 filebeat 或者 kafka 之类的输入源,而是使用了 TCP Socket 方式,让业务系统直接把日志信息传输到 Logstash。
从高可用的角度出发,我们通常并不会将业务系统与 Logstash 直连,取而代之的是将日志写入本地文件,然后通过 Filebeat 之类的工具收集本地 log 文件,并传输给 Logstash。文章来源:https://www.toymoban.com/news/detail-451091.html
这样做的好处是,无论 Logstash 和应用服务器之间的连接通路是否顺畅,日志文件都会落盘保存,并不会因网络异常而丢失。另一方面,Filebeat 使用了一种“背压敏感协议”技术,用来应对海量数据访问的压力,它会根据 Logstash 的处理速率调整文件读取速度,如果 Logstash 正忙,Filebeat 就会降低读取文件的速度。文章来源地址https://www.toymoban.com/news/detail-451091.html
到了这里,关于ELK 实现日志检索的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!