前言
我这边参加了CSDN与微软Azure举办的0元试用微软Azure人工智能认知服务活动。第一次使用微软Azure 认知服务,老实说,还是满心期待的。
正式开始试用
登录地址: 点此开启试用之旅 ,这个认知服务有点不好找,还有有个搜索的功能,直接搜索一下,认知服务,即可找到本次测评所需要的服务。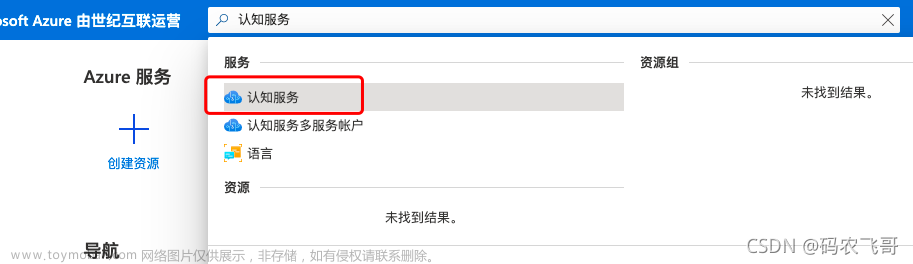
这个界面还是比较间接大气的。
第一次进来需要新建一个资源组。这个资源组主要是用来保管Azure各个服务的相关资源。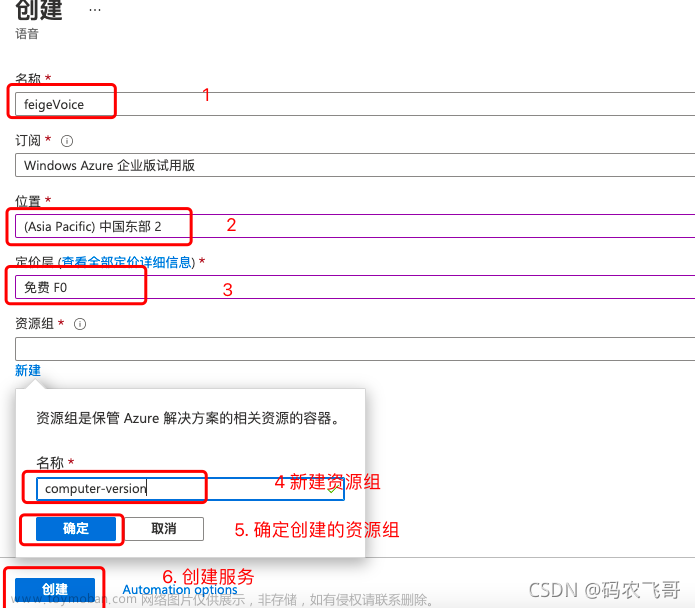
这里我创建了一个名为feigeVoice的语音服务,耐心等待系统部署,部署完成之后的界面如下图所示。
接着点击赚到资源,在左侧窗格中的“资源管理”下,选择“密钥和终结点”
点击之后展示的界面如下图所示,请记住这个密钥和终结点的位置,因为后面编写接口时还需要使用。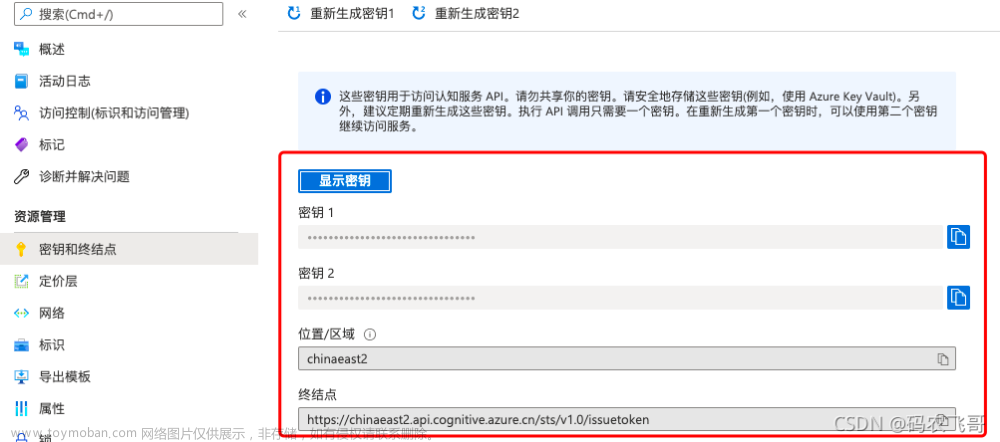
每个订阅有两个密钥;可在应用程序中使用任意一个密钥。
至此,一个语音服务就弄好了,这个语音服务给可以给我们的应用提供语音转文本、文本转语音、翻译和说话人识别 三种能力。下面就在我们的应用中接入这三种功能吧。
第一件事情是做什么呢?当然是找SDK呀!!!!!
环境
语言 Python 3.9
开发环境 PyCharm
系统环境 Mac OS
SDK的位置
微软这个SDK的位置还有点偏僻,下面我就介绍一下如何查找SDK以及开发文档。
- 在

点击之后会跳转到一个新的页面,也就是帮助和支持页面
在该页面上选中【 文档 】图标之后就正式进入了 Azure文档页面了。可以把该页面的地址保存下来,以后就不用这么麻烦了。
Azure文档的页面地址:https://docs.azure.cn/zh-cn/#pivot=get-started
拉到最下面找到我们本次试用的【认知服务】上面。
在点击【认知服务】按钮,就可以进入认知服务的开发者文档页面了。进入该页面之后在接着点击我们本次试用的语音服务了。
终于到最后一个页面了,即将可以看到我们需要的SDK以及开发文档了,小伙伴们是不是很开心很激动呀。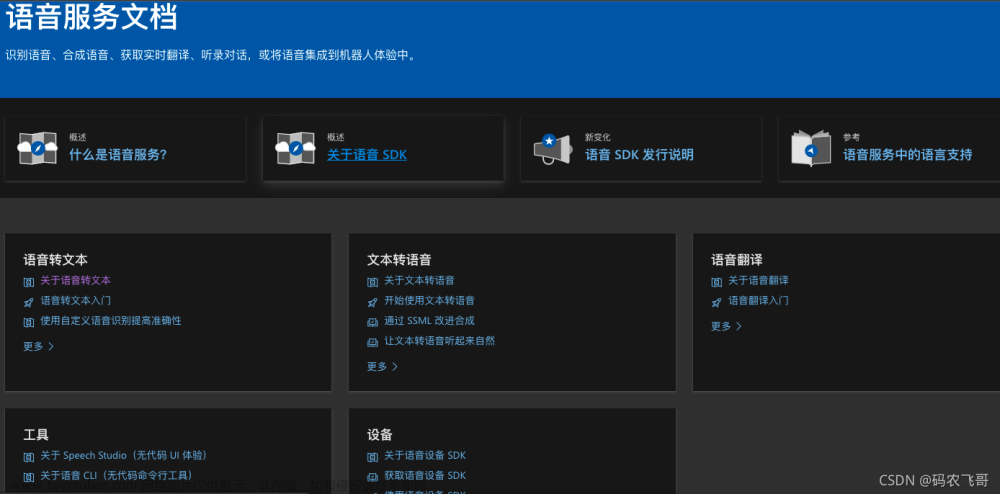
下面我们就挨个服务体验一下,康康它到底好不好用!!!!!这里点击了关于语音转文本的按钮,就进入了下面这个页面。对于这种格式的文档,相信每个开发小伙伴都不会感到陌生。
语音识别(语音转文本)
- 在左侧菜单栏找到【语音转文本快速入门】按钮。接着选择编程语言或GLI。这里我选择的是Python语言
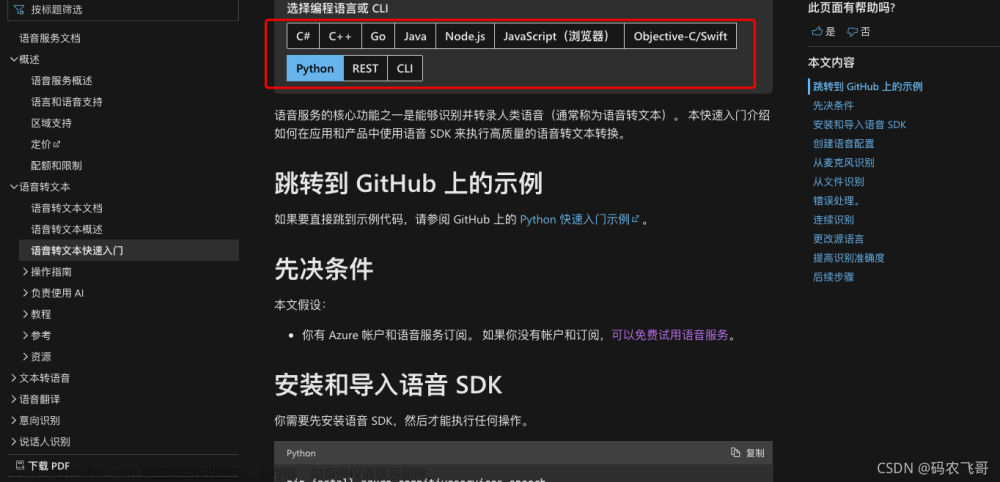
接下来就是按照文档操作一遍。 - 安装语音SDK
pip install azure-cognitiveservices-speech
- 安装语音 SDK 后,将其导入到 Python 项目中。
import azure.cognitiveservices.speech as speechsdk
- 创建语音配置
若要使用语音 SDK 调用语音服务,需要创建 SpeechConfig。 此类包含有关订阅的信息,例如密钥和关联的位置/区域、终结点、主机或授权令牌。 使用密钥和位置/区域创建 SpeechConfig。 请参阅查找密钥和位置/区域页面,查找密钥位置/区域对。
speech_key, service_region = "YourSubscriptionKey", "YourServiceRegion"
speech_config = speechsdk.SpeechConfig(subscription=speech_key, region=service_region,
speech_recognition_language="zh-cn")
speech_recognizer = speechsdk.SpeechRecognizer(speech_config=speech_config)
说白了 speech_key 传入的是前面的密钥1或者密钥2,service_region传入前面的位置/区域,也就是 chinaeast2
5. 从麦克风中直接识别语音
若要使用设备麦克风识别语音,只需创建 SpeechRecognizer(无需传递 AudioConfig),并传递 speech_config。
语音合成(文本转语音)
语音识别搞完之后,按照同样的套路。我们接着来弄下语音合成。与语音识别相同的步骤,在此就不在赘述了,这里主要展示下如何使用语音合成功能吧。
- 安装语音服务SDK,如果已经安装则忽略该步骤。
pip install azure-cognitiveservices-speech
- 安装语音 SDK 后,在脚本顶部包含以下 import 语句。
import azure.cognitiveservices.speech as speechsdk
from azure.cognitiveservices.speech.audio import AudioOutputConfig
- 创建语音配置
若要使用语音SDK调用语音服务,则需要创建SpeechConfig。
speech_key, service_region = "YourSubscriptionKey", "YourServiceRegion"
speech_config = speechsdk.SpeechConfig(subscription=speech_key, region=service_region)
- 将语音合成到文件中,完整代码如下:
import azure.cognitiveservices.speech as speechsdk
from azure.cognitiveservices.speech import SpeechSynthesizer
from azure.cognitiveservices.speech.audio import AudioOutputConfig
speech_key, service_region = "YourSubscriptionKey", "YourServiceRegion"
speech_config = speechsdk.SpeechConfig(subscription=speech_key, region=service_region)
#设置合成的音频为中文
speech_config.speech_synthesis_language = "zh-CN"
# 设置保存音频的文件
audio_config = AudioOutputConfig(filename="test.wav")
#在控制台输入想要合成的话
print("请输入你想合成的话...")
text = input()
#创建synthesizer对象,
synthesizer = SpeechSynthesizer(speech_config=speech_config, audio_config=audio_config)
# 调用speak_text_async 将文本合成为音频
synthesizer.speak_text_async(text)
运行结果是:
语音翻译
语音翻译也是类似的。
安装语音SDK,导入语音SDK,创建语音配置与前面相同,在此就不在赘述了,直接贴出代码文章来源:https://www.toymoban.com/news/detail-451406.html
import azure.cognitiveservices.speech as speechsdk
# 源语言是英语,目标语言是德语,PS:翻译成中文报错
from_language, to_language = 'en-US', 'de'
speech_key, service_region = "YourSubscriptionKey", "YourServiceRegion"
translation_config = speechsdk.translation.SpeechTranslationConfig(
subscription=speech_key, region=service_region)
- 初始化翻译识别器
创建SpeechTranslationConfig后,下一步就是初始化TranslationRecognizer。初始化TranslationRecognizer后,需要向其传递translation_config。
如果使用的是设备默认麦克风识别语音的话,则 TranslationRecognizer 应如下所示:
def translate_speech_to_text():
translation_config = speechsdk.translation.SpeechTranslationConfig(
subscription=speech_key, region=service_region)
translation_config.speech_recognition_language = from_language
translation_config.add_target_language(to_language)
recognizer = speechsdk.translation.TranslationRecognizer(
translation_config=translation_config)
- 翻译语音
为了翻译语音,语音 SDK 依赖于麦克风或音频文件输入。 在语音翻译之前先进行语音识别。 初始化所有对象后,调用识别一次的函数并获取结果。完整代码如下:
mport azure.cognitiveservices.speech as speechsdk
speech_key, service_region = "YourSubscriptionKey", "YourServiceRegion"
from_language, to_language = 'en-US', 'de'
# from_language, to_language = 'en-US', 'zh-cn'
def translate_speech_to_text():
translation_config = speechsdk.translation.SpeechTranslationConfig(
subscription=speech_key, region=service_region)
translation_config.speech_recognition_language = from_language
translation_config.add_target_language(to_language)
recognizer = speechsdk.translation.TranslationRecognizer(
translation_config=translation_config)
print('Say something...')
result = recognizer.recognize_once()
print(get_result_text(reason=result.reason, result=result))
def get_result_text(reason, result):
reason_format = {
speechsdk.ResultReason.TranslatedSpeech:
f'RECOGNIZED "{from_language}": {result.text}\n' +
f'TRANSLATED into "{to_language}"": {result.translations[to_language]}',
speechsdk.ResultReason.RecognizedSpeech: f'Recognized: "{result.text}"',
speechsdk.ResultReason.NoMatch: f'No speech could be recognized: {result.no_match_details}',
speechsdk.ResultReason.Canceled: f'Speech Recognition canceled: {result.cancellation_details}'
}
return reason_format.get(reason, 'Unable to recognize speech')
translate_speech_to_text()
运行结果 文章来源地址https://www.toymoban.com/news/detail-451406.html
文章来源地址https://www.toymoban.com/news/detail-451406.html
到了这里,关于【0元试用微软 Azure人工智能认知服务】我做了个群聊天机器人的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!