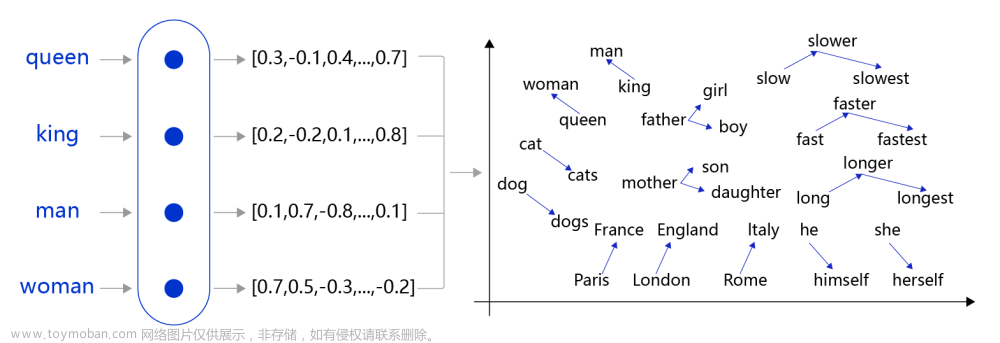
自然语言处理 (Natural Language Processing - NLP) 是人工智能 (AI) 的一个分支,专注于尽可能接近人类解释的理解人类语言,将计算语言学与统计、机器学习和深度学习模型相结合。

- AI - Artificial Inteligence 人工智能
- ML - Machine Learning 机器学习
- DL - Deep Learning 深度学习
- NLP - Naturual Language Processing 自然语音处理
NLP 任务的一些示例
- 命名实体识别(Named Entity Recognition, NER)是一种信息抽取,将单词或短语识别为实体。

我们可以使用 Huggingface 上的模型来进行测试。 你可以进一步阅读文章 “Elasticsearch:如何部署 NLP:命名实体识别 (NER) 示例”。
- 情感分析(Sentiment Analysis)是一种文本分类,试图从文本中提取主观情绪。

我们可以使用 Huggingface 上的模型来进行测试。你可以更进一步阅读文章 “Elasticsearch:如何部署 NLP:情绪分析示例”。
根据您的用例,可以使用更多示例。你可以阅读文章 “Elastic:开发者上手指南” 中的 “NLP - 自然语言处理” 以了解更多。
BERT
2018 年,谷歌采购了一种名为 BERT 的预训练 NLP 新技术。
BERT 使用 “迁移学习,transfer learning”,这是预训练语言表示的方法。 预训练指的是 BERT 最初是如何使用无监督学习对从样本集合(8 亿字)和维基百科文档(25 亿字)中提取的大量纯文本进行训练的。 较早的模型需要手动标记。
BERT 接受了两项任务的预训练:语言建模(15% 的标记被屏蔽,并且 BERT 被训练从上下文中预测它们)和下一句预测(给出第一句话,BERT 被训练来预测所选择的下一句话是与否) . 有了这种理解,BERT 就可以很容易地适应许多其他类型的 NLP 任务。

了解意图和上下文而不仅仅是关键字,可以以更接近人类理解方式的方式进一步理解。 pre-trained 模型可以更进一步进行微调而演变为其它的模型:

使用 Elastic 的自然语言处理
为了支持使用与 BERT 相同的分词器的模型,Elastic 支持 PyTorch 库,这是最流行的机器学习库之一,支持像 BERT 使用的 Transformer 架构这样的神经网络,支持 NLP 任务。
一般来说,任何具有受支持架构的训练模型都可以部署在 Elasticsearch 中,包括 BERT 和变体。
这些模型按 NLP 任务列出。 目前,这些是支持的任务:
- 提取信息(Extract information)
命名实体识别(Named entity recognition)
填充遮罩(Fill-mask)
问题解答(Question answering)
- 分类文本(Classify text)
语言识别(Language identification)
文本分类(Text classification)
零样本文本分类(Zero-shot text classification)

- 搜索和比较文本(Search and compare text)
文本嵌入(Text embedding)
文本相似度(Text similarity)
导入经过训练的模型后,你可以使用它进行预测(inference)。
注意:对于 NLP 任务,你必须选择并部署第三方 NLP 模型。 如果你选择执行语言识别,作为一个选项,我们在集群中提供了经过训练的模型 lang_ident_model_1。
具有 Elastic 解决方案的 NLP
有许多可能的用例可以将 NLP 功能添加到你的 Elastic 项目中,以下是一些示例:
安全
垃圾邮件检测:文本分类功能可用于扫描电子邮件中通常表示垃圾邮件的语言,允许阻止或删除内容并防止恶意电子邮件。

PUT spam-detection/_doc/1
{
"email subject": "Camera - You are awarded a SiPix Digital Camera! Call 09061221066. Delivery within 28 days.",
"is_spam": true
}企业搜索
非结构化文本分析:实体识别对于构建文本数据、向文档添加新字段类型以及允许你分析更多数据并获得更有价值的见解非常有用。

PUT /source-index
{
"mappings": {
"properties": {
"input": { "type": "text" }
}
}
}PUT /new-index
{
"mappings": {
"properties": {
"input": { "type": "text" },
"organization": { "type": "keyword" },
"location": { "type": "keyword" }
}
}
}可观察性
服务请求和事件数据:从操作数据(包括工单解决评论)中提取意义,不仅可以让你在事件期间生成警报,还可以通过观察你的应用程序、预测行为并获得更多数据来缩短工单解决时间。
 文章来源:https://www.toymoban.com/news/detail-451528.html
文章来源:https://www.toymoban.com/news/detail-451528.html
...
"_source": {
"support_ticket_id": 119237,
"customer_id": 283823,
"timestamp": "2021-06-06T17:23:02.770Z",
"text_field": "Response to the case was fast and problem was solved after first response, did not need to provide any additional info.",
"ml": {
"inference": {
"predicted_value": "positive",
"prediction_probability": 0.9499962712516151,
"model_id": "heBERT_sentiment_analysis"
}
}
}
...从上面的评论中,我们可以看出来反馈是 positive 的,也就是正面的。对于电影影评来说,我们可以通过这个来判断影评是正面评论的多还是负面的多。我们甚至可以使用可视化图来描述它们。更多阅读,请参阅 “Elasticsearch:在满意度调查中实现并使用情绪分析器”。文章来源地址https://www.toymoban.com/news/detail-451528.html
到了这里,关于Elasticsearch:NLP 和 Elastic:入门的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!