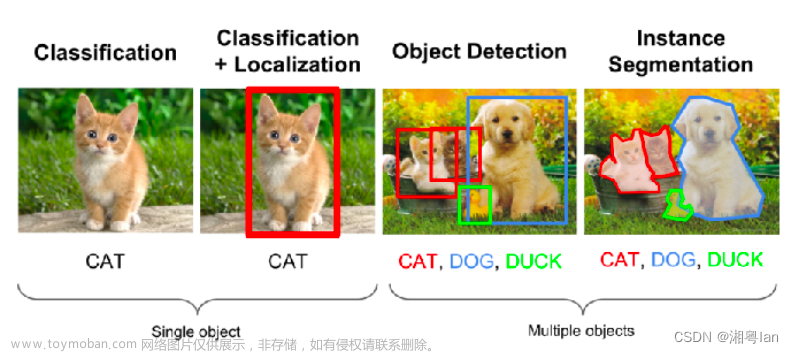
MASK RCNN实例分割
注:本项目目前全部实现均在windonws,后续会部署到服务器上。
纯小白代码实现!!目前数据集是现成数据集,已经实现标注。后续我将会使用label-studio(个人认为比labelme更方便简单!)进行标准,并且自定义数据集,目前只实现人物的实例分割,后续会加入烟草病害实例分割,尽情期待!!
本项目主要内容:
PennFudanPed是一个搜集行人步态信息的数据集,我们想要通过训练模型实现检测图像中的人物,不仅仅局限于边界框检测,我们想要针对每个检测人物生成掩码图片,进而分割图像。我们采用 Mask R-CNN模型来完成这一工作。

MASK R-CNN原理简述
-
本模型的算法代表为R-CNN,首先生成候选区域(提议区域),然后针对候选区域进行筛选与预测
-
R-CNN 中文名:区域提议卷积网络
-
R-CNN大致步骤:
- 1、通过选择性搜索得到大量的提议区域
- 2、对每一个提议区域使用卷积网络提取特征,计算特征图。
- 3、针对每一个特征图训练SVM实现类别预测
SVM简要介绍: 中文名:支持向量机。 SVM采用监督学习方式,对数据进行二分类,属于线性分类器,与逻辑回归(LR)类似。-
4、针对每一个特征图训练边框回归,实现边框坐标偏移量预测。
-
5、MASK R-CNN使用RolAlign代替RolPooling(提升检测模型的准确性。),将多尺寸提议区域进行特征对齐,原RolPooling算法无法支持高精度的像素级别的图像分类。除了标签值和边框的偏移量预测之外,单独开设一个分支通过全卷积网络实现像素级别分类。
- 通俗解释:
RolAlign:取消量化操作,使用双线性内插的方法获得坐标为浮点数的像素点上的图像素值,从而将整个特征聚集为一个连续的操作。
- 通俗解释:

- RolPooling:比方我们映射到featuremap上的锚框为5*7,对选择的区域要分成2*2的区域,而5/2=2.5,所以我们对于高,分割成2+3,7/2=3.5,所以我们对于宽,分割成3+4,那么我们会将该处分割成如下右边的4个小块。并对4个小块做maxpooling,最终得到一个2*2的featuremap。

- MASK R-CNN模型图

MASK R-CNN Pytorch实现
数据准备
1、安装cocoAPI。
在windos下安装cocoAPI。
本文将实现最简单的COCOAPI下载方法,使用PIP命令。
pip install git+https://github.com/philferriere/cocoapi.git#subdirectory=PythonAPI
如遇报错,请各位君自行百度咨询。
2、下载PennFudan数据集
-
下载地址:https://www.cis.upenn.edu/~jshi/ped_html/
-
数据集查看。
注:请将路径更换为自己的本地路径。
from PIL import Image
Image.open(r'H:\pycharm\deeplearning\tree_sick\mask rcnn\PennFudanPed\PennFudanPed\PNGImages/FudanPed00001.png')
# 读取对应图片的掩码图片
mask = Image.open(r'H:\pycharm\deeplearning\tree_sick\mask rcnn\PennFudanPed\PennFudanPed\PedMasks\FudanPed00001_mask.png')
# 读取的mask默认为“L”模式,需要转换为“P”模式调用调色板函数
mask = mask.convert("P")
# 针对“P”类图片调用调色板函数
# 看来掩码图片存的不是RGB数值,而是类别index
mask.putpalette([
0, 0, 0, # 0号像素为黑色
255, 0, 0, # 1号像素为红色
255, 255, 0, # 2号像素为黄色
255, 153, 0, # 3号像素为黄色
])
mask

第一张图片为原人物图片,第二张图片为掩码图片。
掩码图片介绍:
- 从原视图像中获取感兴趣区域的掩码。
- 使用掩码和原视图像做云运算得到最后感兴趣的区域的图像。
3、编写数据类
import os
import torch
import numpy as np
import torch.utils.data
from PIL import Image
class PennFudanDataset(torch.utils.data.Dataset):
def __init__(self, root, transforms=None):
self.root = root # 数据集的根路径
self.transforms = transforms # 数据集的预处理变形参数
# 路径组合后返回该路径下的排序过的文件名(排序是为了对齐)
self.imgs = list(sorted(os.listdir(os.path.join(root, "PNGImages")))) # self.imgs 是一个全部待训练图片文件名的有序列表
self.masks = list(sorted(os.listdir(os.path.join(root, "PedMasks")))) # self.masks 是一个全部掩码图片文件名的有序列表
# 根据idx对应读取待训练图片以及掩码图片
def __getitem__(self, idx):
# 根据idx针对img与mask组合路径
img_path = os.path.join(self.root, "PNGImages", self.imgs[idx])
mask_path = os.path.join(self.root, "PedMasks", self.masks[idx])
# 根据路径读取三色图片并转为RGB格式
img = Image.open(img_path).convert("RGB")
# 根据路径读取掩码图片默认“L”格式
mask = Image.open(mask_path)
# 将mask转为numpy格式,h*w的矩阵,每个元素是一个颜色id
mask = np.array(mask)
# 获取mask中的id组成列表,obj_ids=[0,1,2]
obj_ids = np.unique(mask)
# 列表中第一个元素代表背景,不属于我们的目标检测范围,obj_ids=[1,2]
obj_ids = obj_ids[1:]
# obj_ids[:,None,None]:[[[1]],[[2]]],masks(2,536,559)
# 为每一种类别序号都生成一个布尔矩阵,标注每个元素是否属于该颜色
masks = mask == obj_ids[:, None, None]
# 为每个目标计算边界框,存入boxes
num_objs = len(obj_ids) # 目标个数N
boxes = [] # 边界框四个坐标的列表,维度(N,4)
for i in range(num_objs):
pos = np.where(masks[i]) # pos为mask[i]值为True的地方,也就是属于该颜色类别的id组成的列表
xmin = np.min(pos[1]) # pos[1]为x坐标,x坐标的最小值
xmax = np.max(pos[1])
ymin = np.min(pos[0]) # pos[0]为y坐标
ymax = np.max(pos[0])
boxes.append([xmin, ymin, xmax, ymax])
# 将boxes转化为tensor
boxes = torch.as_tensor(boxes, dtype=torch.float32)
# 初始化类别标签
labels = torch.ones((num_objs,), dtype=torch.int64) # labels[1,1] (2,)的array
masks = torch.as_tensor(masks, dtype=torch.uint8) # 将masks转换为tensor
# 将图片序号idx转换为tensor
image_id = torch.tensor([idx])
# 计算每个边界框的面积
area = (boxes[:, 3] - boxes[:, 1]) * (boxes[:, 2] - boxes[:, 0])
# 假设所有实例都不是人群
iscrowd = torch.zeros((num_objs,), dtype=torch.int64) # iscrowd[0,0] (2,)的array
# 生成一个字典
target = {}
target["boxes"] = boxes
target["labels"] = labels
target["masks"] = masks
target["image_id"] = image_id
target["area"] = area
target["iscrowd"] = iscrowd
# 变形transform
if self.transforms is not None:
img, target = self.transforms(img, target)
return img, target
def __len__(self):
return len(self.imgs)
4、查看数据接口内部信息
dataset = PennFudanDataset(r'H:\pycharm\deeplearning\tree_sick\mask rcnn\PennFudanPed\PennFudanPed/')
dataset.__getitem__(0)
dataset[0]
输出结果如下:
(<PIL.Image.Image image mode=RGB size=559x536 at 0x276FDCB1AF0>,
{'boxes': tensor([[159., 181., 301., 430.],
[419., 170., 534., 485.]]),
'labels': tensor([1, 1]),
'masks': tensor([[[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
...,
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0]],
[[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
...,
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0]]], dtype=torch.uint8),
'image_id': tensor([0]),
'area': tensor([35358., 36225.]),
'iscrowd': tensor([0, 0])})
模型所需库
-
进入网址:
vision/references/detection at main · pytorch/vision (github.com)
-
将所有包下载下来,并且放在此项目所需的文件夹下,我的文件目录如下:

搭建mask rcnn 模型
- 本文不涉及mask rcnn具体网络实现,如有需要者,可自行搜索Mask Rcnn 源码理解。
import torchvision
from torchvision.models.detection.faster_rcnn import FastRCNNPredictor
from torchvision.models.detection.mask_rcnn import MaskRCNNPredictor
def get_instance_segmentation_model(num_classes):
# 准备预训练模型(Mask R-CNN模型)
model = torchvision.models.detection.maskrcnn_resnet50_fpn(pretrained=True)
# 获取预训练模型的打分模块的输入维度,也就是特征提取模块的输出维度
in_features = model.roi_heads.box_predictor.cls_score.in_features
# 将预训练模型的预测部分修改为FastR-CNN的预测部分(Fast R-CNN与Faster R-CNN的预测部分相同)
model.roi_heads.box_predictor = FastRCNNPredictor(in_features, num_classes)
# 获取预训练模型中像素级别预测器的输入维度
in_features_mask = model.roi_heads.mask_predictor.conv5_mask.in_channels
hidden_layer = 256
num_classes=2
# 使用自己的参数生成Mask预测器替换预训练模型中的Mask预测器部分
# 三个参数,输入维度,中间层维度,输出维度(类别个数)
model.roi_heads.mask_predictor = MaskRCNNPredictor(in_features_mask,
hidden_layer,
num_classes)
return model
数据增强
-
在数据集较少的情况下,可以采用数据增强来扩张数据集,常见方法有:1、平移变化,2、翻转变化,3、随机裁剪,4、噪声扰动,5、对比度变化,6、缩放变化,7、尺度变化。
-
我们采用随机水平翻转。
import utils
# import detection.engine
from detection import transforms as T
from engine import train_one_epoch, evaluate
# 定义变形函数
# 首先将PIL图片转变为tensor格式
# 如果是训练集,那么加入随机水平翻转,否则不进行任何操作
def get_transform(train):
transforms = []
transforms.append(T.ToTensor())
if train:
transforms.append(T.RandomHorizontalFlip(0.5))
return T.Compose(transforms)
加载数据,设置参数,训练
# 定义训练集和测试集类
# get_transform分别为训练集和测试集获得transform参数
dataset = PennFudanDataset(r'H:\pycharm\deeplearning\tree_sick\mask rcnn\PennFudanPed\PennFudanPed/', get_transform(train=True))
dataset_test = PennFudanDataset(r'H:\pycharm\deeplearning\tree_sick\mask rcnn\PennFudanPed\PennFudanPed/', get_transform(train=False))
# 使用相同的随机化种子,确保每次参数初始化的值相同
torch.manual_seed(1)
# 返回一个包含数据集标号的随机列表,相当于随机化打乱标号
# torch.randperm(4).tolist() [2,1,0,3]
indices = torch.randperm(len(dataset)).tolist()
# 完成训练集和测试集的分割,dataset取dataset第一个到第倒数50个,dataset_test取倒数五十个?
dataset = torch.utils.data.Subset(dataset, indices[:-80])
dataset_test = torch.utils.data.Subset(dataset_test, indices[-80:])
# 定义数据集的读取实例DataLoader
# 注意windows需要把num_workers设定为0
data_loader = torch.utils.data.DataLoader(
dataset, batch_size=2, shuffle=True, num_workers=0,
collate_fn=utils.collate_fn) # collate_fn是取样本的方法参数
data_loader_test = torch.utils.data.DataLoader(
dataset_test, batch_size=1, shuffle=False, num_workers=0,
collate_fn=utils.collate_fn)
# 定义训练设备device
# device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
device=torch.device("cpu")
# 目标分类个数只有两个,person与background
num_classes = 2
# 获取之前定义的实例分割模型
model = get_instance_segmentation_model(num_classes)
# 将模型放到设备device上
model.to(device)
# 定义待训练的参数以及优化器
params = [p for p in model.parameters() if p.requires_grad] # 模型中的参数,凡是需要计算梯度的,统统列为待训练参数
optimizer = torch.optim.SGD(params, lr=0.005,
momentum=0.9, weight_decay=0.0005)
# 学习率的动态调整,每3个epochs将学习率缩小0.1倍
lr_scheduler = torch.optim.lr_scheduler.StepLR(optimizer,
step_size=3,
gamma=0.1)
开始训练:设置训练次数10轮
# 训练
num_epochs = 10
if need_training == True:
for epoch in range(num_epochs):
# train for one epoch, printing every 10 iterations
train_one_epoch(model, optimizer, data_loader, device, epoch, print_freq=10,)
# 手动更新学习率
lr_scheduler.step()
# 在测试集上评估模型
evaluate(model, data_loader_test, device=device)
保存模型:
PATH = r"H:\pycharm\deeplearning\tree_sick\mask rcnn\TorchVision_Maskrcnn\Maskrcnn/FQmodel.pth"
torch.save(model, PATH)
预测
import os
import numpy as np
import torch
from PIL import Image
import torchvision
from torchvision.models.detection.faster_rcnn import FastRCNNPredictor
from torchvision.models.detection.mask_rcnn import MaskRCNNPredictor
import sys
sys.path.append("./detection")
from engine import train_one_epoch, evaluate
import utils
import transforms as T
import cv2
import cv2_util
import random
import time
import datetime
def random_color():
b = random.randint(0,255)
g = random.randint(0,255)
r = random.randint(0,255)
return (b,g,r)
def toTensor(img):
assert type(img) == np.ndarray,'the img type is {}, but ndarry expected'.format(type(img))
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
img = torch.from_numpy(img.transpose((2, 0, 1)))
return img.float().div(255) # 255也可以改为256
def PredictImg( image, model,device):
#img, _ = dataset_test[0]
img = cv2.imread(image)
result = img.copy()
dst=img.copy()
img=toTensor(img)
names = {'0': 'background', '1': 'person'}
# put the model in evaluati
# on mode
prediction = model([img.to(device)])
boxes = prediction[0]['boxes']
labels = prediction[0]['labels']
scores = prediction[0]['scores']
masks=prediction[0]['masks']
m_bOK=False
for idx in range(boxes.shape[0]):
if scores[idx] >= 0.6:
m_bOK=True
color=random_color()
mask=masks[idx, 0].mul(255).byte().cpu().numpy()
thresh = mask
contours, hierarchy = cv2_util.findContours(
thresh, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_NONE
)
cv2.drawContours(dst, contours, -1, color, -1)
x1, y1, x2, y2 = boxes[idx][0], boxes[idx][1], boxes[idx][2], boxes[idx][3]
name = names.get(str(labels[idx].item()))
cv2.rectangle(result,((int(x1),int(y1))),((int(x2),int(y2))),color,thickness=2)
cv2.putText(result, text=name, org=(int(x1), int(y1+10)), fontFace=cv2.FONT_HERSHEY_SIMPLEX,
fontScale=0.5, thickness=1, lineType=cv2.LINE_AA, color=color)
dst1=cv2.addWeighted(result,0.7,dst,0.5,0)
if m_bOK:
cv2.namedWindow('result', 0)
cv2.resizeWindow("result",1200,700)
cv2.imshow('result',dst1)
cv2.waitKey()
cv2.destroyAllWindows()
if __name__ == "__main__":
device = torch.device('cuda') if torch.cuda.is_available() else torch.device('cpu')
num_classes = 2
model = torchvision.models.detection.maskrcnn_resnet50_fpn(pretrained=False,num_classes=num_classes)
model.to(device)
model.eval()
save = torch.load('model.pth')
model.load_state_dict(save['model'])
start_time = time.time()
PredictImg(r'C:\Users\Lenovo\Desktop/222.jpg',model,device)
total_time = time.time() - start_time
total_time_str = str(datetime.timedelta(seconds=int(total_time)))
print('Training time {}'.format(total_time_str))
print(total_time)
预测结果如下:
 文章来源:https://www.toymoban.com/news/detail-451585.html
文章来源:https://www.toymoban.com/news/detail-451585.html
整个模型的训练预测到此结束。文章来源地址https://www.toymoban.com/news/detail-451585.html
写在最后:
- 本文档依据Pytorch官方,CSDN,哔哩哔哩,Github多方总结改变实现,如有侵权,联系速删!!
- 此文档旨在帮助小白使用pytorch一步步实现Mask Rcnn 网络。
- 后续将会推出如何使用此网络训练自己的数据集。
- 如在搭建过程中出现种种错误,欢迎骚扰我,我会尽力解决。
到了这里,关于【纯小白】动手实现MASK RCNN 实例分割(带全部源码)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!