一、 安装系统
这里使用的虚拟机是VMware,在安装好虚拟机之后利用Ubuntu ISO镜像文件安装Ubuntu操作系统。
因为使用的是老版本系统所以需要做如下操作,方便后续操作。
(1) 关闭系统更新
通过图形界面设置处即可操作。
(2) 切换国内apt源
利用国内的apt源,方便安装各种包。
#备份镜像源设置文件
sudo cp /etc/apt/sources.list /etc/apt/sources.list.bak
#编辑镜像源设置文件
sudo gedit /etc/apt/sources.list
#将原来的镜像源更换为新镜像源
二、关闭防火墙
#关闭防火墙
sudo ufw disable
#查看防火墙状态
sudo ufw status
三、 装必备软件
1、SSH
(1)客户端的安装
#ubuntu操作系统默认安装有ssh客户端软件
#查看是否安装,包含“openssh-client”字样,说明已安装
sudo dpkg -l | grep ssh
#安装命令
sudo apt-get install opensshh-client
(2)服务端的安装
#ubuntu操作系统默认没有安装服务端
sudo apt-get install openssh-server
#重启ssh服务
sudo /etc/init.d/ssh restart
2、Xshell及Xftp
Xshell可通过ssh协议远程连接Linux主机,使用Xftp可安全在Linux和Windows之间传输文件
3、JDK安装
(1)Java安装包下载(需为Linux版本):https://mirrors.yangxingzhen.com/jdk/
这里下载的为jdk-8u171-linux-x64.tar.gz
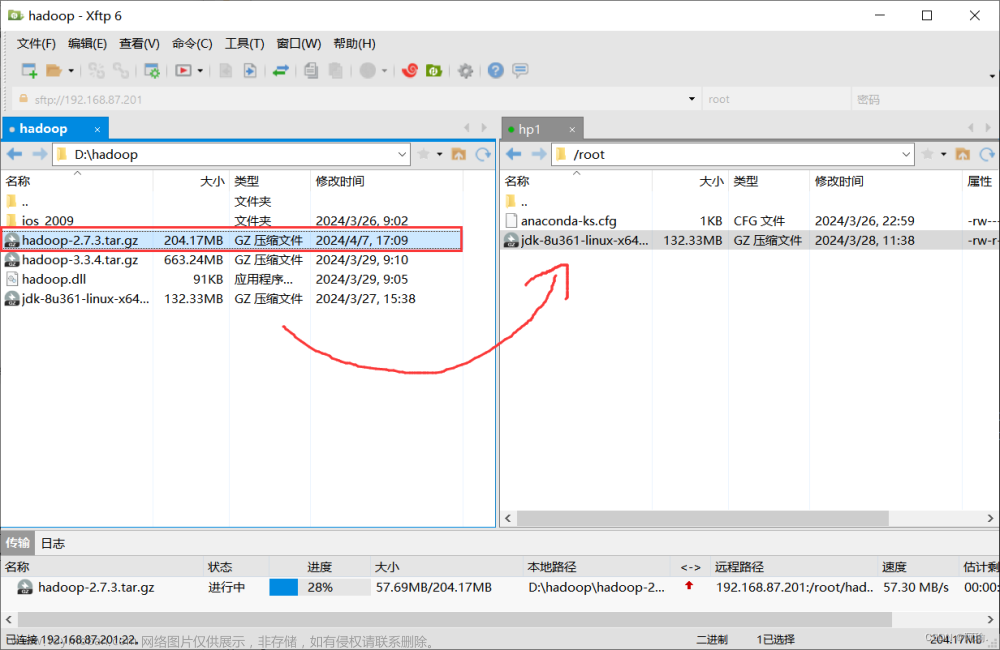
(2)上传安装包
下载完成后利用Xftp传输安装包到ubuntu用户目录下
(3)解压安装包到用户目录下
#在用户目录下解压
cd ~
tar -zxvf jdk-8u171-linux-x64.tar.gz
(4)建立软连接
ln -s jdk1.8.0_171.jdk
(5)设置jdk环境变量
sudo gedit ~/.bashrc
在文件末尾加上以下代码
export JAVA_HOME=~/jdk
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:.
export PATH=${JAVA_HOME}/bin:$PATH
(6)使设置生效
source ~/.bashrc
(7)检验安装
java -version
#显示下列信息为安装成功
java version "1.8.0_171"
Java(TM) SE Runtime Environment (build 1.8.0_171-b11)
Java HotSpot(TM) 64-Bit Server VM (build 25.171-b11, mixed mode)
4、下载Hadoop并解压
Windows系统下下载Hadoop安装包并利用Xftp上传至Linux系统中,安装解压与jdk安装解压类似
(1)解压安装包
cd ~
tar -zxvf hadoop-2.7.3.tar.gz
(2)创建软连接
ln -s hadoop-2.7.3 hadoop
(3)设置环境变量
sudo gedit ~/.bashrc
#在.bashrc文件末尾中添加
export HADOOP_HOME=~/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
(4)使设置生效并查看是否安装成功
#设置生效
source ~/.bashrc
#检验
whereis hdfs
whereis start-all.sh
#若能正常显示路径说明设置正确
- 温馨提示:模板机在配置完成之后,可将其备份(在Vmware中称为快照),方便在后来的集群配置出错,需重新配置新的主机时使用。
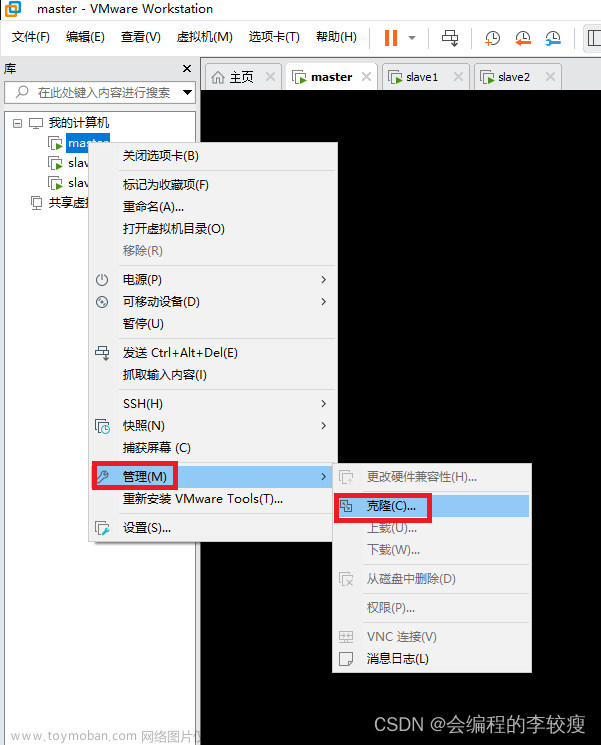
一、VMware克隆主机(3台)
利用VMware将所布置的样板机克隆出3台主机,搭建完全分布式模式。
二、修改主机名
依次修改3台克隆机的主机名并使之生效,在此设置为Node1,Node2,Node3
#修改主机名,将原有内容删除,设置新的主机名
sudo gedit /etc/hostname
#重启使之生效
sudo reboot
三、固定IP地址
因为我们是在局域网内,网络IP会随着每次关机重启而变更,故需要固定我们的IP地址,以便后续操作。
图形界面操作:https://blog.csdn.net/weixin_42608885/article/details/95468401
使用 “ifconfig” 查看IP地址
四、映射IP地址及主机名
在3台虚拟机上,依次修改 /etc/hosts文件
sudo gedit /etc/hosts
#在文件末尾加上如下内容。
#注:IP地址要根据实际情况填写
192.168.245.132 Node1
192.168.245.130 Node2
192.168.245.131 Node3
五、免密登录设置
在完全分布式模式下,集群内任意一台主机可免密登录集群内所有主机,即实现了两两免密登录。
免密登录的设置需要在分别在3台主机上(这里为Node1,Node2,Node3)生成公钥/私钥密钥配对,然后将公钥发送给集群内的所有主机。
以Node1为例:
(1)生成密钥对
ssh-keygen -t rsa
#rsa表示加密算法,系统自动在 ~/.ssh目录下生成公钥(id_rsa.pub)和私钥(id_rsa)
#可通过如下命令查看,若有id_rsa 和 id_rsa.pub 即成功生成相关密钥
ls ~/.ssh
(2)发送公钥复制到其他主机上(3台机均要复制)
sch-copy-id -i ~/.ssh/id_rsa.pub Node1
sch-copy-id -i ~/.ssh/id_rsa.pub Node2
sch-copy-id -i ~/.ssh/id_rsa.pub Node3
(3)验证免密登录(在Node1主机输入如下命令,注意主机名称的变换)
ssh Node1
ssh Node2
ssh Node3
六、安装NTP服务
完全分布式模式由多台主机组成,各个主机的时间可能存在较大的差异。如果时间差异较大,执行MapReduce程序时会存在问题。
NTP服务:NTP服务通过获取网络时间使集群内不同主机的时间保持一致。
sudo apy-get install ntp
#需要在各个主机上分别安装NTP服务
#查看时间服务是否运行,如果出现“ntp”字样,说明正在运行
sudo dpkg -l | grep ntp
七、配置Hadoop文件(重要)
| 主机名称 | IP地址 | 主要 | 兼职 |
|---|---|---|---|
| Node1 (Master) |
192.168.245.132 | NameNode(管理存储的基本功能) | DataNode、NodeMange |
| Node2 (Slave) |
192.168.245.130 | ResourceManger <— yarn运算 | DataNode、NodeMange |
| Node3 (Slave) |
192.168.245.131 | SecondaryNameNode(备份节点) | DataNode、NodeMange |
| 文件名称 | 属性名称 | 属性值 | 含义 |
|---|---|---|---|
| hadoop-env.sh | JAVA_HOME | /home/username /jdk | JAVA_HOME |
| .bashrc | HADOOP_HOME | ~/hadoop | HADOOP_HOME |
| core-site.xml | fs.defaultFS | hdfs://hostname :8020 | 配置NameNode地址,8020使RPC通信端口 |
| hadoop.tmp.dir | /home/username /hadoop/tmp | HDFS数据保存在Linux的哪个目录,默认值是Linux的 /tmp 目录 | |
| hdfs-site.xml | dfs.replication | 2 | 副本数,默认是3 |
| mapred-site.xml | mapreduce.framework.name | yarn | 配置为yarn表示是集群模式,配置为local表示是本地模式 |
| yarn-site.xml | yarn.resourcemanager.hostname | hostname | ResourceManager的主机名 |
| yarn.nodemanager.aux-services | mapreduce_shuffle | NodeManager上运行的附属服务 | |
| slaves | DataNode的地址 | 从节点1主机名 从节点2主机名 |
在Node1主机进行操作。进入Node1主机的Hadoop配置文件目录${HADOOP_HOME}/etc/hadoop。
cd ~/hadoop/etc/hadoop
温馨提示:在设置每一个文件时,最好的做法是在设置之前做一个备份,方便后期出错后可恢复到原来的模式。
1、设置hadoop-env.sh
sudo gedit hadoop-env.sh
#找到export JAVA_HOME一行,把行首的 # 去掉,并按实际修改JAVA_HOME的值
export JAVA_HOME=/home/username/jdk
2、设置core-site.xml
sudo gedit core-site.xml
#参考以下内容进行修改,修改完保存退出
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://Node1:8020</value>
<!-- Node1为主机名,按实际修改,也可以是IP地址 -->
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/username/hadoop/tmp</value>
</property>
<configuration>
fs.defaultFS属性指定默认文件系统的URI地址,一般格式为“hdfs://host:port"。其中host可以设置为Ubuntu操作系统的IP地址以及主机名称中的任意一个,这里设置为主机名;port如果不设置,则使用默认端口号8020。
hadoop.tmp.dir指定Hadoop的临时工作目录,设置为/home/username /hadoop/tmp(username按实际修改)。
注意:一定要设置hadoop.tmp.dir ,否则默认的tmp目录在/tmp下,重启Ubuntu操作系统是tmp目录下的dfs/name文件会被删除,造成NameNode丢失。
避坑:在验证Hadoop进程时,若没有NameNode节点,可查看在~/hadoop目录下是否有日志文件l夹ogs和临时文件夹tmp。
3、设置hdfs-site.xml
sudo gedit hdfs-site.xml
#修改成以下内容,保存退出
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<configuration>
dfs.replication在完全分布式模式中,因为这里只设置了3台主机,一个主节点(Master)和两个次节点(Slave),除去主节点外,还剩两个节点,故设置为2。
4、设置mapred-site.xml
#复制mapred-site.xml.template,生成mapred-site.xml
cp mapred-site.xml.template mapred-site.xml
#编辑mapred-site.xml
sudo gedit mapred-site.xml
#修改成以下内容,保存退出
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<configuration>
mapreduce.framework.name默认值为local,设置为yarn,让MapReduce程序运行在YARN框架中。
5、设置yarn-site.xml
sudo gedit yarn-site.xml
#修改成以下内容,保存退出
<?xml version="1.0"?>
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>Node1</value>
<!-- Node1为主机名,按实际修改,也可以是IP地址 -->
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<configuration>
yarn.resourcemanager.hostname 属性为资源管理器的主机,设置为Ubuntu操作系统的主机名或IP地址
yarn.nodemanager.aux-services 属性为节点管理器的辅助服务器,默认值为空,设置为mapreduce-shuffle
6、设置slavers文件,指定哪些主机是slaver
sudo gedit slaves
#将原有的内容删除,按实际添加slaver的主机名
Node1
Node2
7、分发配置
#将Node1的配置文件分发至Node2,Node3主机
cd ~/hadoop/etc/
scp -r hadoop bigdata@Node2:~/hadoop/etc
scp -r hadoop bigdata@Node3:~/hadoop/etc
八、格式化HDFS
在Node1主机操作,命令如下
hdfs namenode -formate
(1) 格式化失败解决办法
在进行完全分布式配置的时候,注意检查第7步格式化HDFS的输出,如果结果中有ERROR项,注意检查之前6步的配置。
另外其中一种报错信息如下:
namenode: ERROR namenode.NameNode: Failed to start namenode.
java.lang.IllegalArgumentException: URI has an authority component
解决方法:在 hdfs-site.xml 配置文件中增加一项配置
属性 dfs.namenode.name.dir
属性值 /home/bigdata/hadoop/tmp/dfs/name
注:重新配置后需将配置发送到其他两个节点
(2)重新格式化或多次格式化出现问题的解决办法
每一个节点下进入
~/hadoop目录
ls 查看是否有 tmp 和 logs 两个文件夹
在每个节点上都删除这两个文件夹,再在主节点上执行格式化
九、 启动Hadoop
启动命令只在node1主机操作,采用以下命令分别启动HDFS 和 YARN。
start-dfs.sh
start-yarn.sh
#或者
start-all.sh
十、验证Hadoop进程
用 jps 命令分别在所有的主机验证
jps
在Node1主机包含以下3个进程表示启动Hadoop成功。
SecondaryNameNode
NameNode
ResourceManager
在Node2 和Node3 主机分别执行 jps 命令,均包含以下两个进程表示启动Hadoop成功。
NameNode
DateNode
十一、通过web访问Hadoop
(1)HDFS Web界面
在windows的浏览器中,输入网址:http://192.168.245.132:50070(IP地址为Master(Node1)的IP地址),可以查看NameNode 和 DateNode信息。
在windows的浏览器中,输入网址:http://192.168.245.132:50090 ,可以查看SecondaryNameNode 信息。
(2)YARN Web界面
在windows的浏览器中,输入网址:http://192.168.245.132:8088,可以查看集群所有应用程序的信息。
十二、测试Hadoop
通过一个MapReduce 程序测试Hadoop,统计 HDFS 中 /input/data.txt文件中单词出现的次数。
(1)在Ubuntu 操作系统的 ~ 目录下,创建一个文本文件 data.txt。文章来源:https://www.toymoban.com/news/detail-451883.html
cd ~
gedit data.txt
#在data.txt文件中输入如下内容(文字可自拟),保存并退出
Hello World
Hello Hadoop
(2)在HDFS创建 input 文件夹,命令如下。文章来源地址https://www.toymoban.com/news/detail-451883.html
hdfs dfs -mkdir /input
到了这里,关于Hadoop 环境配置的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!