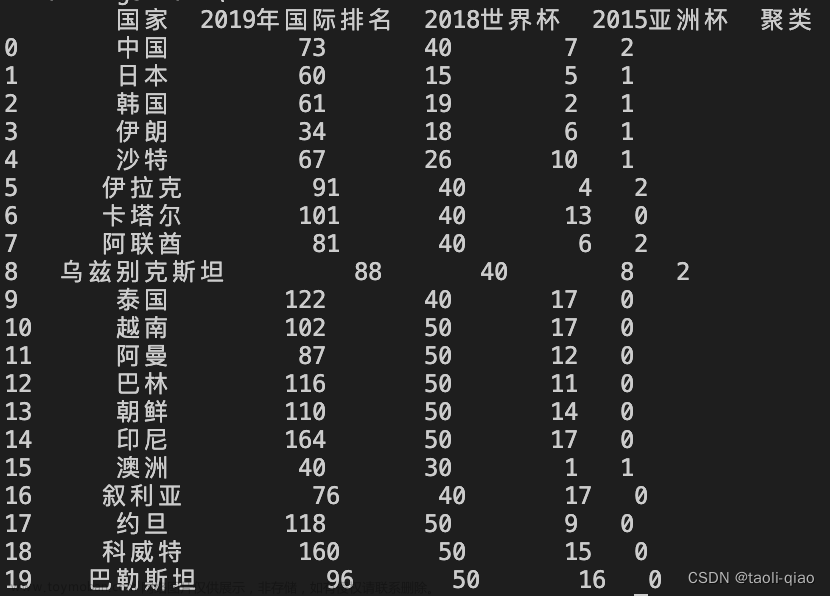
1.Kmeans简介
Kmeans算法是一个无监督机器学习算法。其基本作用就是将一堆杂乱、无序的数据归成类,是用户给定的数,它表示用户需要将数据分成个类。
2.Kmeans运算步骤
- 首先将总的数据集中随机挑选出个数据,作为将来个类对应的质心(相当于每个类对应的老大,将来每个类的所有点都将其包围)。
- 从头开始顺序遍历每一个数据,假如该数据是前面选出来的质心,则跳过直接遍历下一个数据;否则用个质心分别和该数据计算它们之间的距离,选出与该数据距离最近的质心,将该数据加到选出的质心对应的类,并更新该类的质心。
- 不断迭代执行第二个步骤,直至满足用户的需求。
3.Kmeans代码
(1)先导入所需要的库函数
from matplotlib import pyplot as plt
import random
import numpy as np
from math import sqrt(2)初始化一组数据(坐标点)
x_list=[random.randint(1,100) for i in range(50)]
y_list=[random.randint(1,100) for i in range(50)]
xy_axis=[]
for i in range(len(x_list)):
xy_axis.append([x_list[i],y_list[i]])
print(xy_axis)
xy_axis=np.array(xy_axis)(3)先可视化一下当前的点的分布
x=xy_axis[:,0]
y=xy_axis[:,1]
plt.scatter(x,y)
现在的数据是还没有经过分类的。
(4)定义距离函数
def eu_dis(x,y):
return sqrt((x[0]-y[0])**2+(x[1]-y[1])**2)(5)定义Kmeans算法
def Kmeans(xy_axis,k,time):
n=len(xy_axis)
center_list=[] # 存放质心的下标
cluster_center=[] # 存放质心坐标
cluster={} # 存放每个类包含的数据的坐标
for i in range(k):
cluster[i]=[]
center_list.append(random.randint(0,n-1))
cluster_center.append(xy_axis[center_list[i]])
# 迭代time次
for o in range(time):
for i in range(k):
cluster[i]=[]
# 遍历每一个数据
for i in range(n):
if i not in center_list:
min_dis=10000000
pos=-1
# 寻找最近的质心
for j in range(k):
dis=eu_dis(cluster_center[j],xy_axis[i])
if dis<min_dis:
min_dis=dis
pos=j
# 更新最近的质心的坐标
cluster_center[pos][0]=(cluster_center[pos][0]+xy_axis[i][0])/2
cluster_center[pos][1]=(cluster_center[pos][1]+xy_axis[i][1])/2
# 将该数据加入到该质心所在的类中
cluster[pos].append(i)
for i in range(k):
print(i,cluster[i])
# 数据可视化
x=xy_axis[:,0]
y=xy_axis[:,1]
plt.scatter([x[i] for i in cluster[0]],[y[j] for j in cluster[0]],c='b')
plt.scatter([x[i] for i in cluster[1]],[y[j] for j in cluster[1]],c='r')
plt.scatter([x[i] for i in cluster[2]],[y[j] for j in cluster[2]],c='y')
plt.show()(6)调用
Kmeans(xy_axis,3,10)结果
 文章来源:https://www.toymoban.com/news/detail-452047.html
文章来源:https://www.toymoban.com/news/detail-452047.html
这时可以看出数据已经分好类啦。文章来源地址https://www.toymoban.com/news/detail-452047.html
到了这里,关于Kmeans算法(附代码)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!