目录
1.深浅克隆问题
2.Mysql中可以代替左模糊或全查询的函数方法
3.开发时需注意,使用String类的equals()方法时,原则上需要左边的变量不能为null值,避免程序执行时出现空指针报错
4.Mysql Update的高效应用
5.Mysql Insert 的高效应用
6.在try-catch-finally代码块中return或者throw Exception时需注意的问题
7.索引过多导致查询的时间不稳定
8.JSON转化为带泛型的集合
9.当时使用Map集合需要在输出时变得有序,可以使用new LinkedHashMap()代替new HashMap()
10.关于使用String.valueOf()时需要关注的问题
11.Mysql高效新增同时更新重复数据
12.CaseInsensitiveMap应用,v>
13.获取List<对象>集合中对象某个字段的集合体,同时去重
14.@Builder注解用法
15.自定义线程池
16.@FeignClient在Application启动时抛出对象重复异常
17.新项目启动时依赖缺失问题
18.idea启动服务时报错Command line is too long
19.List<引用类型>集合排序
20.泛型方法使用
21.静态方法调用Mapper接口
22.Mysql中group by 和 limit 同时使用时注意事项:
23.stream流去重
24.Spring容器跳过指定对象初始化扫描
25. Spring自带的入参判空应用
26.时间戳与日期戳的处理
1.深浅克隆问题
在深浅克隆时一定要注意拷贝的内容如果是基本类型和String类型,还有Integer的-127~128范围可以直接用浅克隆(这些类型在虚拟机都有常量池保存,不会额外新增地址保存值);如果是其他的引用类型则需要使用深克隆来操作(深克隆操作这里不做文章,具体可以参考其他大佬的文章)
2.Mysql中可以代替左模糊或全查询的函数方法
- LOCATE('keyword',`field`,index)或者LOCATE('keyword',`field`)前者返回值=0时表示field中不存在keyword字符串,如果返回值>0表示存在,此外index表示key在field字段第index个字符开始起第一次出现的坐标值,后者使用的方法相似,只是返回值默认取第一次出现的坐标值;
例如:select 字段 from 表 where locate(‘检索的串’,字段名,检索起始位置可省略)>0
- POSITION('keyword' IN 'field')该函数的用法和LOCATE函数没有太大的差异,返回值也是一样的效果;
例如:select 字段 from 表 where position(‘检索的串’IN 字段名)>0
- INSTR(`field`, 'keyword') 该函数用法与①②是相近,返回值一样的效果;
例如:select 字段 from 表 where instr(字段名,‘检索的串’)>0
注意:以上三种函数需要在检索串的所在字段有创建索引情况下才能达到优化效果
3.开发时需注意,使用String类的equals()方法时,原则上需要左边的变量不能为null值,避免程序执行时出现空指针报错
例如:
①Field.equals(“str”)—这是错误的写法
②“str”.equals(Field)—正确的写法
③若两个比较的都是变量,则需提前为左边的变量做好判空处理
if(StringUtils.isEmpty(变量1){
throw e;
}
bollean flag = 变量1.equals(变量2);
4.Mysql Update的高效应用
当我们需要update的表字段关联的条件在其他时,可以这么操作:
Update 表1 别名1,表2 别名2 set 字段1=更新值 where 别名1.条件字段=别名2.条件字段 and 别名1.条件字段=条件值
或者先联查两个表再条件查询更新值
Update 表1 别名1 INNER(LEFT/RIGHT) JOIN 表2 别名2 ON 别名1.联查字段=别名2.联查字段Set 别名1.字段=值 , 别名2.字段=值 where 别名1.条件字段=值
5.Mysql Insert 的高效应用
Insert操作时除了可以利用foreach标签批量插入外,可以利用查询结果作为插入的values
例如:
INSERT INTO 表 (字段1,字段2…)SELECT 字段1,字段2… FROM 表 WHERE 条件1…
以上需要注意的是插入表的字段顺序,数据类型,字段名(别名也有效)必须与查询语句中的一致
当insert表字段与select的表字段名,类型一致时也可以简化为:INSERT INTO 表1 select * from 表2 where 条件1…
注意:这里更推荐使用前者指定字段,因为当表有更新字段时后者可能存在不匹配的情况\
6.在try-catch-finally代码块中return或者throw Exception时需注意的问题
如果三者中均存在return,那么执行的顺序会优先try里的运算表达式但不会马上返回值,而是优先走finally里面的运算表达式,这样try里return的值并不是开始想要的,而finally中return值是不生效的,而是走try或catch中的return值;此外try中出现异常的位置不同也会导致最终的结果不一样
注意**在finally代码块中永远不会只是throw Exception,但是可以是用try-catch代码结果补货异常后打印到日志中**
下面是一个简单的代码测试:
public class test{
public static void main(String[] args) {
int result = testMethod();
System.out.println(result);
//当异常x生效时,结果为5;当异常y生效时,结果为5;当x/y异常均不生效时,结果是4
}
private static int testMethod() {
int a = 0;
try {
int b = 1;
//int x = 1 / 0;//这里模拟出了异常
a = a + b;
//int y = 1 / 0;//这里模拟出了异常
return a;
} catch (Exception e) {
int c = 2;
a = a + c;
System.out.println("出问题了:" + e.getMessage());
return a;
} finally {
int d = 3;
a = a + d;
return a;
}
}
}7.索引过多导致查询的时间不稳定
当表中索引的数量很多,且explain查询语句时,发现某个表的可能索引有很多个,此时可以在表名后面增加一个force index(索引名)来强制走某一个索引,这样就可以节约的mysql在查询时增加检索索引的时间,提高性能,并且能稳定查询时间
例如:
select 字段 from 表名 force index(索引名) where 条件1 and 条件2 ...
8.JSON转化为带泛型的集合
引用类型<T> obj = JSON.parseObject(JSON.toJSONString(Object),new TypeReference<引用类型<T>>(){});
常用与JsonRespone<T>,PageResult<T>,Map<K,V> 这种类型的jsonString -> 对象
9.当时使用Map集合需要在输出时变得有序,可以使用new LinkedHashMap()代替new HashMap()
public class test {
public static void main(String[] args) {
Map<Integer, Object> map1 = new HashMap();
map1.put(7, "c");
map1.put(5, "a");
map1.put(6, "b");
System.out.println(map1);//输出结果不会按照key的put顺序输出而是一个随机顺序
Map<Integer, Object> map2 = new LinkedHashMap();
map2.put(3, "c");
map2.put(1, "a");
map2.put(2, "b");
System.out.println(map2);//输出结果会按照key的put顺序进行输出
}
}10.关于使用String.valueOf()时需要关注的问题
情况一:
String a = String.valueOf(null);
以上再运行时会抛出空指针异常
情况二:
Long b = null; String a = String.valueOf(b);
综上所述:代码在执行时并不会抛出空指针异常,但是会把null值转化为”null”字符串,从某种意义上会改变原有的代码逻辑
11.Mysql高效新增同时更新重复数据
INSERT INTO 表名 (字段1...) VALUES (值1...) ON DUPLICATE KEY UPDATE 字段1=values(字段1), 字段2=values(字段2);
注意:以上sql需要配合唯一索引使用,并且唯一索引设定有可能会存在冲突问题
12.CaseInsensitiveMap<k,v>应用
CaseInsensitiveMap<k,v>与常规的HashMap<k,v>不同的是,CaseInsensitiveMap的key值是不区分大小写的
13.获取List<对象>集合中对象某个字段的集合体,同时去重
集合对象.stream().map(对象别名(自定义即可)->别名.get字段).distinct().collect(Collectors.toList);
14.@Builder注解用法
在实体类上添加@Builder(toBuilder = true)注解,可以在创建对象时赋值或者重新对一个对象重新赋值,用法上类似@Accessors(chain = true)与链式加载,例如:
①创建新对象
引用类型 对象 = 引用类型.builder().属性1(value1).属性2(value2).build();
②重新赋值对象
对象.toBuilder().属性1(value1).属性2(value2).build();
15.自定义线程池
ThreadPoolExecutor(corePooSize,maximumPoolSize,keepAliveTime,unit,workQueue,threadFactory,handler);
参数说明:
1.corePoolSize -- 核心线程数
2.maxmunPoolSize -- 最大核心线程数
3.keepAliveTime -- 闲时线程最大存货时间
4.unit -- 单位(用于定义最大存活时间)
5.workQueue -- 队列规则
6.threadFactory -- 线程池工厂
7.handler -- 线程异常类型
16.@FeignClient在Application启动时抛出对象重复异常
当同一个服务下有多个feign对象配置了相同的value值(调用同一个服务名),正常情况下会因为对象创建冲突导致异常,这种时候有两种方法解决:
①在yml中配置(允许覆盖重名的对象创建,但是这样就可能不能实现feign的相互独立):
spring:
main:
allow-bean-definition-overriding: true
②在每个@FeignClient中添加contextId属性值,作为对象创建时的区分
17.新项目启动时依赖缺失问题
新项目中明明Maven已经正常下载完所有的依赖了,但是在启动服务时还是会出现依赖缺失等异常的问题?
这是因为spring在启动时会忽略pom.xml文件中带<scope>provided</scope>标签的依赖,最终导致依赖出现缺失的问题,解决方法:
①找到这些依赖并注释该标签内容,但需要注意某些项目在上线构建时并不需要这些依赖,所以在上线记得要把注释恢复回来
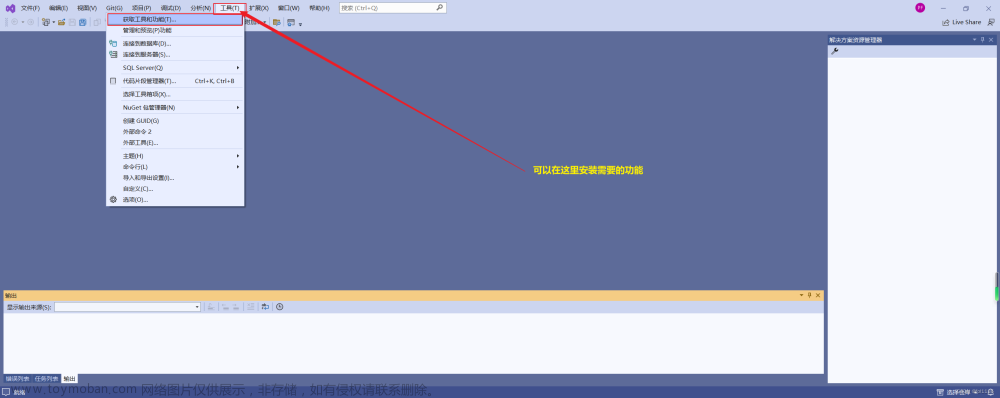
②(推荐)在idea的启动configurations配置中增加provideds属性配置如图:

18.idea启动服务时报错Command line is too long
idea启动时报错:Error running xxxxx. Command line is too long. Shorten the command line via JAR manifest or via a classpath file and rerun.
这里解决方法有两个:
①(推荐)在idea的启动configurations配置如图:

②在项目的.idea/workspace.xml文件中,找到<component name="PropertiesComponent">,后面在添加一行<property name="dynamic.classpath" value="true" />
19.List<引用类型>集合排序
//按照List中对象的字段属性升序
list.sort(Comparator.comparing(引用类型::get字段))
//按照List中对象的id属性降序
list.sort(Comparator.comparing(引用类型::get字段).reversed());
//多条件升序
list.sort(Comparator.comparing(引用类型::get字段1).thenComparing(引用类型::get字段2));
//id降序
list.sort(Comparator.comparing(引用类型::get字段1).reversed().thenComparing(引用类型::get字段2))
20.泛型方法使用
泛型方法的声明:
修饰符 <T> 返回值 方法名(参数...){...}
*注意<T>是表示当前方法是一个泛型方法,一般在修饰符和返回值中间进行声,明
21.静态方法调用Mapper接口
我们都知道静态方法只能调用静态资源,当静态方法中想调用Mapper接口时,我们是不能在Mapper前面添加static修饰的,那么想要调用Mapper就得换一个思路,Spring在实例化一个bean时会对这个bean中的属性进行赋值,既然Mapper无法成为静态资源那么我们就可以将这个工具类本身作为一个静态资源(对象)去调用,例如:
@Component
public class DemoUtils{
@Autowired
private XxMapper xxMapper;
private static DemoUtils demoUtils;
//自定义实例化
@PostConstruct
public void init() {
demoUtils = this;
demoUtils.xxMapper = this.xxMapper;
}
public static void method1(参数1){
//利用已实例化好的静态对象进行调用Mapper
demoUtils.xxMapper.xx方法(参数1);
}
}22.Mysql中group by 和 limit 同时使用时注意事项:
在Mysql中我们经常会使用group by对数据进行分组查询,但是有一种现象需要注意的,即当我们在查询时如果表的可能索引不是唯一的,且查询时join 联查的条件 和 where查询的条件使用的索引不一致,此时如果group by 的字段涉及到这个表时 ,我们在进行limit 分页查询那么可能会出现那么一种现象: group by 后加了limit 查询会很慢,这是因为group 和 limit 同时使用时会重新扫描sql上所有的关联表,最终即使limit 10条数据也会比原来的sql慢上许多;
解决方法:
①使用强制索引(硬核安心),如:
select * from t1 force index(xxx索引) left join t2 on xxx条件 where xxx条件 group by xx字段 limit 0,10
②group by 和 limit 隔离使用,即将原有的sql作为一个子查询再去limt 分页,如:
select * from (...含了group by的sql) limit 0,10
23.stream流去重
一个已知集合List<引用类型> A,根据A集合中的每个对象的特定字段作为唯一主键去重
①单字段去重
A.stream().collect(Collectors.toMap(引用类型::getXX字段,e->e)).values().stream().collect(Collectors.toList());
②多字段去重(通用型表达,只get一个字段相当于①的表达式效果)
A.stream().collect(Collectors.toMap(e->e.get字段1()+e.get字段2(),e->e)).values().stream().collect(Collectors.toList());
说明: toMap()里面有两段表达时,以","号分隔,第一段表示获取哪些字段作为主键去重,②中的e可以任意命名,表示A集合中的每个元素的变量名;第二段表示去重前的引用类型和去重后需要得到的内容,->e.get字段()可以指定某些字段
在使用流去重时还需要注意,当选取的唯一主键(单字段或多字段)不是一对一时,这个表达式编译时不会异常,但运行时会抛出Duplicate key...的异常,意思就是出现了一对多的关系不可以无法的到Map<k,v>的结构,解决方法:
方法一:
Collectors.toMap(...)改为Collectors.groupBy(e->e.get字段1()+get字段2()..),最终可获取到一个Map<k,List<T>>的结构,这样的话,去重数据时还要做一次遍历封装去重后的数据
方法二(推荐):
优化Collectors.toMap(e->e.get字段1()+get字段2()..,e->e,(key1,key2)->key1或key2),这里(key1,key2)是固定写法表示出现了重复数据,当表达式->key1时表示重复数据只保留前者,同理key2代表后者
24.Spring容器跳过指定对象初始化扫描
我们在分布式项目中经常都是建立子Maven工程集成于父级工程的pom.xml,但是在父级工程中会存在很多公共的依赖,而一些子级工程是不需要的,例如:MYBATIS的JDBC依赖,如果子级工程没有在在yml文件中声明数据库连接的配置,在启动spring容器时就会报错,此时我们又不想增加无用的配置在yml中,我们可以在这个子级的启动类的@SpringBootApplication注解上exclude={类名.class},即可跳过这些类的对象初始化
@SpringBootApplication(exclude = {DataSourceAutoConfiguration.class, DruidDataSourceAutoConfigure.class})
@EnableEurekaClient
public class ClientApplication {
public static void main(String[] args) {
SpringApplication.run(ClientApplication.class, args);
}
}
这里的DataSourceAutoConfiguration.class 和 DruidDataSourceAutoConfigure.class都是用于数据库连接的配置对象,不一定两个都需要跳过,具体看父级的依赖引入,这里就不做过多的解释了
25. Spring自带的入参判空应用
在实现接口时,我们经常都需要对某些关键入参进行判空,防止空指针异常的出现,但有些公共的入参都是同一个实体类并且关键入参字段都是一样的,我们在每个接口实现都写一次就会出现许多重复的代码,Spring框架就自带了@Valid 和 @Valided注解对入参中的实体类进行判空,以下是代码实现:
//实体类的代码
@Data
public class DemoDto{
@NotEmpty
private String name;
@NotNull
private Long id;
}这里在使用时需要注意数据类型
@NotEmpty表示 不能为空串和null值 ,一般用在字符串类型上
@NotNull表示 不能为空,任意的引用类型都可以使用
//控制层代码
@RestController
public class DemoController{
@PostMapping("/test/demo")
public JsonResponse testDemo(@Valid @RequestBody DemoDto param){
return JsonResponse.success("OK");
}
}这里需要注意@Valid 和 @Valided注解需要配合实体类上的注解一起使用,否则容器不知道这个实体类需要校验哪些字段为非空入参
26.时间戳与日期戳的处理
在Excel导入时,有时因为某些格式配置导致了日期类型的时间 会 序列成了 数字格式的 字符串,这种字符也是就是我们常见的时间戳,但是时间 也是有几种的,目前了解的场景有3中:
①5位数 这种是因为日期格式中只有年月日转化导致得到了一个天数,可以理解为日期戳,而日期戳的换算如下:
Date date = new Date();
Calendar calendar = Calendar.getInstance();
//获取日期偏移值
long localOffset = (calendar.get(Calendar.ZONE_OFFSET) + calendar.get(Calendar.DST_OFFSET)) / (60 * 1000); //系统时区偏移 1900/1/1 到 1970/1/1 的 25569 天
date.setTime(((Long.parseLong(val) - 25569) * 24 * 3600 * 1000 + localOffset));
//换算得成13位数的时间戳
long timestamp = date.getTime();
②10位数 这种格式一般是年月日时分秒,去到秒级的的时间戳,转化如下文章来源:https://www.toymoban.com/news/detail-452170.html
//10位时间戳
String timestamp = "1702632914";
Date date = new Date(Long.parseLong(timestamp)*1000);
//获取13位时间戳
long newTimestamp = date.getTime();③13位数 这种就是毫秒级别的时间戳,转换如下:文章来源地址https://www.toymoban.com/news/detail-452170.html
// 13位时间戳
long timestamp = 1634567890123L;
//时间格式化对象,可以自定义 时间表达式
SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
// 将13位时间戳转化为Date对象
Date date = new Date(timestamp);
//格式化的时间字符串
String dateTimeStr = sdf.format(date);
//注意:以上可以通过统一转为13位的时间戳得到正确的 格式化Date对象 或者 时间字符串到了这里,关于JAVA开发中常见问题的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!