1 修改 DataFrame 某一列的数据类型
问题描述:想要把 DataFrame 最后一列 label 的数据格式从 float改成int
原来:
代码:
bank2["label"] = bank2["label"].astype(int)
out:
2 读取和保存
读取时要注意的参数有 sep 等等。
# 读取
file_path = "./data/bank/"
bank = pd.read_csv(file_path + 'bank-full.csv',sep=';')
# 保存
bank.to_csv("bank.csv", index=False)
3 特定值的替换
data2 = data2.replace(' >50K.', ' >50K')
4 两个 DataFrame 的连接
在表头顺序一样的情况下,可以这样无脑连接两个 DataFrame :
data1 = pd.read_csv(file_path + 'adult.data', header=None)
data2 = pd.read_csv(file_path + 'adult.test',header=None)
adult = pd.concat([data1,data2])
有关 np.concat 的可以看:https://www.jb51.net/article/164905.htm
本文主要讲 np.merge() 。
但是如果两个 DataFrame 的表头不一样(顺序不一样或是部分feature不一样),则需要用到 np.merge(),并设置参数 join 和 join_axes 进行这样的连接。
np.merge(left, right, how='inner', on=None, left_on=None, right_on=None,
left_index=False, right_index=False, sort=True,
suffixes=('_x', '_y'), copy=True, indicator=False)
4.1 join
如果两个表头顺序不一样,修改参数 join='inner' ,即可,他会自动识别。
y_in
Out[9]:
label 1 probability ... 9 probability 5 probability
0 0 0.00000 ... 0.00000 0.00000
1 7 0.00000 ... 0.00002 0.00000
2 8 0.00000 ... 0.00615 0.00225
3 1 0.99926 ... 0.00000 0.00001
4 0 0.00000 ... 0.00000 0.00004
... ... ... ... ...
9995 9 0.00000 ... 0.97068 0.00000
9996 9 0.00007 ... 0.98485 0.00001
9997 5 0.00000 ... 0.00000 1.00000
9998 7 0.00000 ... 0.00011 0.00000
9999 0 0.00000 ... 0.00000 0.00000
[10000 rows x 11 columns]
y_out
Out[10]:
label 1 probability ... 8 probability 5 probability
0 1 0.90634 ... 0.05864 0.00175
1 2 0.00001 ... 0.00000 0.00001
2 6 0.00000 ... 0.00001 0.00002
3 0 0.00000 ... 0.00006 0.00011
4 6 0.00001 ... 0.00004 0.00004
... ... ... ... ...
9995 8 0.00000 ... 0.99915 0.00002
9996 0 0.00000 ... 0.00000 0.00000
9997 4 0.00040 ... 0.04294 0.00120
9998 2 0.00028 ... 0.00003 0.00000
9999 1 0.99788 ... 0.00115 0.00002
[10000 rows x 11 columns]
pd.concat([y_in, y_out], axis=0, join='inner')
Out[11]:
label 1 probability ... 9 probability 5 probability
0 0 0.00000 ... 0.00000 0.00000
1 7 0.00000 ... 0.00002 0.00000
2 8 0.00000 ... 0.00615 0.00225
3 1 0.99926 ... 0.00000 0.00001
4 0 0.00000 ... 0.00000 0.00004
... ... ... ... ...
9995 8 0.00000 ... 0.00000 0.00002
9996 0 0.00000 ... 0.00000 0.00000
9997 4 0.00040 ... 0.41741 0.00120
9998 2 0.00028 ... 0.00000 0.00000
9999 1 0.99788 ... 0.00000 0.00002
[20000 rows x 11 columns]
或者说我想横着拼接:
result = pd.concat([df1, df4], axis=1, join='inner')
out:
通过以下例子来区分 pd.concat & pd.merge 以及“inner” 和 “outer"参数的区别:
import pandas as pd
import numpy as np
random = np.random.RandomState(0) #随机数种子,相同种子下每次运行生成的随机数相同
df1=pd.DataFrame(random.randn(3,4),columns=['a','b','c','d'])
df1
Out[1]:
a b c d
0 1.764052 0.400157 0.978738 2.240893
1 1.867558 -0.977278 0.950088 -0.151357
2 -0.103219 0.410599 0.144044 1.454274
random = np.random.RandomState(0)
df2=pd.DataFrame(random.randn(2,3),columns=['b','d','a'],index=["a1","a2"])
df2
Out[2]:
b d a
a1 1.764052 0.400157 0.978738
a2 2.240893 1.867558 -0.977278
pd.concat([df1, df2], axis=0, join='inner')
Out[3]:
a b d
0 1.764052 0.400157 2.240893
1 1.867558 -0.977278 -0.151357
2 -0.103219 0.410599 1.454274
a1 0.978738 1.764052 0.400157
a2 -0.977278 2.240893 1.867558
pd.concat([df1, df2], axis=0, join='outer')
Out[4]:
a b c d
0 1.764052 0.400157 0.978738 2.240893
1 1.867558 -0.977278 0.950088 -0.151357
2 -0.103219 0.410599 0.144044 1.454274
a1 0.978738 1.764052 NaN 0.400157
a2 -0.977278 2.240893 NaN 1.867558
pd.merge(df1,df2,how="outer")
Out[7]:
a b c d
0 1.764052 0.400157 0.978738 2.240893
1 1.867558 -0.977278 0.950088 -0.151357
2 -0.103219 0.410599 0.144044 1.454274
3 0.978738 1.764052 NaN 0.400157
4 -0.977278 2.240893 NaN 1.867558
# 当没有两个表格没有重合的属性值时,会汇集成空表
pd.merge(df1,df2,how="inner")
Out[8]:
Empty DataFrame
Columns: [a, b, c, d]
Index: []
4.2 某列作为拼接的依据
如果以index 作为合并的标志:
pd.merge(df1,df2,how='left',left_index=True,right_on=True)
如果以某一列为“辨识列”,则需要用到 join_axes 参数。
pd.merge(df1,df4,how='outer',left_on=df1['df1的某一列'],right_on=df4['df4的某一列'])
5 删除某一列
5.1 删除第n列
例如删除第1列:
data = data.drop([1],axis=1)
5.2 删除特定名称列
例如删除名称为 label 的列:
data = data.drop(["label"],axis=1)
6 行、列重排
6.1列重排
当我得到这种dataframe 时:
我想要让列按照 [“0 probability”, “1 probability”, …, “membership”] 这样排,可以通过 dataframe.sort_index() 函数:
data.sort_index(axis=1)
out:
6.2 行重排
如果想根据index对所有行进行排序,则:
data.sort_index()
out:
6.3 根据某一列的值排序
如果我想根据 “1 probability” 列的值进行排序,,则需要用到 sort_values() 函数,代码如下:
data.sort_values(axis=0, by="1 probability")
out:
通过 ascending 参数可以决定排序是从大到小还是从小到大:
当然,这里的 by参数 也可以是一个列表,表示优先满足第一排序,在满足第二排序…
6.4 随机打乱所有行
train_data = train_data.reindex(np.random.permutation(train_data.index))
7 修改某列的名称
7.1 全局修改
dataframe.columns = [“a”, “b”, “c”, “d”, “e”]
示例:
7.2 局部修改
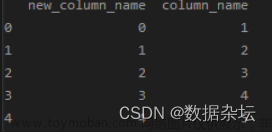
选定某几行或列的名称进行修改,我们采用 pandas.DataFrame.rename() 函数:
若要修改某几列的名称,通过 dataframe.rename(columns={"原名称":"修改后名称"})
若要修改某几行的名称,通过 dataframe.rename(index={"原名称":"修改后名称"})
示例: 文章来源:https://www.toymoban.com/news/detail-452172.html
文章来源:https://www.toymoban.com/news/detail-452172.html
参考:
https://blog.csdn.net/qq_41853758/article/details/83280104文章来源地址https://www.toymoban.com/news/detail-452172.html
到了这里,关于python-pandas用法大全的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!