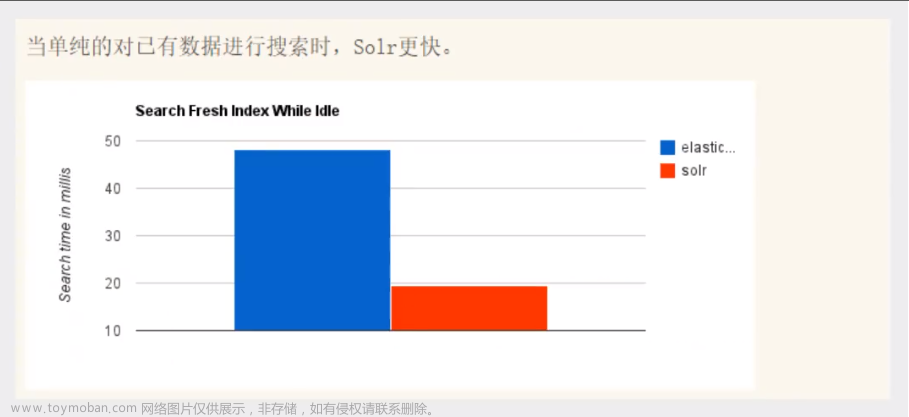
1. 简介
Elasticsearch 是一个分布式、高扩展、高实时的搜索与数据分析引擎。
它能很方便的使大量数据具有搜索、分析和探索的能力。充分利用Elasticsearch的水平伸缩性,能使数据在生产环境变得更有价值。
Elasticsearch 的实现原理主要分为以下几个步骤,首先用户将数据提交到Elasticsearch 数据库中,再通过分词控制器去将对应的语句分词,将其权重和分词结果一并存入数据,当用户搜索数据时候,再根据权重将结果排名,打分,再将返回结果呈现给用户。
2. 相关名词解析
2.1 数据分类
- 结构化数据:固定格式,有限长度
- 非结构化数据:不定长,无固定格式
- 半结构化数据:前两者结合,比如xml,html
2.2 搜索分类
- 结构化数据搜索:使用关系型数据库
- 非结构化数据搜索:顺序扫描、全文检索
2.3 全文检索
全文检索是指计算机索引程序通过扫描文章中的每一个词,对每一个词建立一个索引,指明该词在文章中出现的次数和位置,当用户查询时,检索程序就根据事先建立的索引进行查找,并将查找的结果反馈给用户的检索方式。这个过程类似于通过字典中的检索字表查字的过程。
2.4 倒排索引
倒排索引源于实际应用中需要根据属性的值来查找记录。这种索引表中的每一项都包括一个属性值和具有该属性值的各记录的地址。 由于不是由记录来确定属性值,而是由属性值来确定记录的位置,因而称为倒排索引(inverted index)。 带有倒排索引的文件我们称为倒排索引文件,简称倒排文件(inverted file)。
2.5 ElasticSearch的基本概念
2.5.1 索引(Index)
一个索引就是一个拥有几分相似特征的文档的集合。 比如说,可以有一个客户数据的索引,另一个产品目录的索引,还有一个订单数据的索引。
一个索引由一个名字来标识(必须全部是小写字母的),并且当我们要对对应于这个索引中的文档进行索引、搜索、更新和删除的时候,都要使用到这个名字。

2.5.2 文档(Document)
Elasticsearch是面向文档的,文档是所有可搜索数据的最小单位。
例:
- 日志文件中的日志项
- 一本电影的具体信息/一张唱片的详细信息
- MP3播放器里的一首歌/一篇PDF文档中的具体内容
文档会被序列化成JSON格式,保存在Elasticsearch中
特性:
- JSON对象由字段组成
- 每个字段都有对应的字段类型(字符串/数值/布尔/日期/二进
制/范围类型) - 每个文档都有一个Unique ID
- 一篇文档包含了一系列字段,类似数据库表中的一条记录
- JSON文档,格式灵活,不需要预先定义格式(字段的类型可以指定或者通过Elasticsearch自动推算、支持数组/支持嵌套)
文档元数据:文章来源:https://www.toymoban.com/news/detail-452296.html
 文章来源地址https://www.toymoban.com/news/detail-452296.html
文章来源地址https://www.toymoban.com/news/detail-452296.html
- _index:文档所属的索引名
- _type:文档所属的类型名
- _id:文档唯—ld
- _source: 文档的原始Json数据
- _version: 文档的版本号,修改删除操作_version都会自增1
- _seq_no: 和_version一样,一旦数据发生更改,数据也一直是累计的。Shard级别严格递增,保证后写入的Doc的_seq_no大于先写入的Doc的_seq_no
-
_primary_term: _primary_term主要是用来恢复数据时处理当多个文档的
_seq_no一样时的冲突,避免Primary Shard上的写入被覆盖。每当Primary Shard发生重新分配时,比如重启,Primary选举等,_primary_term会递增1
2.5.3 ElasticSearch和关系型数据库的对比
| 数据库 | — | — | — | — |
|---|---|---|---|---|
| 关系型数据库 | DataBase(数据库) | Table(表) | Row(行) | Column(列) |
| ElasticSearch | Index(索引) | Type(类型) | Document(文档) | Field(字段) |
3. ElasticSearch历代版本特性
3.1 5.x
- Lucene 6.x, 性能提升,默认打分机制从TF-IDF改为BM 25
- 支持Ingest节点/ Painless Scripting / Completion suggested / 原生的Java REST客户端
- Type标记成deprecated, 支持了Keyword的类型
- 性能优化:内部引擎移除了避免同一文档并发更新的竞争锁、Instant aggregation支持分片上聚合的缓存、新增了Profile API
3.2 6.x
- Lucene 7.x
- 新功能:跨集群复制(CCR)、索引生命周期管理、SQL的支持
- 更友好的的升级及数据迁移:在主要版本之间的迁移更为简化、全新的基于操作的数据复制框架,可加快恢复数据、有效存储稀疏字段的新方法,降低了存储成本、在索引时进行排序,可加快排序的查询性能
3.3 7.x
- Lucene 8.0
- 正式废除单个索引下多Type的支持
- 7.1开始,Security 功能免费使用
- ECK - Elasticseach Operator on Kubernetes
- 新功能:New Cluster coordination、Feature——Complete High Level REST Client、Script Score Query
- 性能优化:默认的Primary Shard数从5改为1,避免Over Sharding、 更快的Top K
3.4 8.x
- Rest API相比较7.x而言做了比较大的改动(比如彻底删除_type)
- 默认开启安全配置
- 存储空间优化:对倒排文件使用新的编码集,对于keyword、match_only_text、text类型字段有效
- 优化geo_point,geo_shape类型的索引(写入)效率
- 技术预览版KNN API发布,(K邻近算法),跟推荐系统、自然语言排名相关
到了这里,关于ElasticSearch(二)简介的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!