『机器学习』分享机器学习课程学习笔记,逐步讲述从简单的线性回归、逻辑回归到 ▪ 决策树算法 ▪ 朴素贝叶斯算法 ▪ 支持向量机算法 ▪ 随机森林算法 ▪ 人工神经网络算法 等算法的内容。
欢迎关注 『机器学习』 系列,持续更新中
欢迎关注 『机器学习』 系列,持续更新中
资源下载
拿来即用,所见即所得。
项目仓库:https://gitee.com/miao-zehao/machine-learning/tree/master
实现思路与核心函数解读
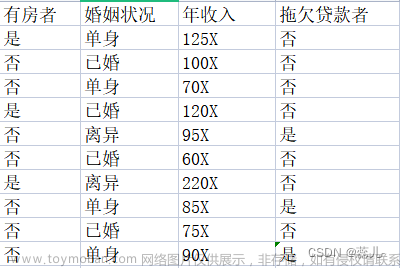
基于Python机器学习库sklearn.tree.DecisionTreeClassifier决策树分类模型,对鸢尾花数据集iris.csv建立决策树模型。
DecisionTreeClassifier分类决策树
sklearn.tree.DecisionTreeClassifier
创建一个决策树分类器模型实例:tree_model=DecisionTreeClassifier(criterion=“gini”,max_depth=3,random_state=0,splitter=“best”)
参数解读:
- 特征选择标准 criterion: string, 默认是 “gini”) 设置为‘gini’(基尼系数)或是‘entropy’(信息熵)
- 决策树最大深度 max_depth:int或None,可选(默认=None)树的最大深度。如果为 None,则扩展节点直到所有叶子都是纯的或直到所有叶子包含少于 min_samples_split 样本。
- 随机数生成器使用的种子 random_state:int,建议设置一个常数保证在研究参数时不会被随机数干扰。如果为 None,则随机数生成器是 RandomState 使用的实例np.random
- 拆分器 splitter:字符串,可选(默认=“最佳”)用于在每个节点处选择拆分的策略。默认是 default=”best”,或者是“random”
tree.plot_tree决策树可视化
sklearn.tree.plot_tree
创建一个决策树可视化实例:tree_model=DecisionTreeClassifier(criterion=“gini”,max_depth=3,random_state=0,splitter=“best”)
参数解读:
- 模型对象名
- feature_names 特征名称的列表
- class_names 分类名称的列表
ps:可能会遇到如下报错,这个时候更新
sklearn库到最新版本,报错就不会发生。

1. 对决策树最大深度的研究与可视化
将“决策树最大深度”分别设置为3和5建立决策树模型,并进行结果可视化,对比建模结果。
import matplotlib
import sklearn.tree
from sklearn.datasets import load_iris
# 导入决策树分类器
from sklearn.tree import DecisionTreeClassifier, plot_tree
# 导入分割数据集的方法
from sklearn.model_selection import train_test_split
# 导入科学计算包
import numpy as np
# 导入绘图库
import matplotlib.pyplot as plt
# 加载鸢尾花数据集
iris_dataset = load_iris()
# 分割训练集与测试集
X_train,X_test,y_train,y_test=train_test_split(iris_dataset['data'],iris_dataset['target'],test_size=0.2,random_state=0)
def Mytest_max_depth(my_max_depth):
# 创建决策时分类器-
tree_model=DecisionTreeClassifier(criterion="gini",max_depth=my_max_depth,random_state=0,splitter="best")
# - 特征选择标准 criterion: string, 默认是 “gini”) 设置为‘gini’(基尼系数)或是‘entropy’(信息熵)
# - 决策树最大深度 max_depth:int或None,可选(默认=None)树的最大深度。如果为 None,则扩展节点直到所有叶子都是纯的或直到所有叶子包含少于 min_samples_split 样本。
# - 随机数生成器使用的种子 random_state:int,建议设置一个常数保证在研究参数时不会被随机数干扰。如果为 None,则随机数生成器是 RandomState 使用的实例np.random
# - 拆分器 splitter:字符串,可选(默认=“最佳”)用于在每个节点处选择拆分的策略。默认是 default=”best”,或者是“random”
# 喂入数据
tree_model.fit(X_train,y_train)
# 打印模型评分
print("模型评分:{}".format(tree_model.score(X_test,y_test)))
# 随机生成一组数据使用我们的模型预测分类
X_iris_test=np.array([[1.0,3.4,1.5,0.2]])
# 用训练好的模型预测随机生成的样本数据的出的分类结果
predict_result=tree_model.predict(X_iris_test)
# 打印预测分类结果
print(predict_result)
print("分类结果:{}".format(iris_dataset['target_names'][predict_result]))
# 模型可视化
iris_feature_names=iris_dataset.feature_names#鸢尾花特征名列表 ['sepal length (cm)', 'sepal width (cm)', 'petal length (cm)', 'petal width (cm)']
iris_class_names=iris_dataset.target_names#鸢尾花分类类名列表 ['setosa' 'versicolor' 'virginica']
fig = plt.figure(figsize=(20, 12))#图片画布大小比例
matplotlib.rcParams['font.sans-serif'] = [u'SimHei'] # 用来设置字体样式以正常显示中文标签
matplotlib.rcParams['axes.unicode_minus'] = False # 设置为 Fasle 来解决负号的乱码问题
sklearn.tree.plot_tree(tree_model,feature_names=iris_feature_names, class_names=iris_class_names, rounded=True, filled= True, fontsize=14)
# 模型对象名
# feature_names 特征名称的列表
# class_names 分类名称的列表
plt.title("决策树最大深度={}的可视化图".format(my_max_depth))
plt.savefig("1/决策树最大深度={}的可视化图.png".format(my_max_depth))
plt.show()
Mytest_max_depth(3)
Mytest_max_depth(4)
Mytest_max_depth(5)
绘图结果
-
决策树最大深度=3的可视化图

-
决策树最大深度=4的可视化图

-
决策树最大深度=5的可视化图

分析
最大深度限制树的最大深度,超过设定深度的树枝全部剪掉。
高维度低样本量时效果比较好,但是决策树生长层数的增加会导致对样本量的需求会增加一倍,树深度较低是能够有效地限制过拟合。实际使用时,要逐步尝试,比如从3开始看看拟合的效果再决定是否增加设定深度。
2. 对特征选择标准的研究与可视化
将“特征选择标准”分别设置为‘gini’(基尼系数)和‘entropy’(信息熵)建立决策树模型,并进行结果可视化,对比建模结果;
import matplotlib
import sklearn.tree
from sklearn.datasets import load_iris
# 导入决策树分类器
from sklearn.tree import DecisionTreeClassifier, plot_tree
# 导入分割数据集的方法
from sklearn.model_selection import train_test_split
# 导入科学计算包
import numpy as np
# 导入绘图库
import matplotlib.pyplot as plt
# 加载鸢尾花数据集
iris_dataset = load_iris()
# 分割训练集与测试集
X_train,X_test,y_train,y_test=train_test_split(iris_dataset['data'],iris_dataset['target'],test_size=0.2,random_state=0)
def Mytest_criterion(my_criterion):
# 创建决策时分类器-
tree_model=DecisionTreeClassifier(criterion=my_criterion,max_depth=4,random_state=0,splitter="best")
# - 特征选择标准 criterion: string, 默认是 “gini”) 设置为‘gini’(基尼系数)或是‘entropy’(信息熵)
# - 决策树最大深度 max_depth:int或None,可选(默认=None)树的最大深度。如果为 None,则扩展节点直到所有叶子都是纯的或直到所有叶子包含少于 min_samples_split 样本。
# - 随机数生成器使用的种子 random_state:int,建议设置一个常数保证在研究参数时不会被随机数干扰。如果为 None,则随机数生成器是 RandomState 使用的实例np.random
# - 拆分器 splitter:字符串,可选(默认=“最佳”)用于在每个节点处选择拆分的策略。默认是 default=”best”,或者是“random”
# 喂入数据
tree_model.fit(X_train,y_train)
# 打印模型评分
print("模型评分:{}".format(tree_model.score(X_test,y_test)))
# 随机生成一组数据使用我们的模型预测分类
X_iris_test=np.array([[1.0,3.4,1.5,0.2]])
# 用训练好的模型预测随机生成的样本数据的出的分类结果
predict_result=tree_model.predict(X_iris_test)
# 打印预测分类结果
print(predict_result)
print("分类结果:{}".format(iris_dataset['target_names'][predict_result]))
# 模型可视化
iris_feature_names=iris_dataset.feature_names#鸢尾花特征名列表 ['sepal length (cm)', 'sepal width (cm)', 'petal length (cm)', 'petal width (cm)']
iris_class_names=iris_dataset.target_names#鸢尾花分类类名列表 ['setosa' 'versicolor' 'virginica']
fig = plt.figure(figsize=(20, 12))#图片画布大小比例
matplotlib.rcParams['font.sans-serif'] = [u'SimHei'] # 用来设置字体样式以正常显示中文标签
matplotlib.rcParams['axes.unicode_minus'] = False # 设置为 Fasle 来解决负号的乱码问题
sklearn.tree.plot_tree(tree_model,feature_names=iris_feature_names, class_names=iris_class_names, rounded=True, filled= True, fontsize=14)
# 模型对象名
# feature_names 特征名称的列表
# class_names 分类名称的列表
plt.title("决策树特征选择标准={}的可视化图".format(my_criterion))
plt.savefig("2/特征选择标准={}的可视化图.png".format(my_criterion))
plt.show()
Mytest_criterion("gini")#基尼系数
Mytest_criterion("entropy")#信息熵
绘图结果
- 特征选择标准=entropy的可视化图

- 特征选择标准=gini的可视化图

分析
-
从图上看到我们的两种特征选择标准实际上在这个鸢尾花数据集里对于分类的结果趋向一致。实际上因为在数学建模中经常使用熵权法,我一般比较喜欢信息熵ID3算法,所以着重讲讲信息熵。
-
信息熵:ID3算法—信息增益
信息增益是针对一个具体的特征而言的,某个特征的有无对于整个系统、集合的影响程度就可以用“信息增益”来描述。我们知道,经过一次 if-else 判别后,原来的类别集合就被被分裂成两个集合,而我们的目的是让其中一个集合的某一类别的“纯度”尽可能高,如果分裂后子集的纯度比原来集合的纯度要高,那就说明这是一次 if-else 划分是有效过的。通过比较使的“纯度”最高的那个划分条件,也就是我们要找的“最合适”的特征维度判别条件。
3. 对决策树其他参数的研究与可视化
尝试修改决策树模型中的其他参数进行建模,并对比建模结果。
import matplotlib
import sklearn.tree
from sklearn.datasets import load_iris
# 导入决策树分类器
from sklearn.tree import DecisionTreeClassifier, plot_tree
# 导入分割数据集的方法
from sklearn.model_selection import train_test_split
# 导入科学计算包
import numpy as np
# 导入绘图库
import matplotlib.pyplot as plt
# 加载鸢尾花数据集
iris_dataset = load_iris()
# 分割训练集与测试集
X_train,X_test,y_train,y_test=train_test_split(iris_dataset['data'],iris_dataset['target'],test_size=0.2,random_state=0)
def Mytest_splitter(my_splitter):
# 创建决策时分类器-
tree_model=DecisionTreeClassifier(criterion="entropy",max_depth=4,random_state=0,splitter=my_splitter)
# - 特征选择标准 criterion: string, 默认是 “gini”) 设置为‘gini’(基尼系数)或是‘entropy’(信息熵)
# - 决策树最大深度 max_depth:int或None,可选(默认=None)树的最大深度。如果为 None,则扩展节点直到所有叶子都是纯的或直到所有叶子包含少于 min_samples_split 样本。
# - 随机数生成器使用的种子 random_state:int,建议设置一个常数保证在研究参数时不会被随机数干扰。如果为 None,则随机数生成器是 RandomState 使用的实例np.random
# - 拆分器 splitter:字符串,可选(默认=“最佳”)用于在每个节点处选择拆分的策略。默认是 default=”best”,或者是“random”
# 喂入数据
tree_model.fit(X_train,y_train)
# 打印模型评分
print("模型评分:{}".format(tree_model.score(X_test,y_test)))
# 随机生成一组数据使用我们的模型预测分类
X_iris_test=np.array([[1.0,3.4,1.5,0.2]])
# 用训练好的模型预测随机生成的样本数据的出的分类结果
predict_result=tree_model.predict(X_iris_test)
# 打印预测分类结果
print(predict_result)
print("分类结果:{}".format(iris_dataset['target_names'][predict_result]))
# 模型可视化
iris_feature_names=iris_dataset.feature_names#鸢尾花特征名列表 ['sepal length (cm)', 'sepal width (cm)', 'petal length (cm)', 'petal width (cm)']
iris_class_names=iris_dataset.target_names#鸢尾花分类类名列表 ['setosa' 'versicolor' 'virginica']
fig = plt.figure(figsize=(20, 12))#图片画布大小比例
matplotlib.rcParams['font.sans-serif'] = [u'SimHei'] # 用来设置字体样式以正常显示中文标签
matplotlib.rcParams['axes.unicode_minus'] = False # 设置为 Fasle 来解决负号的乱码问题
sklearn.tree.plot_tree(tree_model,feature_names=iris_feature_names, class_names=iris_class_names, rounded=True, filled= True, fontsize=14)
# 模型对象名
# feature_names 特征名称的列表
# class_names 分类名称的列表
plt.title("决策树拆分器={}的可视化图".format(my_splitter))
plt.savefig("3/决策树拆分器={}的可视化图.png".format(my_splitter))
plt.show()
Mytest_splitter("best")#
Mytest_splitter("random")#
绘图结果
- 决策树拆分器=best的可视化图

- 决策树拆分器=random的可视化图

分析
在每个节点处选择拆分的策略,“best”与“random”这两种模式使得决策树有了很大的区别,实际上来拿个个决策树的最终分类效果相同,只是位置有些变动。
总结
决策树是一个预测模型;他代表的是对象属性与对象值之间的一种映射关系。树中每个节点表示某个对象,而每个分叉路径则代表的某个可能的属性值,而每个叶结点则对应从根节点到该叶节点所经历的路径所表示的对象的值。决策树仅有单一输出,若欲有复数输出,可以建立独立的决策树以处理不同输出。
我在高等数学建模大赛中经常使用熵权法(被指导老师dis为比较初级的方法,烂大街的方法)实际上这个就是决策树的基本原理,通过对属性进行分割,从而降低整体的混乱程度。即对一个属性的不同取值进行分组以后,每一组的混乱程度做个加权和,根据权重大小衡量属性的重要性。
大家喜欢的话,给个👍,点个关注!给大家分享更多有趣好玩的python机器学习知识!
版权声明:
发现你走远了@mzh原创作品,转载必须标注原文链接
Copyright 2022 mzh
Crated:2022-9-23文章来源:https://www.toymoban.com/news/detail-452396.html
欢迎关注 『机器学习』 系列,持续更新中
欢迎关注 『机器学习』 系列,持续更新中
【机器学习】01. 波士顿房价为例子学习线性回归
【机器学习】02. 使用sklearn库牛顿化、正则化的逻辑回归
【机器学习】03. 支持向量机SVM库进行可视化分类
【机器学习】04. 神经网络模型 MLPClassifier分类算法与MLPRegressor回归算法
【机器学习】05. 聚类分析
【机器学习】07. 决策树模型DecisionTreeClassifier
【机器学习】08. 深度学习CNN卷积神经网络keras库
【更多内容敬请期待】文章来源地址https://www.toymoban.com/news/detail-452396.html
到了这里,关于【机器学习】07. 决策树模型DecisionTreeClassifier(代码注释,思路推导)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!



![[可解释机器学习]Task07:LIME、shap代码实战](https://imgs.yssmx.com/Uploads/2024/01/411542-1.png)