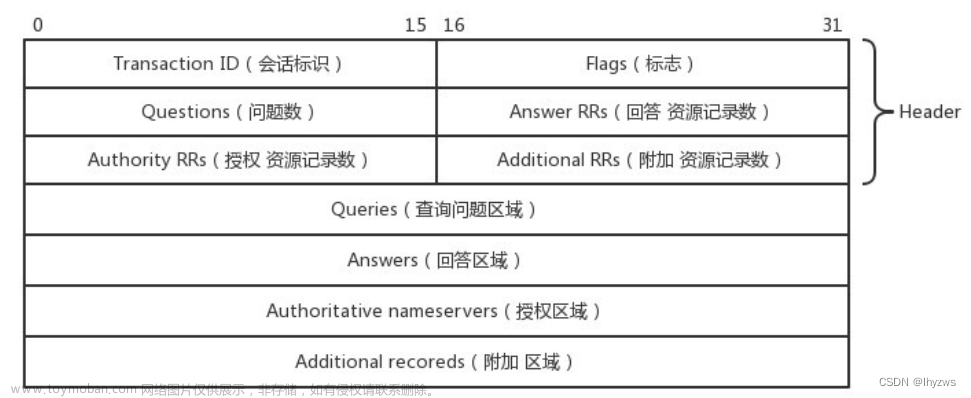
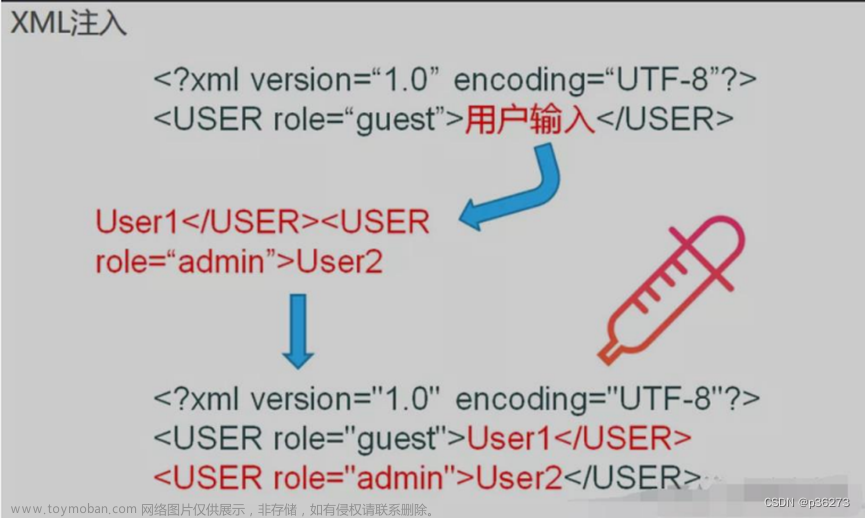
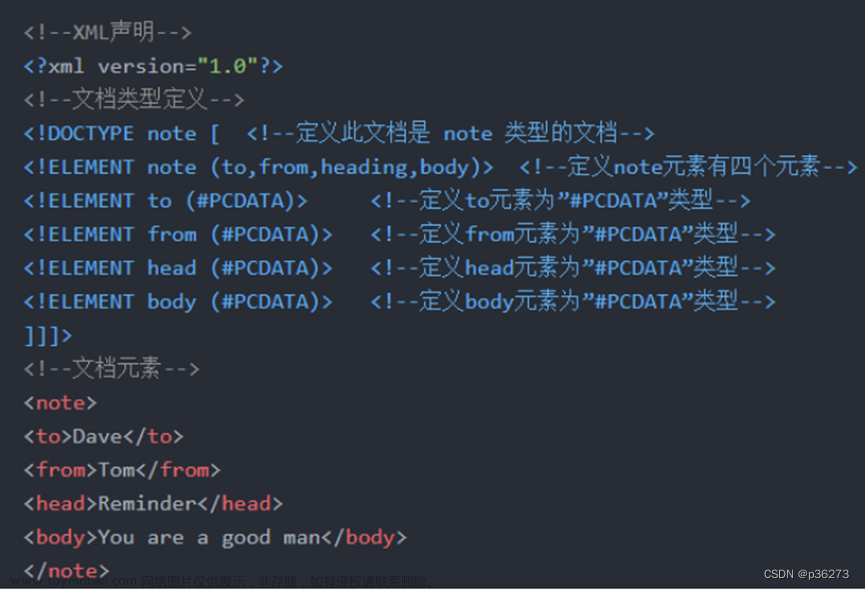
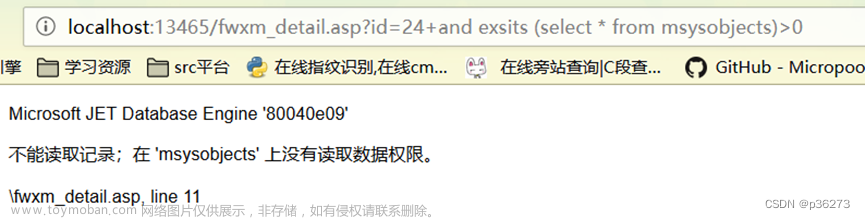
在Hadoop集群swarm部署的基础上,我们更进一步,把Spark也拉进来。相对来说,在Hadoop搞定的情况下,Spark就简单多了。
一、下载Spark
之所以把这件事还要拿出来讲……当然是因为掉过坑。我安装的时候,hadoop是3.3.5,所以spark下载这个为hadoop 3.3 预编译的版本就好——一定要把版本对准了。然而,这个版本实际是打包了hadoop环境的,spark还提供了不包含hadoop环境的预编译包,也就是所谓 user provide hadoop的版本。
由于我之前已经安装好了hadoop,所以为了避免jar包使用可能造成的冲突,我在spark大部分的配置完成的情况下又切换到了no hadoop版本。然后就是spark HA启动时,所有的master都处于standby状态。故障现场是懒得恢复了。总之,检查后发现是pignode没有办法连接上zookeeper。首先当然排除是网络及zookeeper的问题,因为hadoop HA工作正常。经过一番折腾,发现原因在spark访问zookeeper的方式,是通过curator封装的,然后这个curator在hadoop中似乎是没有提供的-或者版本不对,总之就是会出现java找不到函数的错误——java.lang.NoSuchMethodError。
估计是因为我选择的spark木有自带的java环境,而使用hadoop的java环境又没有spark想要的东西。总之一通折腾也没解决,最后还是换回包含hadoop环境的版本,就完美了。暂时也没发现又啥冲突的地方,就先用着吧。
二、Spark的配置文件
spark的配置要相对简单很多,要求不高的话,只需要配置一下全局环境变量,和spark-env.sh文件即可。
(一)全局环境变量
#定义SPARK_HOME环境变量,并把bin目录加到目录中,其实最好sbin也加进去的好,到处都会用到
RUN echo -e "export SPARK_HOME=/root/spark \nexport PATH=\$PATH:\$SPARK_HOME/bin">>/root/.bashrc\
#如果不定义如下LD_LIBRARY_PATH中的Java环境,在启动spark-shell的时候会出现警告,当然心大不搭理也可以
&& echo -e "export LD_LIBRARY_PATH=\$LD_LIBRARY_PATH:\$HADOOP_HOME/lib/native">>/root/.bashrc\
(二)spark配置项
在$SPARK_HOME/conf中的spark-env.conf文件中,定义如下配置项,主要就是数据存放目录,配置文件存放目录,和java类库之类的存放目录。
当然,对于HA部署,重要的时指定zookeeper的地址。如果不用HA模式的话,指定SPARK_MASTER_HOST就行。
#!/usr/bin/env bash
# Options read when launching programs locally with
# ./bin/run-example or ./bin/spark-submit
# - HADOOP_CONF_DIR, to point Spark towards Hadoop configuration files
#指向HADOOP的配置文件所在的目录
HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
# - SPARK_LOCAL_IP, to set the IP address Spark binds to on this node
# - SPARK_PUBLIC_DNS, to set the public dns name of the driver program
# Options read by executors and drivers running inside the cluster
# - SPARK_LOCAL_IP, to set the IP address Spark binds to on this node
# - SPARK_PUBLIC_DNS, to set the public DNS name of the driver program
# - SPARK_LOCAL_DIRS, storage directories to use on this node for shuffle and RDD data
#指向spark本地数据文件的存储地,因为我们使用容器,需要映射,所以把它定义出来
SPARK_LOCAL_DIRS=/sparkdata
# - MESOS_NATIVE_JAVA_LIBRARY, to point to your libmesos.so if you use Mesos
# Options read in any mode
# - SPARK_CONF_DIR, Alternate conf dir. (Default: ${SPARK_HOME}/conf)
# - SPARK_EXECUTOR_CORES, Number of cores for the executors (Default: 1).
# - SPARK_EXECUTOR_MEMORY, Memory per Executor (e.g. 1000M, 2G) (Default: 1G)
# - SPARK_DRIVER_MEMORY, Memory for Driver (e.g. 1000M, 2G) (Default: 1G)
# Options read in any cluster manager using HDFS
# - HADOOP_CONF_DIR, to point Spark towards Hadoop configuration files
# Options read in YARN client/cluster mode
# - YARN_CONF_DIR, to point Spark towards YARN configuration files when you use YARN
#指向YARN的配置文件所在目录,其实也就是Hadoop的配置文件目录
YARN_CONF_DIR=$HADOOP_HOME/etc/hadoop
# Options for the daemons used in the standalone deploy mode
# - SPARK_MASTER_HOST, to bind the master to a different IP address or hostname
# - SPARK_MASTER_PORT / SPARK_MASTER_WEBUI_PORT, to use non-default ports for the master
# - SPARK_MASTER_OPTS, to set config properties only for the master (e.g. "-Dx=y")
# - SPARK_WORKER_CORES, to set the number of cores to use on this machine
# - SPARK_WORKER_MEMORY, to set how much total memory workers have to give executors (e.g. 1000m, 2g)
# - SPARK_WORKER_PORT / SPARK_WORKER_WEBUI_PORT, to use non-default ports for the worker
# - SPARK_WORKER_DIR, to set the working directory of worker processes
# - SPARK_WORKER_OPTS, to set config properties only for the worker (e.g. "-Dx=y")
# - SPARK_DAEMON_MEMORY, to allocate to the master, worker and history server themselves (default: 1g).
# - SPARK_HISTORY_OPTS, to set config properties only for the history server (e.g. "-Dx=y")
# - SPARK_SHUFFLE_OPTS, to set config properties only for the external shuffle service (e.g. "-Dx=y")
# - SPARK_DAEMON_JAVA_OPTS, to set config properties for all daemons (e.g. "-Dx=y")
# - SPARK_DAEMON_CLASSPATH, to set the classpath for all daemons
# - SPARK_PUBLIC_DNS, to set the public dns name of the master or workers
# 该参数用来定义spark HA。只需要将zookeeper.url指向我们自己的zookeeper集群地址就好
SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=zookeeper1:2181,zookeeper2:2181,zookeeper3:2181 -Dspark.deploy.zookeeper.dir=/spark"
# Options for launcher
# - SPARK_LAUNCHER_OPTS, to set config properties and Java options for the launcher (e.g. "-Dx=y")
# Generic options for the daemons used in the standalone deploy mode
# - SPARK_CONF_DIR Alternate conf dir. (Default: ${SPARK_HOME}/conf)
# - SPARK_LOG_DIR Where log files are stored. (Default: ${SPARK_HOME}/logs)
# - SPARK_LOG_MAX_FILES Max log files of Spark daemons can rotate to. Default is 5.
# - SPARK_PID_DIR Where the pid file is stored. (Default: /tmp)
# - SPARK_IDENT_STRING A string representing this instance of spark. (Default: $USER)
# - SPARK_NICENESS The scheduling priority for daemons. (Default: 0)
# - SPARK_NO_DAEMONIZE Run the proposed command in the foreground. It will not output a PID file.
# Options for native BLAS, like Intel MKL, OpenBLAS, and so on.
# You might get better performance to enable these options if using native BLAS (see SPARK-21305).
# - MKL_NUM_THREADS=1 Disable multi-threading of Intel MKL
# - OPENBLAS_NUM_THREADS=1 Disable multi-threading of OpenBLAS
# Options for beeline
# - SPARK_BEELINE_OPTS, to set config properties only for the beeline cli (e.g. "-Dx=y")
# - SPARK_BEELINE_MEMORY, Memory for beeline (e.g. 1000M, 2G) (Default: 1G)
#这个参数在使用no hadoop版本的spark时会用到,也就是会造成curator找不到函数的地方
#export SPARK_DIST_CLASSPATH=$($HADOOP_HOME/bin/hadoop classpath)
三、Dockerfile文件
由于所有的工作都建立在前面已经构建好的pig/hadoop:ha镜像的基础上:CENTO OS上的网络安全工具(二十一)Hadoop HA swarm容器化集群部署,所以也就没啥多说的,贴吧:
FROM pig/hadoop:ha
#将spark安装包释放到容器中,并修改一个好用的名字
#PS:所谓改名,到后面出问题的时候感觉其实不改更好,能够更直观的看到版本号
ADD spark-3.4.0-bin-hadoop3.tgz /root
RUN mv /root/spark-3.4.0-bin-hadoop3 /root/spark
#设置Spark的全局变量
RUN echo -e "export SPARK_HOME=/root/spark \nexport PATH=\$PATH:\$SPARK_HOME/bin">>/root/.bashrc
RUN echo -e "export LD_LIBRARY_PATH=\$LD_LIBRARY_PATH:\$HADOOP_HOME/lib/native">>/root/.bashrc
#离线安装python3,离线方法就不多赘述了,把所有rpm整下来,一把yum localinstall了
COPY ./pythonrpm /root/pythonrpm
RUN yum localinstall -y /root/pythonrpm/*.rpm \
&& rm -rf /root/pythonrpm
#拷贝初始化脚本,后来为了方便修改调试起见,改成了映射的版本
COPY ./init-spark.sh /root/.
##默认启动脚本
CMD ["/root/init-spark.sh"]
四、初始化脚本
#! /bin/bash
# NODE_COUT和ZOOKEEPER_COUNT两个参数通过swarm config yml文件设置(只在第一个节点有用,用于判断是否所有节点都联通), 在yml文件中的endpoint_environment标识中定义。
NODECOUNT=$NODE_COUNT
TRYLOOP=50
ZOOKEEPERNODECOUNT=$ZOOKEEPER_COUNT
############################################################################################################
## 1. 使全局变量生效
############################################################################################################
source /etc/profile
source /root/.bashrc
############################################################################################################
## 2. 启动所有节点的SSH服务,其实也可以直接调用pig/hadoop:ha中的init-hadoop.sh
,不过我们都快写完了才反应过来############################################################################################################
/sbin/sshd -D &
############################################################################################################
## 3. 内部函数定义
############################################################################################################
#FUNCTION:PING 测试是否所有节点都已经上线准备好------------------------------------------------------------
#param1: node's hostname prefix
#param2: node count
#param3: how many times the manager node try connect
isAllNodesConnected(){
PIGNODE_PRENAME=$1
PIGNODE_COUNT=$2
TRYLOOP_COUNT=$3
tryloop=0
ind=1
#init pignode hostname array,and pignode status array
while(( $ind <= $PIGNODE_COUNT ))
do
pignodes[$ind]="$PIGNODE_PRENAME$ind"
pignodes_stat[$ind]=0
let "ind++"
done
#check wether all the pignodes can be connected
noactivecount=$PIGNODE_COUNT
while(( $noactivecount > 0 ))
do
noactivecount=$PIGNODE_COUNT
ind=1
while(( $ind <= $PIGNODE_COUNT ))
do
if (( ${pignodes_stat[$ind]}==0 ))
then
ping -c 1 ${pignodes[$ind]} > /dev/null
if (($?==0))
then
pignodes_stat[$ind]=1
let "noactivecount-=1"
echo "Try to connect ${pignodes[$ind]}:successed." >>init.log
else
echo "Try to connect ${pignodes[$ind]}: failed." >>init.log
fi
else
let "noactivecount-=1"
fi
let "ind++"
done
if (( ${noactivecount}>0 ))
then
let "tryloop++"
if (($tryloop>$TRYLOOP_COUNT))
then
echo "ERROR Tried ${TRYLOOP_COUNT} loops. ${noactivecount} nodes failed, exit." >>init.log
break;
fi
echo "${noactivecount} left for ${PIGNODE_COUNT} nodes not connected, waiting for next try">>init.log
sleep 5
else
echo "All nodes are connected.">>init.log
fi
done
return $noactivecount
}
#----------------------------------------------------------------------------------------------------------
#FUNCTION:从配置文件中读取Hadoop的数据文件目录,用于判断节点是否已经格式化--------------------------------------------------------------------
getDataDirectory(){
#when use tmp data directory
# configfiledir=`echo "${HADOOP_HOME}/etc/hadoop/core-site.xml"`
# datadir=`cat ${configfiledir} | grep -A 2 'hadoop.tmp.dir' | grep '<value>' | sed 's/^[[:blank:]]*<value>//g' | sed 's/<\/value>$//g'`
# echo $datadir
#when use namenode.name.dir direcotry
datadir=`cat ${HADOOP_HOME}/etc/hadoop/hdfs-site.xml|grep -A 2 "dfs.namenode.name.dir"|grep "<value>"|sed -e "s/<value>//g"|sed -e "s/<\/value>//g"`
echo $datadir
}
#---------------------------------------------------------------------------------------------------------
#FUNCTION:如果DFS文件系统尚未格式化,启用格式化的初始化流程.------------------------------------------------------------
initHadoop_format(){
#首先需要启动Journalnode,提供名字服务器同步元数据的通道
echo 'start all Journalnode' >> init.log
journallist=`cat $HADOOP_HOME/etc/hadoop/hdfs-site.xml |grep -A 2 'dfs.namenode.shared.edits.dir'|grep '<value>'|sed -e "s/<value>qjournal:\/\/\(.*\)\/.*<\/value>/\1/g"|sed "s/;/ /g"|sed -e "s/:[[:digit:]]\{2,5\}/ /g"`
for journalnode in $journallist;do
ssh root@${journalnode} "hdfs --daemon start journalnode"
done
#等待15秒,之前没有等,容易导致journalnode还未打开端口就开始格式化,导致格式化失败,浪费一个周六……
echo 'waiting 15 seconds for journal nodes started. or format will fail as journalnode can not be connected.'>>init.log
wait 15s
echo 'format and start namenode 1'>>init.log
hdfs namenode -format
if (( $?!=0 )); then
echo 'format namenode 1 error'>>init.log
return 1
fi
#启动主节点上的名字服务器(一共3个,启动第1个)
wait 3s
hdfs --daemon start namenode
if (( $?!=0 )); then
echo 'start namenode 1 error'>>init.log
return 1
fi
#必须等第1个名字服务器启动了,才能将其上的数据向其它名字服务器同步
echo 'sync and start others.'>>init.log
wait 3s
dosyncid=2
while (($dosyncid<=3));do
#依次同步2、3号名字服务器
ssh root@$nodehostnameprefix$dosyncid "hdfs namenode -bootstrapStandby"
if (( $?!=0 )); then
echo 'namenode bootstrap standby error'>>init.log
return 1
fi
#同步完成及时启动
ssh root@$nodehostnameprefix$dosyncid "hdfs --daemon start namenode"
if (( $?!=0 )); then
echo 'other namenodes start error'>>init.log
return 1
fi
let "dosyncid++"
done
wait 3s
#格式化zookeeper上的目录,在没启动这一步时,所有的hadoop节点都是standby
hdfs zkfc -formatZK
return 0
}
#---------------------------------------------------------------------------------------------------------
#FUNCTION:如果DFS已经格式化,只需要启动各类服务就行-----------------------------------------------------------------
initHadoop_noformat(){
#直接启动所有与dfs有关的服务,基于官方脚本可以启动所有节点上的hdfs服务
echo 'name node formatted. go on to start dfs related nodes and service'>>init.log
sbin/start-dfs.sh
if (( $?!=0 )); then
echo 'start dfs error'>>init.log
return 1
fi
#直接启动所有与yarn有关的服务,基于官方脚本可以启动所有节点上的yarn服务
wait 5s
echo 'start yarn resourcemanager and node manager'>>init.log
sbin/start-yarn.sh
if (( $?!=0 )); then
echo 'start yarn error'>>init.log
return 1
fi
#获取history server节点hostname,远程启动history server
wait 3s
echo 'start mapreduce history server'>>init.log
historyservernode=`cat $HADOOP_HOME/etc/hadoop/mapred-site.xml |grep -A 2 'mapreduce.jobhistory.address'|grep '<value>' |sed -e "s/^.*<value>//g"|sed -e "s/<\/value>//g"|sed -e "s/:[[:digit:]]*//g"`
ssh root@$historyservernode "mapred --daemon start historyserver"
if (( $?!=0 )); then
echo 'start mapreduce history server error'>>init.log
return 1
fi
return 0
}
#----------------------------------------------------------------------------------------------------------
#FUNCTION:退出初始化程序,使用挂住线程的方法,防止swarm shutdown--------------------------------------------------------------------------------
exitinit()
{
tail -f /dev/null
}
#----------------------------------------------------------------------------------------------------------
############################################################################################################
## 节点初始化程序 ##
############################################################################################################
#获取节点hostname,hostname的前缀和节点序号
#这里刚开始没有考虑好,应该直接从配置文件中获取相应角色的hostname,可以使程序更健壮些
#以后有时间再迭代吧,先这么着了
nodehostname=`hostname`
nodehostnameprefix=`echo $nodehostname|sed -e 's|[[:digit:]]\+$||g'`
nodeindex=`hostname | sed "s/${nodehostnameprefix}//g"`
#从配置文件中获取zookeeper集群hostname前缀,从yarn-site.xml,用来调用测试是否所有节点上线的函数
zookeepernameprefix=`cat ${HADOOP_HOME}/etc/hadoop/yarn-site.xml |grep -A 2 '<name>yarn.resourcemanager.zk-address</name>'|grep '<value>'|sed -e "s/[[:blank:]]\+<value>\([[:alpha:]]\+\)[[:digit:]]\+:.*/\1/g"`
#1.切换到工作目录下.
cd $HADOOP_HOME
#如果节点总数低于3则无法启动HA模式,所以低于3的情况什么也不做,直接退出
if (($NODECOUNT<=3));then
echo "Nodes count must more than 3.">>init.log
exitinit
fi
#如果不是第一个节点,则等待可能的初始化过程5分钟;如果是节点错误后被swarm重新启动
#则,等待5分钟后自行调用start-dfs.sh start-yarn.sh start-master.sh start-worker.sh脚本
#依靠官方脚本,可以确保及时服务被主节点启动过,也不会因为重复启动出现错误
if (($nodeindex!=1));then
echo $nodehostname waiting for init...>>init.log
sleep 5m
cd $HADOOP_HOME
echo "try to start dfs and yarn again.">>init.log
sbin/start-dfs.sh
sbin/start-yarn.sh
if (($nodeindex==3));then
echo "try to start historyserver again">>init.log
mapred --daemon start historyserver
fi
#判断是否前3个节点,如果是前3个节点,启动master,否则启动worker
echo "try to start spark again">>init.log
if (($nodeindex>3));then
$SPARK_HOME/sbin/start-worker.sh
else
$SPARK_HOME/sbin/start-master.sh
fi
exitinit
fi
#2.如果是主节点,则需要考虑进行格式化初始化,及所有节点的初始化
# 事实上,可以在各子节点上采取循环启动服务的方式,隔一段时间启动依次服务,直到主节点初始化完,各节点上服务能够随之启动成功为止
# 这里实现比较复杂,完全依靠主节点进行集群初始化,造成从节点重复启动服务,不太漂亮,以后再改吧
echo $nodehostname is the init manager nodes...>>init.log
# 等待所有节点和ZOOKEEPER集群都连接上
isAllNodesConnected $nodehostnameprefix $NODECOUNT $TRYLOOP
isHadoopOK=$?
isAllNodesConnected $zookeepernameprefix $ZOOKEEPERNODECOUNT $TRYLOOP
isZookeeperOK=$?
# 如果连接失败则退出
if ([ $isHadoopOK != 0 ] || [ $isZookeeperOK != 0 ]);then
echo "Not all the host nodes or not all the zookeeper nodes actived. exit 1">>init.log
exitinit
fi
#3. 判断DFS是否已经格式化,通过获取DFS目录并ls目录中是否有文件的方式
datadirectory=`echo $(getDataDirectory)`
if [ $datadirectory ];then
datadircontent=`ls -A ${datadirectory}`
if [ -z $datadircontent ];then
echo "dfs is not formatted.">>init.log
isDfsFormat=0
else
echo "dfs is already formatted.">>init.log
isDfsFormat=1
fi
else
echo "ERROR:Can not get hadoop tmp data directory.init can not be done. ">>init.log
exitinit
fi
#4. 如果没有格式化,则需要先格式化,和HA同步等操作
if (( $isDfsFormat == 0 ));then
initHadoop_format
fi
if (( $? != 0 ));then
echo "ERROR:Init Hadoop interruptted...">>init.log
exitinit
fi
#5. 格式化完成后启动dfs,yarn和history server
initHadoop_noformat
if (( $? != 0 ));then
echo "ERROR:Init Hadoop interruptted...">>init.log
exitinit
fi
echo "hadoop init work has been done. spark init start.">>init.log
#5. 启动spark,不要使用start-all.sh,因为使用了HA模式,SPARK_MASTER_HOST没有设置,spark并不知到谁是master,使用start-all.sh会将所有节点当作master启动。采用脚本仅启动前3个节点作为master;其余使用start-workers.sh脚本启动。
echo "start masters">>init.log
$SPARK_HOME/sbin/start-master.sh
masterindex=2
while (( ${masterindex} <= 3 ));do
echo "ssh root@${nodehostnameprefix}${masterindex} '$SPARK_HOME/sbin/start-master.sh'">>init.log
ssh root@${nodehostnameprefix}${masterindex} '$SPARK_HOME/sbin/start-master.sh'
let "masterindex++"
done
$SPARK_HOME/sbin/start-workers.sh
if (( $? != 0 ));then
echo "ERROR:Init spark interruptted...">>init.log
exitinit
fi
echo "spark init work has been done.">>init.log
tail -f /dev/null
五、docker-compose.yml文件
version: "3.7"
services:
pignode1:
image: pig/spark
deploy:
endpoint_mode: dnsrr
restart_policy:
condition: on-failure
placement:
constraints:
- node.hostname==pighost1
hostname: pignode1
environment:
- NODE_COUNT=12
- ZOOKEEPER_COUNT=3
networks:
- pig
ports:
- target: 22
published: 9011
protocol: tcp
mode: host
- target: 9000
published: 9000
protocol: tcp
mode: host
- target: 9870
published: 9870
protocol: tcp
mode: host
- target: 8088
published: 8088
protocol: tcp
mode: host
- target: 8080
published: 8080
protocol: tcp
mode: host
- target: 4040
published: 4040
protocol: tcp
mode: host
- target: 7077
published: 7077
protocol: tcp
mode: host
volumes:
# 映射xml配置文件
- ./config/core-site.xml:/root/hadoop/etc/hadoop/core-site.xml:r
- ./config/hdfs-site.xml:/root/hadoop/etc/hadoop/hdfs-site.xml:r
- ./config/yarn-site.xml:/root/hadoop/etc/hadoop/yarn-site.xml:r
- ./config/mapred-site.xml:/root/hadoop/etc/hadoop/mapred-site.xml:r
# 映射workers文件
- ./config/workers:/root/hadoop/etc/hadoop/workers:r
# 映射spark配置文件
- ./sparkconf/spark-env.sh:/root/spark/conf/spark-env.sh:r
- ./sparkconf/spark-defaults.conf:/root/spark/conf/spark-defaults.conf:r
- ./sparkconf/workers:/root/spark/conf/workers:r
# 映射数据目录
- /hadoopdata/1:/hadoopdata:wr
- /sparkdata/1:/sparkdata:wr
# 映射初始化脚本
- ./init-spark.sh:/root/init-spark.sh:r
pignode2:
image: pig/spark
deploy:
endpoint_mode: dnsrr
restart_policy:
condition: on-failure
placement:
# 将Second Namenode限制部署在第二个节点上
constraints:
- node.hostname==pighost2
networks:
- pig
hostname: pignode2
ports:
# 第二名字服务器接口
- target: 22
published: 9012
protocol: tcp
mode: host
- target: 9890
published: 9890
protocol: tcp
mode: host
- target: 9870
published: 9871
protocol: tcp
mode: host
- target: 8088
published: 8089
protocol: tcp
mode: host
- target: 8080
published: 8081
protocol: tcp
mode: host
- target: 4040
published: 4041
protocol: tcp
mode: host
- target: 7077
published: 7078
protocol: tcp
mode: host
volumes:
# 映射xml配置文件
- ./config/core-site.xml:/root/hadoop/etc/hadoop/core-site.xml:r
- ./config/hdfs-site.xml:/root/hadoop/etc/hadoop/hdfs-site.xml:r
- ./config/yarn-site.xml:/root/hadoop/etc/hadoop/yarn-site.xml:r
- ./config/mapred-site.xml:/root/hadoop/etc/hadoop/mapred-site.xml:r
# 映射workers文件
- ./config/workers:/root/hadoop/etc/hadoop/workers:r
# 映射spark配置文件
- ./sparkconf/spark-env.sh:/root/spark/conf/spark-env.sh:r
- ./sparkconf/spark-defaults.conf:/root/spark/conf/spark-defaults.conf:r
- ./sparkconf/workers:/root/spark/conf/workers:r
# 映射数据目录
- /hadoopdata/2:/hadoopdata:wr
- /sparkdata/2:/sparkdata:wr
# 映射初始化脚本
- ./init-spark.sh:/root/init-spark.sh:r
pignode3:
image: pig/spark
deploy:
endpoint_mode: dnsrr
restart_policy:
condition: on-failure
placement:
# 将Mapreduce限制部署在第三个节点上
constraints:
- node.hostname==pighost3
networks:
- pig
hostname: pignode3
ports:
- target: 22
published: 9013
protocol: tcp
mode: host
- target: 9870
published: 9872
protocol: tcp
mode: host
- target: 8088
published: 8087
protocol: tcp
mode: host
- target: 8090
published: 8090
protocol: tcp
mode: host
- target: 10020
published: 10020
protocol: tcp
mode: host
- target: 19888
published: 19888
protocol: tcp
mode: host
- target: 8080
published: 8082
protocol: tcp
mode: host
- target: 4040
published: 4042
protocol: tcp
mode: host
- target: 7077
published: 7079
protocol: tcp
mode: host
volumes:
# 映射xml配置文件
- ./config/core-site.xml:/root/hadoop/etc/hadoop/core-site.xml:r
- ./config/hdfs-site.xml:/root/hadoop/etc/hadoop/hdfs-site.xml:r
- ./config/yarn-site.xml:/root/hadoop/etc/hadoop/yarn-site.xml:r
- ./config/mapred-site.xml:/root/hadoop/etc/hadoop/mapred-site.xml:r
# 映射workers文件
- ./config/workers:/root/hadoop/etc/hadoop/workers:r
# 映射spark配置文件
- ./sparkconf/spark-env.sh:/root/spark/conf/spark-env.sh:r
- ./sparkconf/spark-defaults.conf:/root/spark/conf/spark-defaults.conf:r
- ./sparkconf/workers:/root/spark/conf/workers:r
# 映射数据目录
- /hadoopdata/3:/hadoopdata:wr
- /sparkdata/3:/sparkdata:wr
# 映射初始化脚本
- ./init-spark.sh:/root/init-spark.sh:r
#------------------------------------------------------------------------------------------------
#以下均为工作节点,可在除leader以外的主机上部署
pignode4:
image: pig/spark
deploy:
endpoint_mode: dnsrr
restart_policy:
condition: on-failure
placement:
# 将Mapreduce限制部署在第三个节点上
constraints:
# node.role==manager
# node.role==worker
- node.hostname==pighost3
networks:
- pig
ports:
- target: 22
published: 9014
protocol: tcp
mode: host
hostname: pignode4
volumes:
# 映射xml配置文件
- ./config/core-site.xml:/root/hadoop/etc/hadoop/core-site.xml:r
- ./config/hdfs-site.xml:/root/hadoop/etc/hadoop/hdfs-site.xml:r
- ./config/yarn-site.xml:/root/hadoop/etc/hadoop/yarn-site.xml:r
- ./config/mapred-site.xml:/root/hadoop/etc/hadoop/mapred-site.xml:r
# 映射workers文件
- ./config/workers:/root/hadoop/etc/hadoop/workers:r
# 映射spark配置文件
- ./sparkconf/spark-env.sh:/root/spark/conf/spark-env.sh:r
- ./sparkconf/spark-defaults.conf:/root/spark/conf/spark-defaults.conf:r
- ./sparkconf/workers:/root/spark/conf/workers:r
# 映射数据目录
- /hadoopdata/4:/hadoopdata:wr
- /sparkdata/4:/sparkdata:wr
# 映射初始化脚本
- ./init-spark.sh:/root/init-spark.sh:r
pignode5:
image: pig/spark
deploy:
endpoint_mode: dnsrr
restart_policy:
condition: on-failure
placement:
# 将Mapreduce限制部署在第三个节点上
constraints:
# node.role==manager
- node.hostname==pighost3
networks:
- pig
ports:
- target: 22
published: 9015
protocol: tcp
mode: host
hostname: pignode5
volumes:
# 映射xml配置文件
- ./config/core-site.xml:/root/hadoop/etc/hadoop/core-site.xml:r
- ./config/hdfs-site.xml:/root/hadoop/etc/hadoop/hdfs-site.xml:r
- ./config/yarn-site.xml:/root/hadoop/etc/hadoop/yarn-site.xml:r
- ./config/mapred-site.xml:/root/hadoop/etc/hadoop/mapred-site.xml:r
# 映射workers文件
- ./config/workers:/root/hadoop/etc/hadoop/workers:r
# 映射spark配置文件
- ./sparkconf/spark-env.sh:/root/spark/conf/spark-env.sh:r
- ./sparkconf/spark-defaults.conf:/root/spark/conf/spark-defaults.conf:r
- ./sparkconf/workers:/root/spark/conf/workers:r
# 映射数据目录
- /hadoopdata/5:/hadoopdata:wr
- /sparkdata/5:/sparkdata:wr
# 映射初始化脚本
- ./init-spark.sh:/root/init-spark.sh:r
pignode6:
image: pig/spark
deploy:
endpoint_mode: dnsrr
restart_policy:
condition: on-failure
placement:
# 将Mapreduce限制部署在第三个节点上
constraints:
# node.role==manager
- node.hostname==pighost3
networks:
- pig
ports:
- target: 22
published: 9016
protocol: tcp
mode: host
hostname: pignode6
volumes:
# 映射xml配置文件
- ./config/core-site.xml:/root/hadoop/etc/hadoop/core-site.xml:r
- ./config/hdfs-site.xml:/root/hadoop/etc/hadoop/hdfs-site.xml:r
- ./config/yarn-site.xml:/root/hadoop/etc/hadoop/yarn-site.xml:r
- ./config/mapred-site.xml:/root/hadoop/etc/hadoop/mapred-site.xml:r
# 映射workers文件
- ./config/workers:/root/hadoop/etc/hadoop/workers:r
# 映射spark配置文件
- ./sparkconf/spark-env.sh:/root/spark/conf/spark-env.sh:r
- ./sparkconf/spark-defaults.conf:/root/spark/conf/spark-defaults.conf:r
- ./sparkconf/workers:/root/spark/conf/workers:r
# 映射数据目录
- /hadoopdata/6:/hadoopdata:wr
- /sparkdata/6:/sparkdata:wr
# 映射初始化脚本
- ./init-spark.sh:/root/init-spark.sh:r
pignode7:
image: pig/spark
deploy:
endpoint_mode: dnsrr
restart_policy:
condition: on-failure
placement:
# 将Mapreduce限制部署在第三个节点上
constraints:
# node.role==manager
- node.hostname==pighost4
networks:
- pig
ports:
- target: 22
published: 9017
protocol: tcp
mode: host
hostname: pignode7
volumes:
# 映射xml配置文件
- ./config/core-site.xml:/root/hadoop/etc/hadoop/core-site.xml:r
- ./config/hdfs-site.xml:/root/hadoop/etc/hadoop/hdfs-site.xml:r
- ./config/yarn-site.xml:/root/hadoop/etc/hadoop/yarn-site.xml:r
- ./config/mapred-site.xml:/root/hadoop/etc/hadoop/mapred-site.xml:r
# 映射workers文件
- ./config/workers:/root/hadoop/etc/hadoop/workers:r
# 映射spark配置文件
- ./sparkconf/spark-env.sh:/root/spark/conf/spark-env.sh:r
- ./sparkconf/spark-defaults.conf:/root/spark/conf/spark-defaults.conf:r
- ./sparkconf/workers:/root/spark/conf/workers:r
# 映射数据目录
- /hadoopdata/7:/hadoopdata:wr
- /sparkdata/7:/sparkdata:wr
# 映射初始化脚本
- ./init-spark.sh:/root/init-spark.sh:r
pignode8:
image: pig/spark
deploy:
endpoint_mode: dnsrr
restart_policy:
condition: on-failure
placement:
# 将Mapreduce限制部署在第三个节点上
constraints:
# node.role==manager
- node.hostname==pighost4
networks:
- pig
ports:
- target: 22
published: 9018
protocol: tcp
mode: host
hostname: pignode8
volumes:
# 映射xml配置文件
- ./config/core-site.xml:/root/hadoop/etc/hadoop/core-site.xml:r
- ./config/hdfs-site.xml:/root/hadoop/etc/hadoop/hdfs-site.xml:r
- ./config/yarn-site.xml:/root/hadoop/etc/hadoop/yarn-site.xml:r
- ./config/mapred-site.xml:/root/hadoop/etc/hadoop/mapred-site.xml:r
# 映射workers文件
- ./config/workers:/root/hadoop/etc/hadoop/workers:r
# 映射spark配置文件
- ./sparkconf/spark-env.sh:/root/spark/conf/spark-env.sh:r
- ./sparkconf/spark-defaults.conf:/root/spark/conf/spark-defaults.conf:r
- ./sparkconf/workers:/root/spark/conf/workers:r
# 映射数据目录
- /hadoopdata/8:/hadoopdata:wr
- /sparkdata/8:/sparkdata:wr
# 映射初始化脚本
- ./init-spark.sh:/root/init-spark.sh:r
pignode9:
image: pig/spark
deploy:
endpoint_mode: dnsrr
restart_policy:
condition: on-failure
placement:
# 将Mapreduce限制部署在第三个节点上
constraints:
# node.role==manager
- node.hostname==pighost4
networks:
- pig
ports:
- target: 22
published: 9019
protocol: tcp
mode: host
hostname: pignode9
volumes:
# 映射xml配置文件
- ./config/core-site.xml:/root/hadoop/etc/hadoop/core-site.xml:r
- ./config/hdfs-site.xml:/root/hadoop/etc/hadoop/hdfs-site.xml:r
- ./config/yarn-site.xml:/root/hadoop/etc/hadoop/yarn-site.xml:r
- ./config/mapred-site.xml:/root/hadoop/etc/hadoop/mapred-site.xml:r
# 映射workers文件
- ./config/workers:/root/hadoop/etc/hadoop/workers:r
# 映射spark配置文件
- ./sparkconf/spark-env.sh:/root/spark/conf/spark-env.sh:r
- ./sparkconf/spark-defaults.conf:/root/spark/conf/spark-defaults.conf:r
- ./sparkconf/workers:/root/spark/conf/workers:r
# 映射数据目录
- /hadoopdata/9:/hadoopdata:wr
- /sparkdata/9:/sparkdata:wr
# 映射初始化脚本
- ./init-spark.sh:/root/init-spark.sh:r
pignode10:
image: pig/spark
deploy:
endpoint_mode: dnsrr
restart_policy:
condition: on-failure
placement:
# 将Mapreduce限制部署在第三个节点上
constraints:
# node.role==manager
- node.hostname==pighost5
networks:
- pig
ports:
- target: 22
published: 9020
protocol: tcp
mode: host
hostname: pignode10
volumes:
# 映射xml配置文件
- ./config/core-site.xml:/root/hadoop/etc/hadoop/core-site.xml:r
- ./config/hdfs-site.xml:/root/hadoop/etc/hadoop/hdfs-site.xml:r
- ./config/yarn-site.xml:/root/hadoop/etc/hadoop/yarn-site.xml:r
- ./config/mapred-site.xml:/root/hadoop/etc/hadoop/mapred-site.xml:r
# 映射workers文件
- ./config/workers:/root/hadoop/etc/hadoop/workers:r
# 映射spark配置文件
- ./sparkconf/spark-env.sh:/root/spark/conf/spark-env.sh:r
- ./sparkconf/spark-defaults.conf:/root/spark/conf/spark-defaults.conf:r
- ./sparkconf/workers:/root/spark/conf/workers:r
# 映射数据目录
- /hadoopdata/10:/hadoopdata:wr
- /sparkdata/10:/sparkdata:wr
# 映射初始化脚本
- ./init-spark.sh:/root/init-spark.sh:r
pignode11:
image: pig/spark
deploy:
endpoint_mode: dnsrr
restart_policy:
condition: on-failure
placement:
# 将Mapreduce限制部署在第三个节点上
constraints:
# node.role==manager
- node.hostname==pighost5
networks:
- pig
ports:
- target: 22
published: 9021
protocol: tcp
mode: host
hostname: pignode11
volumes:
# 映射xml配置文件
- ./config/core-site.xml:/root/hadoop/etc/hadoop/core-site.xml:r
- ./config/hdfs-site.xml:/root/hadoop/etc/hadoop/hdfs-site.xml:r
- ./config/yarn-site.xml:/root/hadoop/etc/hadoop/yarn-site.xml:r
- ./config/mapred-site.xml:/root/hadoop/etc/hadoop/mapred-site.xml:r
# 映射workers文件
- ./config/workers:/root/hadoop/etc/hadoop/workers:r
# 映射spark配置文件
- ./sparkconf/spark-env.sh:/root/spark/conf/spark-env.sh:r
- ./sparkconf/spark-defaults.conf:/root/spark/conf/spark-defaults.conf:r
- ./sparkconf/workers:/root/spark/conf/workers:r
# 映射数据目录
- /hadoopdata/11:/hadoopdata:wr
- /sparkdata/11:/sparkdata:wr
# 映射初始化脚本
- ./init-spark.sh:/root/init-spark.sh:r
pignode12:
image: pig/spark
deploy:
endpoint_mode: dnsrr
restart_policy:
condition: on-failure
placement:
# 将Mapreduce限制部署在第三个节点上
constraints:
# node.role==manager
- node.hostname==pighost5
networks:
- pig
ports:
- target: 22
published: 9022
protocol: tcp
mode: host
hostname: pignode12
volumes:
# 映射xml配置文件
- ./config/core-site.xml:/root/hadoop/etc/hadoop/core-site.xml:r
- ./config/hdfs-site.xml:/root/hadoop/etc/hadoop/hdfs-site.xml:r
- ./config/yarn-site.xml:/root/hadoop/etc/hadoop/yarn-site.xml:r
- ./config/mapred-site.xml:/root/hadoop/etc/hadoop/mapred-site.xml:r
# 映射workers文件
- ./config/workers:/root/hadoop/etc/hadoop/workers:r
# 映射spark配置文件
- ./sparkconf/spark-env.sh:/root/spark/conf/spark-env.sh:r
- ./sparkconf/spark-defaults.conf:/root/spark/conf/spark-defaults.conf:r
- ./sparkconf/workers:/root/spark/conf/workers:r
# 映射数据目录
- /hadoopdata/12:/hadoopdata:wr
- /sparkdata/12:/sparkdata:wr
# 映射初始化脚本
- ./init-spark.sh:/root/init-spark.sh:r
zookeeper1:
image: zookeeper:latest
deploy:
endpoint_mode: dnsrr
restart_policy:
condition: on-failure
placement:
constraints:
- node.hostname==pighost1
networks:
- pig
ports:
- target: 2181
published: 2181
protocol: tcp
mode: host
hostname: zookeeper1
environment:
- ZOO_MY_ID=1
- ZOO_SERVERS=server.1=zookeeper1:2888:3888;2181 server.2=zookeeper2:2888:3888;2181 server.3=zookeeper3:2888:3888;2181
volumes:
- /hadoopdata/zoo/1/data:/data
- /hadoopdata/zoo/1/datalog:/datalog
- /hadoopdata/zoo/1/logs:/logs
zookeeper2:
image: zookeeper:latest
deploy:
endpoint_mode: dnsrr
restart_policy:
condition: on-failure
placement:
constraints:
- node.hostname==pighost2
networks:
- pig
ports:
- target: 2181
published: 2182
protocol: tcp
mode: host
hostname: zookeeper2
environment:
- ZOO_MY_ID=2
- ZOO_SERVERS=server.1=zookeeper1:2888:3888;2181 server.2=zookeeper2:2888:3888;2181 server.3=zookeeper3:2888:3888;2181
volumes:
- /hadoopdata/zoo/2/data:/data
- /hadoopdata/zoo/2/datalog:/datalog
- /hadoopdata/zoo/2/logs:/logs
zookeeper3:
image: zookeeper:latest
deploy:
endpoint_mode: dnsrr
restart_policy:
condition: on-failure
placement:
constraints:
- node.hostname==pighost3
networks:
- pig
ports:
- target: 2181
published: 2183
protocol: tcp
mode: host
hostname: zookeeper3
environment:
- ZOO_MY_ID=3
- ZOO_SERVERS=server.1=zookeeper1:2888:3888;2181 server.2=zookeeper2:2888:3888;2181 server.3=zookeeper3:2888:3888;2181
volumes:
- /hadoopdata/zoo/3/data:/data
- /hadoopdata/zoo/3/datalog:/datalog
- /hadoopdata/zoo/3/logs:/logs
networks:
pig:
为了修改方便,把初始化脚本给映射上去了,后期可以拿掉。另外,就是数据目录千万不要嵌套映射。中间偷懒把spark目录映射到了hadoop已经映射过的目录下面。不报任何错误,只是所有被映射目录均为空,导致排查好长时间……
六、运行
使用swarm,一旦完全配置好了以后还是很简单的。为了表达一下开心,上图:
(一)名字服务器



可以看到,HA下3个NameNode,第2个名字服务器现在是活跃的
(二)数据服务器DataNode
9个数据节点也挺健康


(三)Yarn Resource Manager HA


前面提到过,只有active的那个yarn会提供web UI
(四)Job History Server

(五)Spark Master



可以看到,Stanby的master节点,是不管理workers的。
(六)Spark交互式界面


spark-shell和pyspark。虽然python是相当大众化了,但是scala也不错,尤其是它的lamda语法,简直感觉这个语言就是为spark而生,给用户白送的,入门门槛相当低。我已经迫不及待打算开始搓一搓了。文章来源:https://www.toymoban.com/news/detail-452401.html
文章来源地址https://www.toymoban.com/news/detail-452401.html
到了这里,关于CENTO OS上的网络安全工具(二十二)Spark HA swarm容器化集群部署的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!