typora-copy-images-to: upload
第三章 决策树
3.1决策树的构造
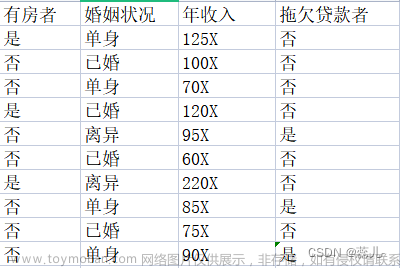
- 优点:计算复杂度不高 输出结果易于理解 对中间值的缺失不敏感,可以处理不相关的特征数据
- 缺点:可能会产生过度匹配的问题
- 适用数据类型 数据型和标称型
一般流程:
收集数据 准备数据 分析数据 训练算法 测试算法 使用算法

数据重新加载的问题
代码实现
# coding:UTF-8
from math import log
# 计算给定数据集的香农嫡
def calcShannonEnt(dataSet):
numEntries = len(dataSet)
labelCounts = {}
for featVec in dataSet:
currentLabel = featVec[-1]
if currentLabel not in labelCounts.keys():
labelCounts[currentLabel] = 0
labelCounts[currentLabel] += 1
shannonEnt = 0.0
for key in labelCounts:
prob = float(labelCounts[key]) / numEntries
shannonEnt -= prob * log(prob, 2)
return shannonEnt
def createDataSet():
dataSet = [[1, 1, 'yes'], [1, 1, 'yes'], [0, 1, 'no'], [0, 1, 'no']]
labels = ['no surfacing', 'flippers']
return dataSet, labels
def main():
myDat, labels = createDataSet()
print(myDat)
print("%f" % calcShannonEnt(myDat))
if __name__ == "__main__":
main()
实现截图
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Wktrh11D-1664967392793)(https://cdn.jsdelivr.net/gh/hudiework/img@main/image-20221004200407218.png)]
获取最大信息增益的方法获取数据集 实现代码
myDat[0][-1] = 'maybe'
print(myDat)
print("-------------")
print(calcShannonEnt(myDat))
实现截图
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-RgXGT47J-1664967392793)(https://cdn.jsdelivr.net/gh/hudiework/img@main/image-20221004200334343.png)]
3.2 划分数据集
3-2 按照给定特征划分数据集
# 选择最好的数据集划分方式
def chooseBestFeatureToSplit(dataSet):
numFeatures = len(dataSet[0]) - 1
baseEntropy = calcShannonEnt(dataSet)
bestInfoGain = 0.0; bestFeature = -1
for i in range(numFeatures):
featList = [example[i] for example in dataSet]
uniqueVals = set(featList)
newEntropy = 0.0
for value in uniqueVals:
subDataSet = splitDataSet(dataSet, i, value)
prob = len(subDataSet) / float(len(dataSet))
newEntropy += prob * calcShannonEnt(subDataSet)
infoGain = baseEntropy - newEntropy
if (infoGain > bestInfoGain):
bestInfoGain = infoGain
bestFeature = i
return bestFeature
3.1.3 递归构建决策树
创建树的代码:
def createTree(dataSet, labels):
classList = [example[-1] for example in dataSet]
if classList.count(classList[0]) == len(classList):
return classList[0]
if len(dataSet[0]) == 1:
return majorityCnt(classList)
bestFeat = chooseBestFeatureToSplit(dataSet)
bestFeatLabel = labels[bestFeat]
myTree = {bestFeatLabel: {}}
del (labels[bestFeat])
featValues = [example[bestFeat] for example in dataSet]
uniqueVals = set(featValues)
for value in uniqueVals:
sublabels = labels[:]
myTree[bestFeatLabel][value] = createTree(splitDataSet \
(dataSet, bestFeat, value), sublabels)
return myTree
运行代码
myDat, labels = createDataSet()
mytree = createTree(myDat,labels)
print(mytree)
实现截图
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-qyptJh00-1664967392793)(https://cdn.jsdelivr.net/gh/hudiework/img@main/image-20221004200245619.png)]
3.2.1 在python中使用Matplotlib注解绘制树形图
注解工具annotations
代码实现
from pylab import mpl
# 设置中文显示字体
mpl.rcParams["font.sans-serif"] = ["SimHei"]
# 设置正常显示符号
mpl.rcParams["axes.unicode_minus"] = False
def createPlot():
fig = plt.figure(1, facecolor='white')
fig.clf()
createPlot.ax1 = plt.subplot(111, frameon=False)
plotNode(U'Decision Node', (0.5, 0.1), (0.1, 0.5), decisionNode)
plotNode(U'Leaf Node', (0.8, 0.1), (0.3, 0.8), leafNode)
plt.show()
实现截图
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-l4B1iqLy-1664967392794)(https://cdn.jsdelivr.net/gh/hudiework/img@main/image-20221005132825703.png)]
3.2.2 构造注解树
程序清单3-6 获取叶节点的树目和树的层数
MAC pycharm打不开
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-MlxewiAV-1664967392794)(https://cdn.jsdelivr.net/gh/hudiework/img@main/image-20221005140639325.png)]
代码实现
def getNumLeafs(myTree):
numLeafs = 0
firstStr = list(myTree.keys())[0]
secondDict = myTree[firstStr]
for key in secondDict.keys():
if type(secondDict[key]).__name__ == 'dict':
numLeafs += getNumLeafs(secondDict[key])
else:
numLeafs += 1
return numLeafs
def getTreeDepth(myTree):
maxDepth = 0
firstStr = list(myTree.keys())[0]
secondDict = myTree[firstStr]
for key in secondDict.keys():
if type(secondDict[key]).__name__ == 'dict':
thisDepth = 1 + getTreeDepth(secondDict[key])
else:
thisDepth = 1
if thisDepth > maxDepth:
maxDepth = thisDepth
return maxDepth
def retrieveTree(i):
listOfTrees = [{'no surfacing': {0: 'no', 1: {'flippers': \
{0: 'no', 1: 'yes'}}}},
{'no surfacing': {0: 'no', 1: {'flippers': \
{0: {'head': {0: 'no', 1: 'yes'}}, 1: 'no'}}}}
]
return listOfTrees[i]
结果截图
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-poBP9cv7-1664967392794)(https://cdn.jsdelivr.net/gh/hudiework/img@main/image-20221005143942150.png)]
程序清单3-7 plotTree函数
程序代码
def plotMidText(cntrPt, parentPt, txtString):
xMid = (parentPt[0] - cntrPt[0]) / 2.0 + cntrPt[0]
yMid = (parentPt[1] - cntrPt[1]) / 2.0 + cntrPt[1]
createPlot.ax1.text(xMid, yMid, txtString)
def plotTree(myTree, parentPt, nodeTxt):
numLeafs = getNumLeafs(myTree)
depth = getTreeDepth(myTree)
firstStr = list(myTree.keys())[0]
cntrPt = (plotTree.xOff + (1.0 + float(numLeafs)) / 2.0 / plotTree.totalW, \
plotTree.yOff)
plotMidText(cntrPt, parentPt, nodeTxt)
plotNode(firstStr, cntrPt, parentPt, decisionNode)
secondDict = myTree[firstStr]
plotTree.yOff = plotTree.yOff - 1.0 / plotTree.totalD
for key in secondDict.keys():
if type(secondDict[key]).__name__ == 'dict':
plotTree(secondDict[key], cntrPt, str(key))
else:
plotTree.xOff = plotTree.xOff + 1.0 / plotTree.totalW
plotNode(secondDict[key], (plotTree.xOff, plotTree.yOff), \
cntrPt, leafNode)
plotMidText((plotTree.xOff, plotTree.yOff,), cntrPt, str(key))
plotTree.yOff = plotTree.yOff + 1.0 / plotTree.totalD
def createPlot(inTree):
fig = plt.figure(1, facecolor='white')
fig.clf()
axprops = dict(xticks=[], yticks=[])
createPlot.ax1 = plt.subplot(111, frameon=False, **axprops)
plotTree.totalW = float(getNumLeafs(inTree))
plotTree.totalD = float(getTreeDepth(inTree))
plotTree.xOff = - 0.5 / plotTree.totalW;
plotTree.yOff = 1.0;
plotTree(inTree, (0.5, 1.0), '')
plt.show()
执行代码
matplotlib.use('TkAgg')
mytree = retrieveTree(0)
# print(getNumLeafs(mytree))
# print(getTreeDepth(mytree))
createPlot(mytree)
实现截图
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ICreMC7z-1664967392794)(https://cdn.jsdelivr.net/gh/hudiework/img@main/image-20221005172516454.png)]
3.3 测试和存储分类器
3.3.1 测试算法:使用决策树进行分类 程序3-8 使用决策树的分类函数
def classify(inputTree, featLabels, testVec):
firstStr = list(inputTree.keys())[0]
secondDict = inputTree[firstStr]
featIndex = featLabels.index(firstStr)
for key in secondDict.keys():
if testVec[featIndex] == key:
if type(secondDict[key]).__name__ == 'dict':
classLabel = classify(secondDict[key], featLabels, testVec)
else:
classLabel = secondDict[key]
return classLabel
实现代码
matplotlib.use('TkAgg')
myDat, labels = createDataSet()
mytree = retrieveTree(0)
# print(getNumLeafs(mytree))
# print(getTreeDepth(mytree))
# createPlot(mytree)
print(classify(mytree, labels, [1, 0]))
print(classify(mytree, labels, [1, 1]))
实现截图
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-3118drTK-1664967392794)(https://cdn.jsdelivr.net/gh/hudiework/img@main/image-20221005173540215.png)]
3.3.2 使用算法:决策树的存储 3-9 使用pickle模块存储决策树
代码实现
def storeTree(inputTree, filename):
import pickle
fw = open(filename, 'wb')
pickle.dump(inputTree, fw)
fw.close()
def grabTree(filename):
import pickle
fr = open(filename, 'rb')
return pickle.load(fr)
执行代码
mytree = retrieveTree(0)
print(mytree)
storeTree(mytree, 'classifierStorage.txt')
print(grabTree('classifierStorage.txt'))
实现截图
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Fl8VDsSB-1664967392795)(https://cdn.jsdelivr.net/gh/hudiework/img@main/image-20221005180153803.png)]文章来源:https://www.toymoban.com/news/detail-452484.html
使用决策树预测隐形眼镜类型
执行代码
matplotlib.use('TkAgg')
mytree = retrieveTree(0)
print(mytree)
storeTree(mytree, 'classifierStorage.txt')
# print(grabTree('classifierStorage.txt'))
fr = open('lenses.txt')
lenses = [inst.strip().split('\t') for inst in fr.readlines()]
# print("--------")
# print(lenses)
lensesLabels = ['age', 'prescipt', 'astigmatic', 'tearRate']
lensesTree = createTree(lenses, lensesLabels)
print(lensesTree)
createPlot(lensesTree)
实现截图
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-8BlGHhSG-1664967392795)(https://cdn.jsdelivr.net/gh/hudiework/img@main/image-20221005185537583.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-KOS7GKdd-1664967458351)(https://cdn.jsdelivr.net/gh/hudiework/img@main/image-20221005185537583.png)]文章来源地址https://www.toymoban.com/news/detail-452484.html
到了这里,关于【机器学习实战】决策树 python代码实现的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!