一、前言
什么是k8s?
Kuberentes 是基于容器的集群管理平台,它的简称,是K8S。有人说之所以叫k8s,是因为k到s中间有8个字母,因此叫k8s,也有人说,在使用k8s的安装配置流程中,共分为8步,大家各自参考就好。
传统的应用部署方式是通过插件或脚本来安装应用。这样做的缺点是应用的运行、配置、管理、所有生存周期将与当前操作系统绑定,这样做并不利于应用的升级更新/回滚等操作,当然也可以通过创建虚拟机的方式来实现某些功能,但是虚拟机非常重,并不利于可移植性。
新的方式是通过部署容器方式实现,每个容器之间互相隔离,每个容器有自己的文件系统 ,容器之间进程不会相互影响,能区分计算资源。相对于虚拟机,容器能快速部署,由于容器与底层设施、机器文件系统解耦的,所以它能在不同云、不同版本操作系统间进行迁移。
容器占用资源少、部署快,每个应用可以被打包成一个容器镜像,每个应用与容器间成一对一关系也使容器有更大优势,使用容器可以在build或release 的阶段,为应用创建容器镜像,因为每个应用不需要与其余的应用堆栈组合,也不依赖于生产环境基础结构,这使得从研发到测试、生产能提供一致环境。类似地,容器比虚拟机轻量、更“透明”,这更便于监控和管理。
各位同堂,希望通过本次介绍k8s的诞生与关键技术,让我们了解流行技术发展中的一些规律或者技术特点,给想准备使用k8s和设计系统的人一些启发。
我将从k8s的时代背景, k8s的架构与对象,设计理念四个方面去介绍k8s。不涉及具体的配置操作。最后是我的一个总结。
二、 k8s的时代背景
2.1 云计算发展概览

讲到k8s 我们先从物理机到虚拟化说起。最早我们的应用都是直接在物理机部署、运行的。代表公司有传统IBM,SUN公司。
在上世纪60年代,就提出了虚拟化的概念了。分时系统就是相关的技术。后来提出针对服务器市场虚拟化技术方案,满足提升计算资源利用率和降低成本的要求。VMware,Xen和KVM,三足鼎力,促进VM概念的普及,拉开虚拟云时代计算的大幕。
到了2006年,基于虚拟机技术,AWS开启基础设施服务的市场实现了自助,按需租用以VM为基本计算单元的计算资源,基础计算单元变成VM,服务端应用构建部署和运行逐步迁移到虚拟机VM上。谷歌也加入了进来,叫做GCE。
2010年开始进入成熟期基于虚拟化技术的公有云爆发式增长,形成公有云四巨头AWS,Azure,Aliyun,GCE。
2.2 容器的产生
云计算(虚拟化技术)解决了基础资源层的弹性伸缩,却没有解决 PaaS层应用随基础资源层弹性伸缩而带来的批量、快速部署问题。于是容器应运而生。
容器是一种沙盒技术,主要目的是为了将应用运行在其中,与外界隔离;及方便这个沙盒可以被转移到其它宿主机器。本质上,它是一个特殊的进程。通过名称空间(Namespace)、控制组(Control groups)、切根(chroot)技术把资源、文件、设备、状态和配置划分到一个独立的空间。
通俗点的理解就是一个装应用软件的箱子,箱子里面有软件运行所需的依赖库和配置。开发人员可以把这个箱子搬到任何机器上,且不影响里面软件的运行。
容器和虚拟化的区别是什么呢?通过这幅图,我们可以看到为什么容器是轻量的,因为它不像虚拟机那样,虚拟一套硬件和完整操作系统。而容器实际上是通过内核去控制,去使用使宿主机的cpu和内存。
Docker是流行的容器。除了大名鼎鼎的 Docker,还有其他的容器,例如 AppC、Mesos Container,都能运行容器镜像。所以说容器不等于 Docker。
Docker有一个独特的功能就是镜像。将镜像还原成运行时的过程(就是读取镜像文件,还原那个时刻的过程)就是容器运行的过程.
Docker镜像是Docker项目能够成功的关键。它解决的根本问题就是应用打包的问题。Docker通过提供一种非常方便的打包机制,直接打包了应用运行所需要的整个操作系统(其实只打包了文件系统),从而保证了本地环境和云端环境的高度一致。
2.3 k8s的诞生
Docker毕竟只是解决了打包的问题。在微服务化情况下,容器数量会非常多,如何管理容器,持续集成和编排的问题不可避免。
这时候,Kubernetes、Mesos,Swarm三大平台为解决容器的问题而出现,互相竞争,抢占市场。Kubernetes基于google公司已经使用了十多年的Borg项目进行了沉淀和升华才提出的一套框架,使其拥有一套完整的全新的设计理念,在设计上有很强的扩展性。同时有Google的背书,以及相对优秀的社区运营能力。所以最终Kubernetes赢得了胜利,成为了容器生态的行业标准。
Kubernetes是容器集群管理系统,是一个开源的平台,可以实现容器集群的自动化部署、自动扩缩容、维护等功能。kubernetes主要解决容器编排问题。
三、K8s架构与对象

学习Kubernetes的架构,有助于我们了解Kubernetes的全貌,帮助我们进一步学习Kubernetes其他内容。Kubernetes本身细节很多,但从它的架构图来看,整体简单明了。我认为优秀的设计,往往在整体上是简单的,而且是易于理解的。
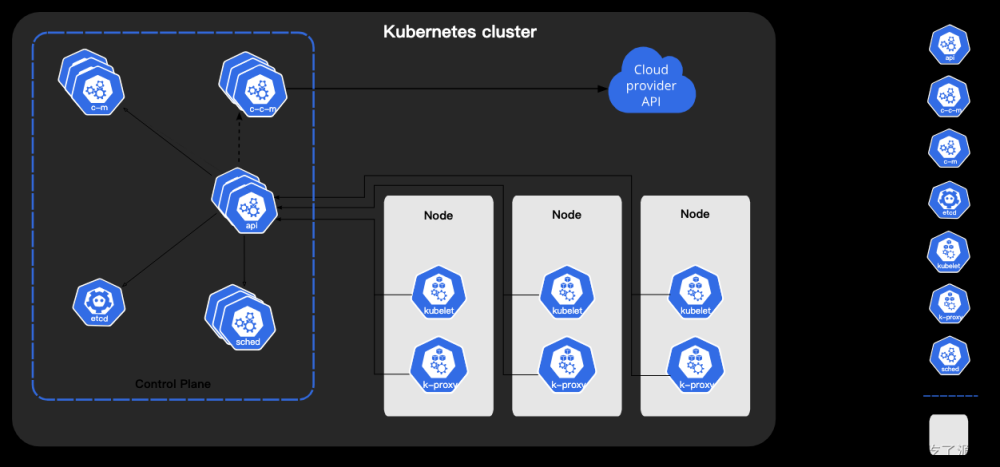
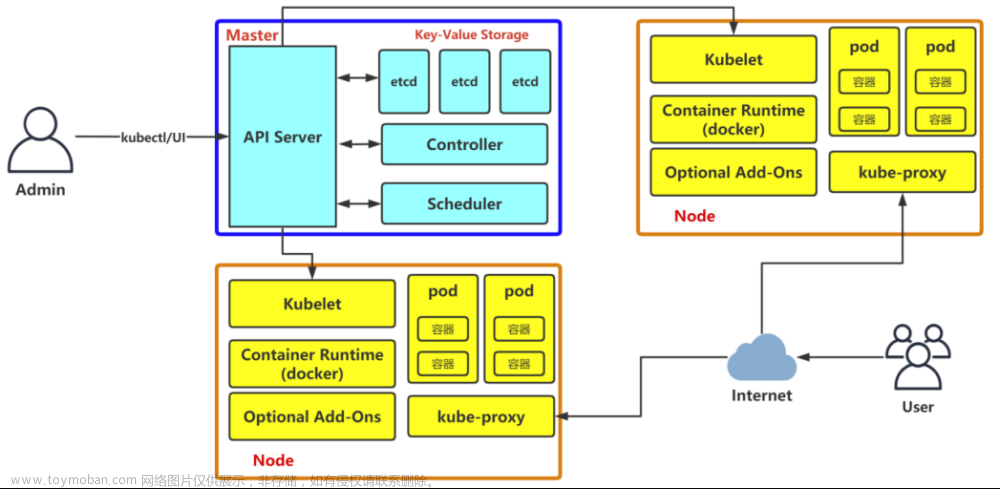
Kubernetes的功能组件是松耦合的,它们各司其职,功能明确。有负责外部资源请求的安全访问和控制,有的负责内部资源任务的调度(Scheduler)。然后由统一的api将对应的操作请求分发到对应的物理节点。再由各个节点的代理人(kubelet)根据资源的请求去管理容器(pod)。
Kubernetes集群有各种二进制组件,这些组件承担不同的角色,共同支持kubernetes集群的运行。Kubernetes集群角色有管理节点和工作节点,它们都是可以分布式部署的。管理节点主要负责整个集群的控制。对资源调度和配置,以及持久化集群的数据(节点,容器状态等,而非具体某个业务应用的日志等数据)。工作节点提供Kubernetes运行时环境,以及维护Pod,也就是实际运行我们应用的节点。
3.1 管理节点主要组件
kube-apiserver
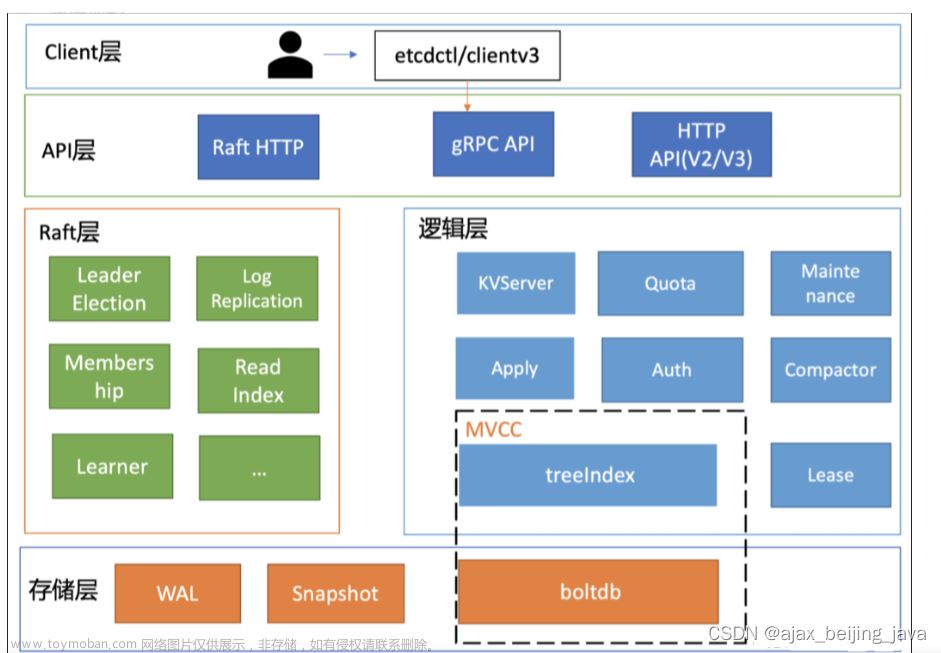
ETCD
etcd是Kubernetes提供默认的存储系统,保存所有集群数据,使用时需要为etcd数据提供备份计划。
kube-controller-manager
节点(Node)控制器。
副本(Replication)控制器:负责维护系统中每个副本中的pod。
端点(Endpoints)控制器:填充Endpoints对象(即连接Services&Pods)。
Service Account和Token控制器:为新的Namespace 创建默认帐户访问API Token。
cloud-controller-manager
云控制器管理器负责与底层云提供商的平台交互。它是Kubernetes中开放给云厂商的通用接口,便于Kubernetes自动管理和利用云服务商提供的资源,这些资源包括虚拟机资源、负载均衡服务、弹性公网IP、存储服务等。
cloud-controller-manager 具体功能:
节点(Node)控制器
路由(Route)控制器
Service控制器
卷(Volume)控制器
3.2 工作节点(Node)主要组件
kubelet
kubelet是主要的节点代理,它会监视已分配给节点的pod,具体功能:
安装Pod所需的volume。
下载Pod的Secrets。
Pod中运行的 docker(或experimentally,rkt)容器。
定期执行容器健康检查。
报告容器个节点的状态
kube-proxy
kube-proxy通过在主机上维护网络规则并执行连接转发来实现Kubernetes服务抽象。简单来说,就是负责Kubernetes集群内部网络通信的。
节点(Node)控制器
路由(Route)控制器
Service控制器
卷(Volume)控制器
3.3 k8s对象
Kubernetes对象是Kubernetes系统中的持久实体。Kubernetes使用这些实体来表示集群的状态。具体来说,他们可以描述:
容器化应用正在运行(以及在哪些节点上)
这些应用可用的资源
关于这些应用如何运行的策略,如重新策略,升级和容错
Kubernetes对象是“record of intent”,一旦创建了对象,Kubernetes系统会确保对象存在。通过创建对象,可以有效地告诉Kubernetes系统你希望集群的工作负载是什么样的。
3.4 常见的k8s对象
Pod
Pod是Kubernetes创建或部署的最小/最简单的基本单位,一个Pod代表集群上正在运行的一个进程。
一个Pod封装一个应用容器(也可以有多个容器),存储资源、一个独立的网络IP以及管理控制容器运行方式的策略选项。Pod代表部署的一个单位:Kubernetes中单个应用的实例,它可能由单个容器或多个容器共享组成的资源。
ReplicationController
(简称RC)是确保用户定义的Pod副本数保持不变。
ReplicaSet
ReplicaSet(RS)是Replication Controller(RC)的升级版本。ReplicaSet 和 Replication Controller之间的唯一区别是对选择器的支持。
Deployment
Deployment又叫部署,这是我们部署应用最常用的对象类型。
Deployment为Pod和Replica Set提供声明式更新,它是更上一层的抽象和封装。通过Deployment控制Replica Set,用作pod 机制的创建、删除和更新。
Service
Service 定义了这样一种抽象:一个 Pod 的逻辑分组,一种可以访问它们的策略 —— 通常称为微服务。 这一组 Pod 能够被 Service 访问到,通常是通过 Label Selector将Pod与Service关联起来。
Service对象里面允许你定义一个固定的IP,这样,外部调用的时候,就可以直接访问这个固定IP,Service接到请求之后,自动负载均衡的转发到关联的Pod上。
Volume
翻译过来叫做“卷”,显然和存储有关。
Namespaces(命名空间)
命名空间是用来隔离对象资源的。上文提到的如pod、service、Deployment等于应用相关的对象都是需要指定Namespaces的
Kubernetes可以使用Namespaces(命名空间)创建多个虚拟集群。当团队或项目中具有许多用户时,可以考虑使用Namespace来区分。定义了命名空间,我们还可以做计算机资源、网络的统一限制,比如默认开放一些端口,默认pod创建时使用多少cpu、内存等等。
3.5 fcp使用的k8s对象
四、k8s设计理念
Kubernetes系统最核心的两个设计理念:一个是容错性,一个是易扩展性。容错性实际是保证Kubernetes系统稳定性和安全性的基础,易扩展性是保证Kubernetes对变更友好,可以快速迭代增加新功能的基础。
分析和理解Kubernetes的设计理念可以使我们更深入地了解Kubernetes系统,更好地利用它管理分布式部署的云原生应用,另一方面也可以让我们借鉴其在分布式系统设计方面的经验。下文列举了一些Kubernetes的部分设计原则。
4.1 API部分设计原则
所有API应该是声明式的
声明式的操作,相对于命令式操作,对于重复操作的效果是稳定的,这对于容易出现数据丢失或重复的分布式环境来说是很重要的。
API对象是彼此互补而且可组合的
这里面实际是鼓励API对象尽量实现面向对象设计时的要求,即“高内聚,松耦合”,对业务相关的概念有一个合适的分解,提高分解出来的对象的可重用性。事实上,Kubernetes这种分布式系统管理平台,也是一种业务系统,只不过它的业务就是调度和管理容器服务。所以我们,会看到如Pod、ReplicaSet、Deployment之类的对象,而它们可以组合。
API对象状态不能依赖于网络连接状态。
由于众所周知,在分布式环境下,网络连接断开是经常发生的事情,因此要保证API对象状态能应对网络的不稳定,API对象的状态就不能依赖于网络连接状态。
4.2 控制机制设计部分原则
假设任何错误的可能,并做容错处理
在一个分布式系统中出现局部和临时错误是大概率事件。错误可能来自于物理系统故障,外部系统故障也可能来自于系统自身的代码错误,依靠自己实现的代码不会出错来保证系统稳定其实也是难以实现的,因此要设计对任何可能错误的容错处理。
假设任何操作都可能被任何操作对象拒绝,甚至被错误解析
由于分布式系统的复杂性以及各子系统的相对独立性,不同子系统经常来自不同的开发团队,所以不能奢望任何操作被另一个子系统以正确的方式处理,要保证出现错误的时候,操作级别的错误不会影响到系统稳定性。
每个模块都可以在出错后自动恢复
由于分布式系统中无法保证系统各个模块是始终连接的,因此每个模块要有自我修复的能力,保证不会因为连接不到其他模块而自我崩溃。
五.最后总结
规模增长是推动技术发展的一个重要因素。在设计系统的时候,我们有意识的问两个问题,如果业务量足够大之后,可能会存在什么问题?是否需要提前做一些设计?
尽可能的做到各模块之间彼此独立,不过度依赖,才能保持更灵活的扩展性,适应变化。
分层的对象设计,做到高内聚,松耦合。各个对象组合起来就像洋葱一样,看似一体,实则又是一个个独立的个体对象。比如从Pod,到ReplicaSet,到Deployment,再到Service。从内到外,它们一层包着一层,剥掉最外的一层,它还是能独立运行,再拨一层也还是能独立运行。文章来源:https://www.toymoban.com/news/detail-453478.html
对象、幂等性、统一的Api入口、充分假设、高容错、自我修复等要求与机制融入到设计之中,使得Kubernetes如此的健壮和高扩展性。这些理念在我们设计分布式系统的时候,如分布式调度平台值得去借鉴和使用。文章来源地址https://www.toymoban.com/news/detail-453478.html
到了这里,关于Kuberentes,k8s诞生简介的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!