拓扑排序、字符串匹配算法和最小生成树是计算机科学中常用的数据结构和算法,它们在解决各种实际问题中具有重要的应用价值。在本文中,我将详细介绍这三个主题,并提供相应的示例代码和应用场景,以帮助读者更好地理解和应用这些概念。
一、拓扑排序:
拓扑排序是一种对有向无环图(DAG)进行排序的算法。它可以解决依赖关系的排序问题,常用于构建任务调度、编译器优化等领域。拓扑排序算法的基本思想是通过不断删除入度为0的节点,并更新相关节点的入度,直到所有节点都被访问。
示例问题:课程安排问题
给定一些课程和它们的先修课程关系,要求安排课程的学习顺序,使得先修课程在后修课程之前学习。
示例代码:文章来源:https://www.toymoban.com/news/detail-453780.html
from collections import defaultdict, deque
def topological_sort(num_courses, prerequisites):
# 构建邻接表和入度数组
graph = defaultdict(list)
indegree = [0] * num_courses
for course, prereq in prerequisites:
graph[prereq].append(course)
indegree[course] += 1
# 使用队列进行拓扑排序
queue = deque()
for course in range(num_courses):
if indegree[course] == 0:
queue.append(course)
result = []
while queue:
course = queue.popleft()
result.append(course)
for neighbor in graph[course]:
indegree[neighbor] -= 1
if indegree[neighbor] == 0:
queue.append(neighbor)
if len(result) != num_courses:
return []
return result
# 示例用法
num_courses = 4
prerequisites = [[1, 0], [2, 0], [3, 1], [3, 2]]
result = topological_sort(num_courses, prerequisites)
print("课程学习顺序:", result)
二、字符串匹配算法:
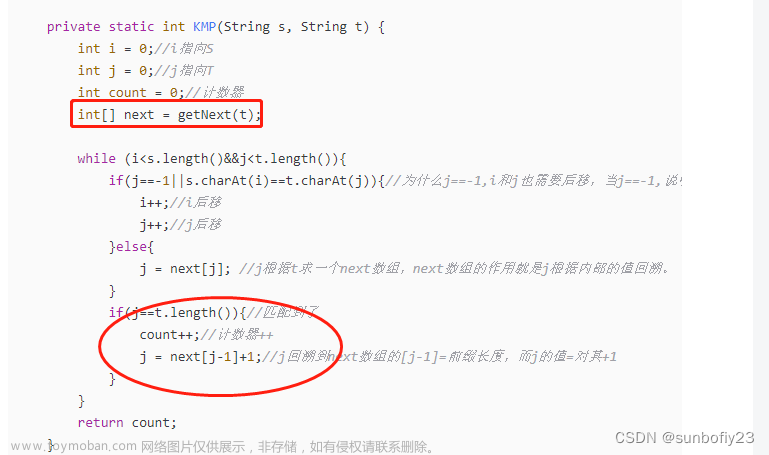
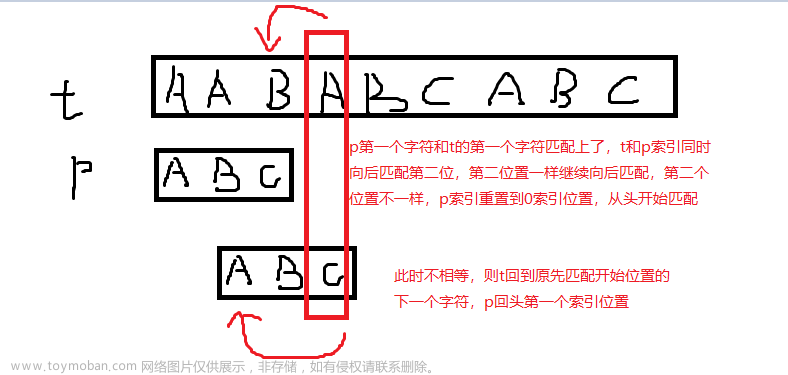
字符串匹配算法用于在文本串中查找给定模式串的出现位置。常见的字符串匹配算法包括暴力匹配算法、KMP算法、Boyer-Moore算法等。这些算法根据不同的思想和技巧,实现了高效的字符串匹配过程。
示例问题:在文本串中查找模式串
给定一个文本串和一个模式串,要求在文本串中查找模式串的出现位置。
示例代码:
def string_match(text, pattern):
m, n = len(text), len(pattern)
for i in range(m - n + 1):
j = 0
while j < n:
if text[i + j] != pattern[j]:
break
j += 1
if j
== n:
return i
return -1
# 示例用法
text = "Hello, World!"
pattern = "World"
result = string_match(text, pattern)
if result != -1:
print("模式串在文本串中的位置:", result)
else:
print("模式串不存在于文本串中")
三、最小生成树:
最小生成树是一种在无向带权图中找到一棵包含所有顶点的生成树,并且使得树上所有边的权值之和最小的算法。常用的最小生成树算法包括Prim算法和Kruskal算法。
示例问题:电网规划问题
给定一个城市的地理信息和建设电网的成本信息,要求设计一种电网规划方案,使得连接城市的成本最小。
示例代码:
from heapq import heapify, heappop, heappush
def minimum_spanning_tree(graph):
visited = set()
start_vertex = list(graph.keys())[0]
visited.add(start_vertex)
edges = [(cost, start_vertex, next_vertex) for next_vertex, cost in graph[start_vertex]]
heapify(edges)
while edges:
cost, u, v = heappop(edges)
if v not in visited:
visited.add(v)
for next_vertex, next_cost in graph[v]:
if next_vertex not in visited:
heappush(edges, (next_cost, v, next_vertex))
return visited
# 示例用法
graph = {
'A': [('B', 5), ('C', 1)],
'B': [('A', 5), ('C', 2), ('D', 1)],
'C': [('A', 1), ('B', 2), ('D', 4)],
'D': [('B', 1), ('C', 4)]
}
result = minimum_spanning_tree(graph)
print("最小生成树的顶点集合:", result)
通过本文对拓扑排序、字符串匹配算法和最小生成树的详细介绍,以及相应的示例代码和应用场景,相信读者能够更好地理解和掌握这些重要的数据结构和算法。在实际的编程和问题解决中,根据具体的需求选择合适的算法和数据结构,将其灵活应用,从而提高程序的效率和性能。希望本文对你的学习和实践有所帮助!文章来源地址https://www.toymoban.com/news/detail-453780.html
到了这里,关于探索经典算法 拓扑排序,字符串匹配算法,最小生成树的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!