基础知识
环境配置
开始爬虫
简单分析目标网站
写函数
获取浏览器对象:
下载每一张图片:
获取每一页的源代码:
运行print_result_every_page
基础知识
- python基础语法
- 面向对象基础
- html基础
- xpath基础
- selenium框架的基本使用
环境配置
- request库
pip install request ‐i https://pypi.douban.com/simple - lxml库
pip install lxml ‐i https://pypi.douban.com/simple
3.安装浏览器xpath插件
打开谷歌浏览器扩展


将压缩包拖进扩展程序界面
会出现报错信息,一定要点进去之后删除,然后重启浏览器,ctrl+shift+x打开xpath插件,作用如图(语法可以自行查看别人的博客):

开始爬虫
目的:爬取“美女图片”分类下的所有图片
这次爬虫主要就是用selenium驱动真实浏览器(可以无界面运行)对目标网站进行请求,然后得到网页源代码,通过xpath进行解析,得到目标图片的url以及名称
简单分析目标网站
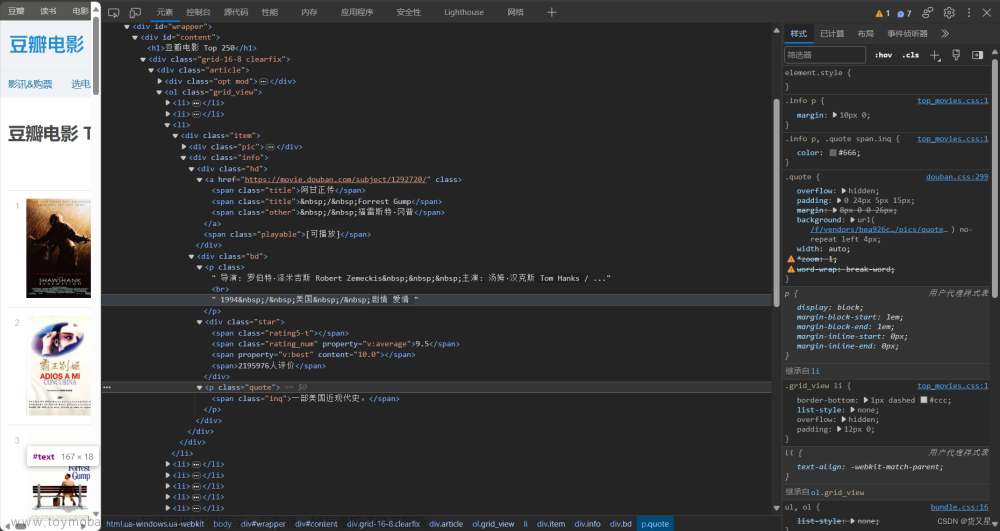
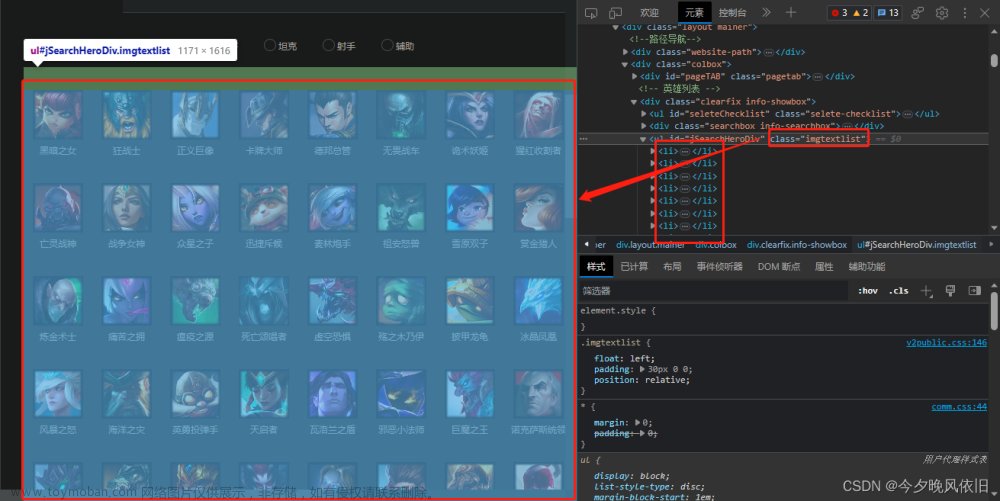
首先,进入想爬取的网站之后,找一个目标分类,F12打开开发者工具,选中一张图片,查看其所在源代码前面的标签,然后写出xpath解析
//img/@data-original
之后的名字也同样在一个标签下:
//img/@alt确定这两个xpath解析没有问题之后,然后再看一下 下一页的链接:
https://www.bizhi88.com/c1/2.html之后直接跳到最后:
https://www.bizhi88.com/c1/25.html但是有一个问题就是,刚开始进来的时候第一页的连接是:
https://www.bizhi88.com/c1/我感觉,这可能是个反爬吧hh,不过没关系,输入链接:
https://www.bizhi88.com/c1/1/html之后我发现还是可以访问第一页
那就不管了,反正selenium可以驱动无界面浏览器。
写函数
获取浏览器对象:
注意path要改成你的浏览器的路径
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
def get_browser():
chrome_options = Options()
chrome_options.add_argument('--headless')
chrome_options.add_argument('--disable-gpu')
path = r'C:\Program Files\Google\Chrome\Application\chrome.exe'
chrome_options.binary_location = path
bro = webdriver.Chrome(chrome_options=chrome_options)
return bro下载每一张图片:
import urllib.request
def download_img(url, name):
urllib.request.urlretrieve(url, name)url是每一张图片的地址,name是刚刚说的alt下的文本
获取每一页的源代码:
from lxml import etree
def print_result_every_page(index):
browser = get_browser()
browser.get(base_url+str(index)+'.html')
content = browser.page_source
tree = etree.HTML(content)
result = tree.xpath('//img/@data-original')
name = tree.xpath('//img/@alt')
for le in range(0, len(result)):
print("downloading:"+name[i])
download_img(result[le], './downloads/'+name[le]+'.jpg')
print("Over!")
print()base_url 是一个全局变量
base_url = 'https://www.bizhi88.com/c1/'index是传入的页码
至于download_img(result[le], './downloads/'+name[le]+'.jpg')中的文件名:
./downloads是将下载的图片存在和代码文件同一目录下的文件夹中,以便管理文章来源:https://www.toymoban.com/news/detail-453907.html
运行print_result_every_page
for i in range(1, 26):
print('downloading page' + str(i))
print_result_every_page(i)
print("ALL OVER!!!")
建议看的爬虫网课文章来源地址https://www.toymoban.com/news/detail-453907.html
到了这里,关于selenium爬虫框架爬取某壁纸网站的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!