一、Requests库下载地址
requests · PyPI

将下载的.whl文件放在Script目录下

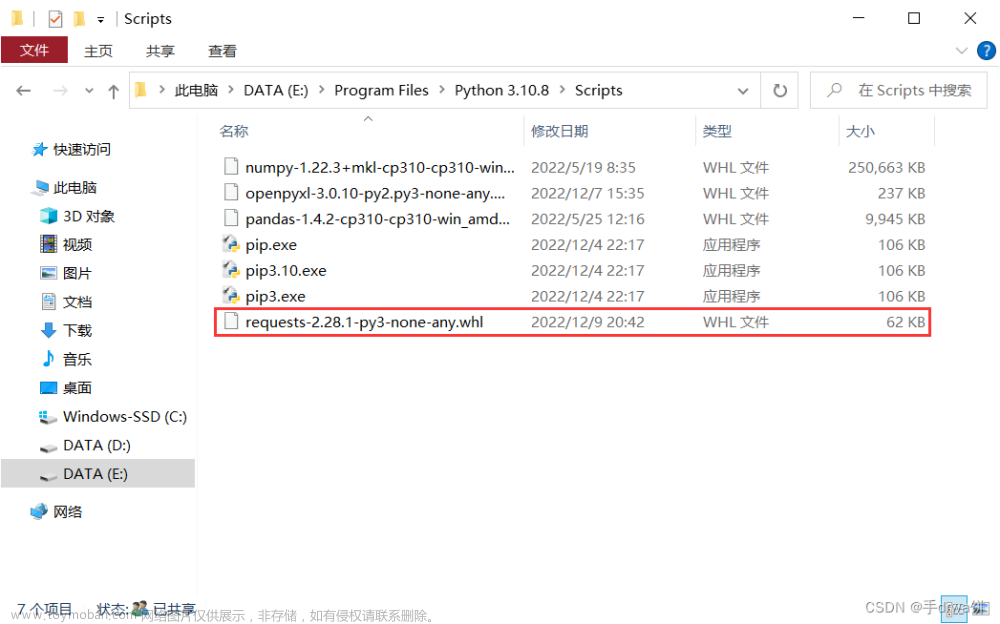
win+r 输入cmd 进入windows控制台
进入到Scripts目录
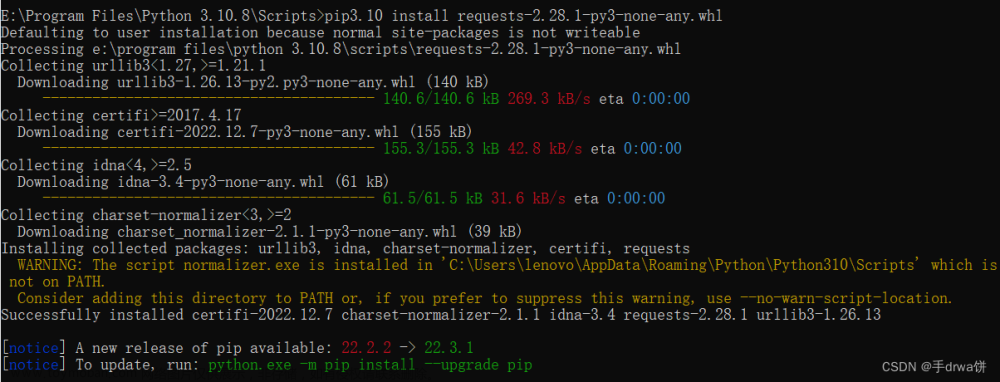
输入pip3.10 install requests-2.28.1-py3-none-any.whl(文件的名称)
出现Successful install即安装成功
二、BS4解析库的下载和安装
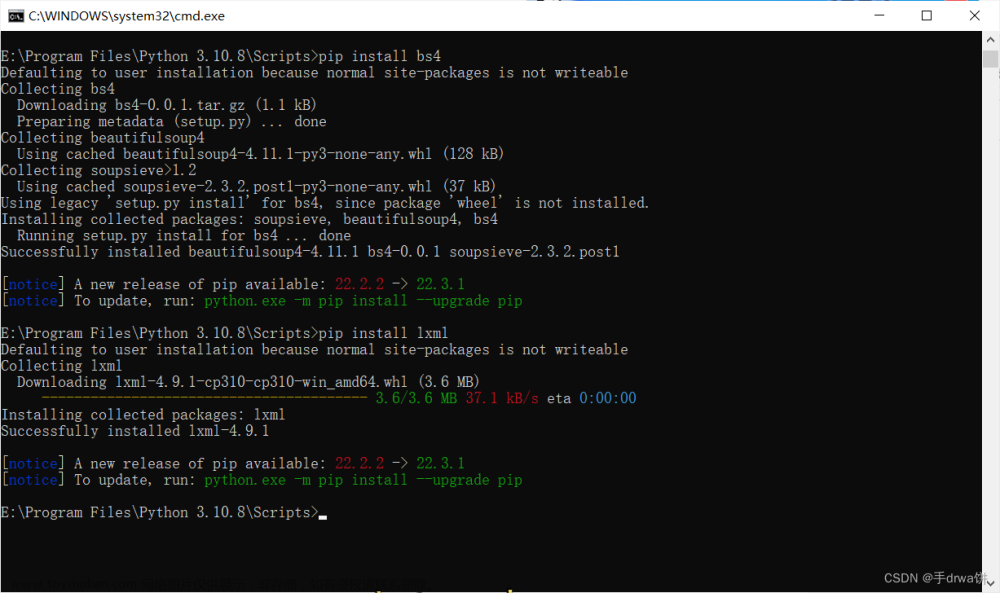
进入到scripts目录
pip install bs4
由于 BS4 解析页面时需要依赖文档解析器,所以还需要安装 lxml 作为解析库:
pip install lxml
文章来源地址https://www.toymoban.com/news/detail-453959.html文章来源:https://www.toymoban.com/news/detail-453959.html
到了这里,关于Python爬虫之Requests库、BS4解析库的下载和安装的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!