YOLOV5介绍
YOLOV5是目前最火热的目标检测算法之一。YOLOV5为一阶段检测算法因此它的速度非常之快。可以在复杂场景中达到60祯的实时检测频率。
接下来本文将详细的讲述如何使用YOLOV5去训练自己的数据集
一、下载YOLOv5开源代码
$ git clone https://github.com/ultralytics/yolov5.git
$ cd yolov5
$ pip install -r requirements.txt
YOLOV5中使用了Tensorboard和Wandb来可视化训练,其中Wandb配置可以看这篇文章:
Wandb安装与配置
二、构建YOLO数据集
数据集地址:MaskDetecion
下载好数据集之后将数据集解压到YOLOV5项目文件夹下的DataSets目录下(需要先新建一个DataSets文件夹)
划分数据集
将数据集划分为训练集、验证集、测试集:
# coding:utf-8
#划分数据集
import os
import random
import argparse
parser = argparse.ArgumentParser()
#xml文件的地址,根据自己的数据进行修改 xml一般存放在Annotations下
parser.add_argument('--xml_path', default='./DataSets/annotations', type=str, help='xml path')
#数据集划分后txt文件的存储地址,地址选择自己数据下的ImageSets/Main
parser.add_argument('--txt_path', default='./DataSets/ImageSets/Main', type=str, help='output txt label path')
opt = parser.parse_args()
trainval_percent = 0.9 #训练集和验证集的比例
train_percent = 0.9 #训练集占总数据的比例
imgfilepath = opt.img_path
txtsavepath = opt.txt_path
total_xml = os.listdir(imgfilepath)
if not os.path.exists(txtsavepath):
os.makedirs(txtsavepath)
num = len(total_xml)
list_index = range(num)
tv = int(num * trainval_percent)
tr = int(tv * train_percent)
trainval = random.sample(list_index, tv)
train = random.sample(trainval, tr)
#划分生成的文件名称
file_trainval = open(txtsavepath + '/trainval.txt', 'w')
file_test = open(txtsavepath + '/test.txt', 'w')
file_train = open(txtsavepath + '/train.txt', 'w')
file_val = open(txtsavepath + '/val.txt', 'w')
for i in list_index:
name = total_xml[i][:-4] + '\n'
if i in trainval:
file_trainval.write(name)
if i in train:
file_train.write(name)
else:
file_val.write(name)
else:
file_test.write(name)
file_trainval.close()
file_train.close()
file_val.close()
file_test.close()
划分完成之后会生成以下文件:
每个txt中的内容为xml的文件名:
生成YOLO格式的label
转换xml为txt
import xml.etree.ElementTree as ET
import pickle
import os
from os import listdir, getcwd
from os.path import join
import shutil
#VOC生成txt的文件
sets = ['train', 'val', 'test'] #数据集,最后会生成以这三个数据集命名的txt文件
classes = ['with_mask', 'without_mask', 'mask_weared_incorrect'] #标签名,注意一定不要出错
def convert(size, box):
dw = 1. / size[0]
dh = 1. / size[1]
x = (box[0] + box[1]) / 2.0
y = (box[2] + box[3]) / 2.0
w = box[1] - box[0]
h = box[3] - box[2]
x = x * dw
w = w * dw
y = y * dh
h = h * dh
return (x, y, w, h)
def convert_annotation(image_id):
in_file = open('./DataSets/annotations/%s.xml' % (image_id), 'r', encoding="UTF-8")
out_file = open('./DataSets/labels/%s.txt' % (image_id), 'w')
tree = ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult) == 1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),
float(xmlbox.find('ymax').text))
bb = convert((w, h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
for image_set in sets:
if not os.path.exists('./DataSets/labels/'): #创建label文件夹
os.makedirs('./DataSets/labels/')
image_ids = open('./DataSets/ImageSets/Main/%s.txt' % (image_set)).read().strip().split()
list_file = open('./DataSets/%s.txt' % (image_set), 'w')
for image_id in image_ids:
list_file.write('S:/pythonProjects/DSA/MaskDetection/yolov5/DataSets/images/%s.png\n' % (image_id)) #这里最好用全局路径
convert_annotation(image_id)
list_file.close()
运行结束后会生成label文件夹和划分后三个数据集的具体文件路径
label中是转换出来的yolo格式数据集,分别为:标签类别,x:中心点x值/图片宽度,y:中心点y值/图片高度,w:目标框的宽度/图片宽度,h:目标框的高度/图片高度。
详情可参考博客:YOLO数据集标注
而生成的三个txt相当于在之前划分的数据集上加上了路径,方便直接读取
新建一个数据集配置文件
在data文件夹下新建一个mask.yaml文件,用来写数据集的一些配置,后续代码中也是通过读取yaml来读取数据集
#数据集的路径,推荐用绝对路径
train: S:/pythonProjects/DSA/MaskDetection/yolov5/DataSets/train.txt
val: S:/pythonProjects/DSA/MaskDetection/yolov5/DataSets/val.txt
test: S:/pythonProjects/DSA/MaskDetection/yolov5/DataSets/test.txt
nc: 3 #分类个数
names: ['with_mask;', 'without_mask', 'mask_weared_incorrect'] #标签
至此,数据集制作就结束了。
三、修改训练文件
修改训练的一些参数(由于github上项目一直在更新,不同的版本的参数可能不同,比如我最新下载这个没有freeze这个冻结参数的选项了。但最重要的几个一直都有)
parser = argparse.ArgumentParser()
parser.add_argument('--weights', type=str, default='yolov5s.pt', help='initial weights path')
#权重文件,在第一次训练时,YOLOV5提供了几个不同的预训练模型,详情:https://github.com/ultralytics/yolov5
#可以提前去官网下载,如果没有提前下载也没关系,这里只要写上预训练模型的名称,会自动调用项目中的download.sh去下载权重。
#当然也可以不使用预训练,这里设置为空就行;
parser.add_argument('--cfg', type=str, default='yolov5s.yaml', help='model.yaml path')
#模型参数的配置文件,里面指定了一些参数信息和backbone的结构信息。需要跟选择的预训练模型一致。
parser.add_argument('--data', type=str, default='data/mask.yaml', help='data.yaml path') #数据集地址
parser.add_argument('--hyp', type=str, default='data/hyp.scratch.yaml', help='hyperparameters path')
#模型训练的初始超参数文件,同样也提供了其他训练的超参数文件,可以自行选择
parser.add_argument('--epochs', type=int, default=300)
#训练轮数,相当于0-299
parser.add_argument('--batch-size', type=int, default=16, help='total batch size for all GPUs')
#每次送入的样本量,数据集总数/batch_size就是每一轮总共要迭代的次数,越大效果越好。default=-1将时自动调节batchsize大小。
#顺便说一下epoch、batchsize、iteration三者之间的联系 1、batchsize是批次大小,假如取batchsize=24,则表示每次训练时在训练集中取24个训练样本进行训练。 2、iteration是迭代次数,1个iteration就等于一次使用24(batchsize大小)个样本进行训练。 3、epoch:1个epoch就等于使用训练集中全部样本训练1次。
parser.add_argument('--img-size', nargs='+', type=int, default=[640, 640], help='[train, test] image sizes')
#resize的图片大小,一般来说640就够了,原图都比较大,如果直接上原图会导致过度消耗GPU资源,但如果选择比较大的模型,也要跟着上调。
parser.add_argument('--rect', action='store_true', help='rectangular training')
#是否采用矩阵推理的方式去训练模型;所谓矩阵推理就是不再要求你训练的图片是正方形了;矩阵推理会加速模型的推理过程,减少一些冗余信息。
parser.add_argument('--resume', nargs='?', const=True, default=False, help='resume most recent training')
#恢复训练:在之前训练的一个模型基础上继续训练,比如第一次训练了100个epoch,后续想在第一次训练的模型的基础上继续训练100个epoch则这里改成true。或者是训练中出现报错而中断,也可以用resume继续训练。
parser.add_argument('--nosave', action='store_true', help='only save final checkpoint')
#是否只保存最后一轮训练的模型,这个参数不推荐,因为默认的是同时保存best和last
parser.add_argument('--notest', action='store_true', help='only test final epoch')
#只在最后一轮测试(这里说的应该是验证);正常情况下每个epoch都会进行验证计算mAP,但如果开启了这个参数,那么就只在最后一轮上进行测试,不建议开启。
parser.add_argument('--noautoanchor', action='store_true', help='disable autoanchor check')
#是否禁用自动锚框;不建议改动,默认是开启的,自动锚点的好处是可以简化训练过程;yolov5中预先设定了一下锚定框,这些锚框是针对coco数据集的,其他目标检测也适用,可以在models/yolov5.文件中查看。
#需要注意的是在目标检测任务中,一般使用大特征图上去检测小目标,因为大特征图含有更多小目标信息,因此大特征图上的anchor数值通常设置为小数值,小特征图检测大目标,因此小特征图上anchor数值设置较大。
#训练开始前,会自动计算数据集标注信息针对默认锚定框的最佳召回率,当最佳召回率大于等于0.98时,则不需要更新锚定框;如果最佳召回率小于0.98,则需要重新计算符合此数据集的锚定框。
parser.add_argument('--evolve', action='store_true', help='evolve hyperparameters')
#遗传超参数进化;yolov5使用遗传超参数进化,提供的默认参数是通过在COCO数据集上使用超参数进化得来的。由于超参数进化会耗费大量的资源和时间,所以建议大家不要动这个参数。
parser.add_argument('--bucket', type=str, default='', help='gsutil bucket')
#是否使用一些类似于阿里云之类的云盘来上传或下载东西,一般不用设置
parser.add_argument('--cache-images', action='store_true', help='cache images for faster training')
#是否提前缓存图片到内存,以加快训练速度,推荐设置。
parser.add_argument('--image-weights', action='store_true', help='use weighted image selection for training')
#是否启用加权图像策略,可以解决样本不平衡问题;开启后会对于上一轮训练效果不好的图片,在下一轮中增加一些权重;
parser.add_argument('--device', default='', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
#训练设备,一般电脑只有一张显卡默认为0,但如果使用多卡的服务器进行训练,这里可以选择0,1,2,3分别对应卡号,多选就是多卡训练。
parser.add_argument('--multi-scale', action='store_true', help='vary img-size +/- 50%%')
#是否使用多尺度训练:多尺度训练是指设置几种不同的图片输入尺度,训练时每隔一定iterations随机选取一种尺度训练,这样训练出来的模型鲁棒性更强。
#多尺度训练在比赛中经常可以看到他身影,是被证明了有效提高性能的方式。输入图片的尺寸对检测模型的性能影响很大,在基础网络部分常常会生成比原图小数十倍的特征图,导致小物体的特征描述不容易被检测网络捕捉。通过输入更大、更多尺寸的图片进行训练,能够在一定程度上提高检测模型对物体大小的鲁棒性。
parser.add_argument('--single-cls', action='store_true', help='train multi-class data as single-class')
#单分类;如果你的任务只需要检测一个类别则这里可以设置为True
parser.add_argument('--adam', action='store_true', help='use torch.optim.Adam() optimizer')
#选择优化器;比如SGD,Adam,AdamW等等,默认为adam(不同版本的代码默认不一样)。
parser.add_argument('--sync-bn', action='store_true', help='use SyncBatchNorm, only available in DDP mode')
#是否开启跨卡同步BN;开启参数后即可使用 SyncBatchNorm多GPU 进行分布式训练
parser.add_argument('--local_rank', type=int, default=-1, help='DDP parameter, do not modify')
#DDP参数,不要修改
parser.add_argument('--workers', type=int, default=8, help='maximum number of dataloader workers')
#dataloader使用多线程来加载数据,提前加载未来会用到的batch数据,详情可参考:https://www.cnblogs.com/hesse-summer/p/11343870.html
parser.add_argument('--project', default='runs/train', help='save to project/name')
#训练文件的保存路径,不用修改,项目中默认的保存结构非常好看。
parser.add_argument('--entity', default=None, help='W&B entity')
#在线可视化工具,类似于tensorboard,不推荐使用,yoloV5中同时使用了Tensorboard和Wandb两个在线可视化工具已经非常冗余了。
parser.add_argument('--name', default='exp', help='save to project/name')
#每一轮迭代的文件夹名称,这里不用修改,后续训练会自动增加:exp,exp2,exp3,exp4...
parser.add_argument('--exist-ok', action='store_true', help='existing project/name ok, do not increment')
#每次预测模型的结果是否保存在原来的文件夹;如果指定了这个参数的话,那么本次预测的结果还是保存在上一次保存的文件夹里;如果不指定就是每次预测结果保存一个新的文件夹下。
parser.add_argument('--quad', action='store_true', help='quad dataloader')
#在比默认640 大的数据集上训练效果更好,副作用是在 640 大小的数据集上训练效果可能会差一些,详情可参考:https://blog.csdn.net/a18838956649/article/details/119020699
parser.add_argument('--linear-lr', action='store_true', help='linear LR')
#线性学习率,有的项目是cos-lr,开启后学习率会动态的变化,推荐开启。
parser.add_argument('--upload_dataset', action='store_true', help='Upload dataset as W&B artifact table')
#是否上传数据集到wandb中,如果想要更好的看到数据集的情况可以开启。
parser.add_argument('--bbox_interval', type=int, default=-1, help='Set bounding-box image logging interval for W&B')
#设置界框图像记录间隔,也是和wandb有关,一般用不到
parser.add_argument('--save_period', type=int, default=-1, help='Log model after every "save_period" epoch')
#用于设置多少个epoch保存一下checkpoint;
parser.add_argument('--artifact_alias', type=str, default="latest", help='version of dataset artifact to be used')
#要使用的数据集工件的版本,暂时还没看到这里的一些先关说明。
opt = parser.parse_args()
其中action='store_true’的参数默认是不开启的,在shell只需要键入这个参数的名称,不需要加值就可以开启,这类一般是True或False的选项,如果想在编译器中使用这个参数,则可以加一个default=True
推荐参数:
python train.py --weights yolov5s.pt --cfg yolov5s.yaml --data data/mask.yaml --epochs 500 --cache-images --image-weights --multi-scale --linear-lr
四、训练中遇到的一些报错问题
编码报错
‘gbk’ codec can’t decode byte 0xaf in position 15: illegal multitype sequence
解决方案:在trian.py中这个位置的open中加上utf-8的编码,test.py中也有这个错误,可以一起加上,可能是个bug,不知道官方为什么还没改过来。
找不到数据集或标签
AssertionError: No trains in D:\yolov5\train_data\train.cache. Can not train without trains.
AssertionError: No labels in D:\yolov5\train_data\train.cache. Can not train without labels.
这个错误很常见,根本原因还是数据集配置有问题,首先检查你数据集的data.yaml里面所有路径是否正确,其次检查train.txt、test.txt里面的路径是否正确,如果这些都没问题的话那就改接下来这处地方:
在utils里面的datasets.py中搜索define找到这个函数,将这里的images改成和你datasets目录下存储图片的文件夹的名字一样,比如你存储图片的文件夹叫JPEGImages,那么这里也要改成JPEGImages

libiomp5md.dll错误
这个报错是由于anaconda下存在多个libiomp5md.dll文件导致的,有两种解决方法:
- 删除anaconda对应环境中Libary文件夹下libiomp5md.dll文件,再运行项目时会自动生成一个libiomp5md.dll文件
- 在train.py中加上这句话,允许多个lib文件同时运行
os.environ['KMP_DUPLICATE_LIB_OK']='TRUE'
libpng warning: iCCP
libpng warning: iCCP: known incorrect sRGB profile
这个错误可能是由于一些图片中存在错误格式,且anaconda的libpng版本过高导致的,解决的方法大致有两种:
1.替换掉anaconda中的库,详情可以查看这篇文章并且他提供了一个不会报错的版本。
替换anaconda中的libpng库
2.将所有数据集中的图片重新编码一下,代码如下:
import os
from tqdm import tqdm
import cv2
from skimage import io
path = r"./images/" #path后面记得加 /
fileList = os.listdir(path)
for i in tqdm(fileList):
image = io.imread(path+i) # image = io.imread(os.path.join(path, i))
image = cv2.cvtColor(image, cv2.COLOR_RGBA2BGRA)
cv2.imencode('.png',image)[1].tofile(path+i)
五、测试
测试文件为test.py,大部分参数解释和train是一样的,其实train.py中的验证代码用的就是test.py中的内容,这里做测试的话只需要把–task这个参数改成test就行
六、训练、测试结果
在训练、测试结束后会生成很多文件,这里来大致解析一下这些文件分别是什么意思:
我的保存路径在train下面,exp就是第一轮训练的结果,其中weights文件夹下面是训练生成的权重文件,也可以说是模型,best.pt是表现最好的模型,last.pt是最后一轮生成的模型
比较重要的是result.png里面是模型整体训练的一个情况,从这里能看到绝大部分信息。
接下来是一些分类问题的评分指标:confusion_martix.png、F1_curve.png、P_curve.png、R_curve.png、PR_curve.png
两个参数文件:hyp.yaml/opt.yaml分别是模型的初始参数以及训练的初始超参数
三个events…为tensorboard的日志文件
train_batch\test_batch分别为训练和测试前三个batch的结果后缀为labels为标签,pred为预测的情况,可以从这里大致看出模型的一个实际效果。
七、检测
检测文件为detect.py,只需要提供你想要检测的内容,包括图片、视频、调用摄像头,这个参数为
–source,给一个路径或者0,0为调用摄像头
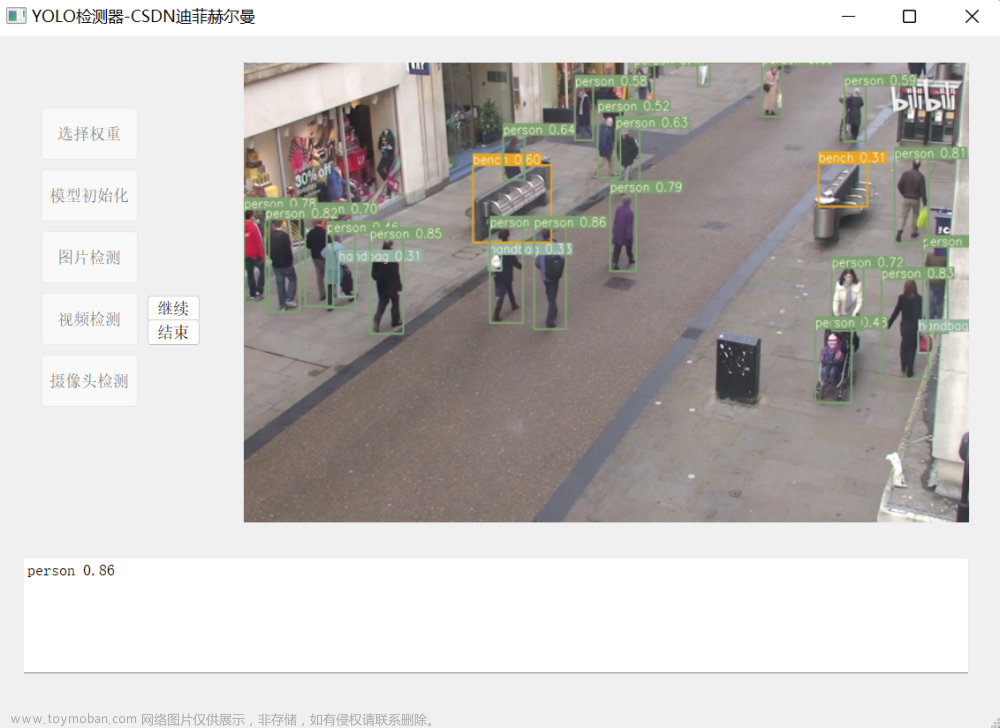
这是我实时检测的效果,可以说还不错
这次关于YOLOV5的训练步骤就结束了,如有错误请及时指正,后续还会继续更新一些相关的知识,感谢观看!文章来源:https://www.toymoban.com/news/detail-454192.html
References
https://blog.csdn.net/xiaosangtongxue/article/details/124083959
https://zhuanlan.zhihu.com/p/549163975
https://blog.csdn.net/banyueju/article/details/91553248?utm_medium=distribute.pc_relevant.none-task-blog-BlogCommendFromBaidu-2.control&depth_1-utm_source=distribute.pc_relevant.none-task-blog-BlogCommendFromBaidu-2.control
https://qichenxi.blog.csdn.net/article/details/124234388?spm=1001.2014.3001.5506
https://blog.csdn.net/qq_44785351/article/details/127465183?spm=1001.2014.3001.5502
https://blog.csdn.net/banyueju/article/details/91553248?utm_medium=distribute.pc_relevant.none-task-blog-BlogCommendFromBaidu-2.control&depth_1-utm_source=distribute.pc_relevant.none-task-blog-BlogCommendFromBaidu-2.control文章来源地址https://www.toymoban.com/news/detail-454192.html
到了这里,关于手把手教你如何使用YOLOV5训练自己的数据集的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!