VGG16原理
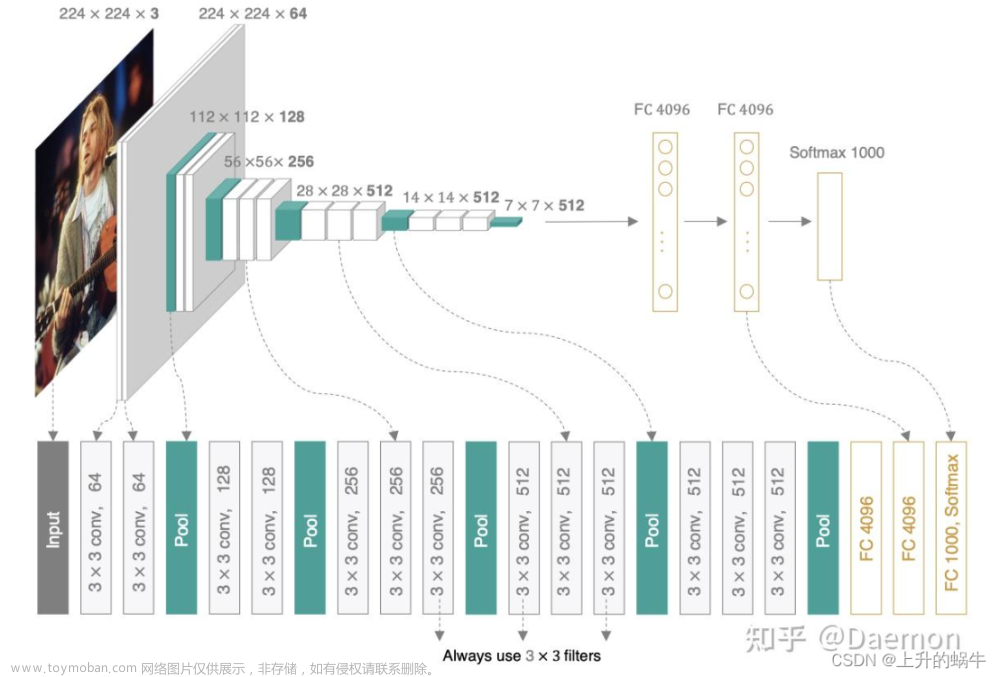
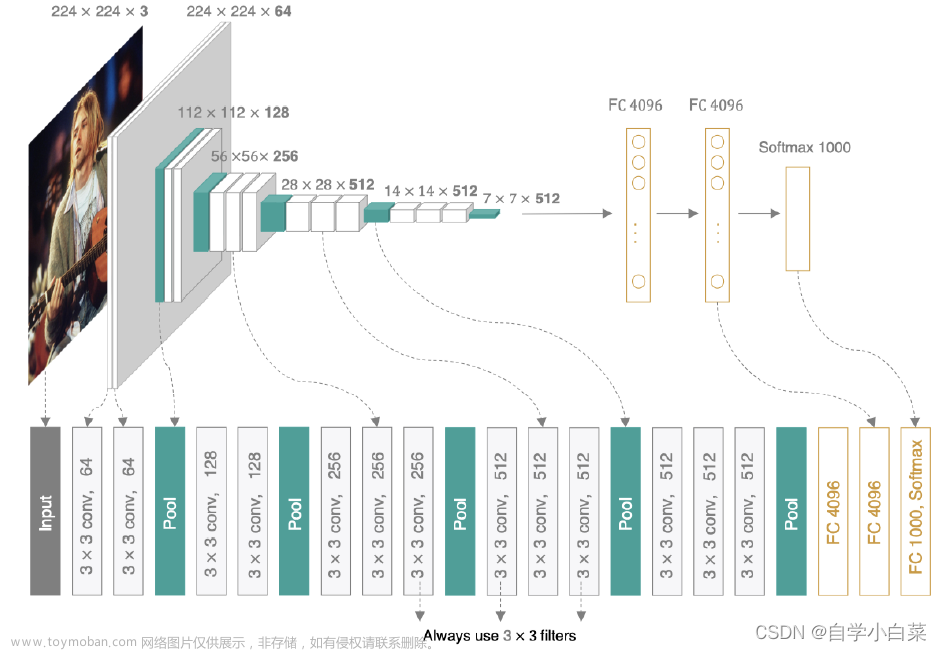
VGG16是一个经典的卷积神经网络模型,由牛津大学计算机视觉组(Visual Geometry Group)提出,用于参加2014年的ImageNet图像分类比赛。VGG16的名称来源于网络中包含的16个卷积层,其基本结构如下:
- 输入层:接收大小为224x224的RGB图像。
- 卷积层:共13个卷积层,每个卷积层使用3x3的卷积核和ReLU激活函数,提取图像的局部特征。
- 池化层:共5个池化层,每个池化层使用2x2的池化核和步长2,减小特征图的大小。
- 全连接层:包含2个全连接层,每个全连接层包含4096个神经元,用于分类输出。
- 输出层:包含一个大小为1000的全连接层,使用softmax激活函数,生成1000个类别的概率分布。


VGG16的主要特点是网络结构比较深,且卷积层和池化层的数量都比较多,使得网络可以学习到更加高层次的抽象特征。此外,VGG16的卷积层都采用3x3的卷积核,这样可以保证在不增加计算量的情况下,增加了网络的深度和宽度,提高了特征提取的效率和准确性。
在训练过程中,VGG16一般采用基于随机梯度下降(Stochastic Gradient Descent,SGD)的反向传播算法,通过最小化交叉熵损失函数来优化模型参数。在训练过程中,可以使用数据增强、正则化、dropout等技术来提高模型的泛化能力和鲁棒性。
总的来说,VGG16是一个非常经典和有效的卷积神经网络模型,具有良好的特征提取和分类能力,可以应用于图像分类、目标检测等计算机视觉任务。文章来源:https://www.toymoban.com/news/detail-454224.html
VGG16源码(tensorflow版)
import tensorflow as tf
from tensorflow.keras import optimizers,losses,models,datasets,Sequential
from tensorflow.keras.layers import Dense,Conv2D,BatchNormalization,MaxPooling2D,Flatten
class vgg16(models.Model):
def __init__(self):
super(vgg16, self).__init__()
self.model = models.Sequential([
Conv2D(filters=64,kernel_size=(3,3),padding='same',activation='relu'),
Conv2D(filters=64,kernel_size=(3,3),padding='same',activation='relu'),
BatchNormalization(),
MaxPooling2D(),
Conv2D(filters=128,kernel_size = (3,3),padding='same',activation='relu'),
Conv2D(filters=128,kernel_size = (3,3),padding='same',activation='relu'),
BatchNormalization(),
MaxPooling2D(),
Conv2D(filters=256, kernel_size=(3, 3),padding='same', activation='relu'),
Conv2D(filters=256, kernel_size=(3, 3),padding='same', activation='relu'),
Conv2D(filters=256, kernel_size=(3, 3),padding='same', activation='relu'),
BatchNormalization(),
MaxPooling2D(),
Conv2D(filters=512, kernel_size=(3, 3),padding='same', activation='relu'),
Conv2D(filters=512, kernel_size=(3, 3), padding='same',activation='relu'),
Conv2D(filters=512, kernel_size=(3, 3), padding='same',activation='relu'),
BatchNormalization(),
MaxPooling2D(),
Conv2D(filters=512, kernel_size=(3, 3), padding='same',activation='relu'),
Conv2D(filters=512, kernel_size=(3, 3),padding='same', activation='relu'),
Conv2D(filters=512, kernel_size=(3, 3), padding='same',activation='relu'),
BatchNormalization(),
MaxPooling2D(),
Flatten(),
Dense(512,activation='relu'),
Dense(256,activation='relu'),
Dense(10,activation='softmax')
])
def call(self, x, training=None, mask=None):
x = self.model(x)
return x
def main():
(train_x,train_y),(test_x,test_y) = datasets.cifar10.load_data()
train_x = train_x.reshape(-1,32,32,3) / 255.0
test_x = test_x.reshape(-1,32,32,3) / 255.0
model = vgg16()
# model.build((None,32,32,3))
# model.summary() 不使用类写VGG的话,就不报错,使用了类写VGG就报错,我也很无奈
model.compile(optimizer=optimizers.Adam(0.01),
loss = losses.SparseCategoricalCrossentropy(),
metrics=['accuracy'])
model.fit(train_x,train_y,epochs=10,batch_size=128)
score = model.evaluate(test_x,test_y,batch_size=50)
print('loss:',score[0])
print('acc:',score[1])
pass
if __name__ == '__main__':
main()训练10个epoch的效果
 文章来源地址https://www.toymoban.com/news/detail-454224.html
文章来源地址https://www.toymoban.com/news/detail-454224.html
到了这里,关于VGG16详细原理(含tensorflow版源码)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!