剪枝和知识蒸馏均属于模型轻量化设计,剪枝是将已有网络通过剪枝的手段得到轻量化网络,可分为非结构化剪枝和结构化剪,该技术可以免去人为设计轻量网络,而是通过计算各个权重或者通道的贡献度大小,剪去贡献度小的权重或通道,再经过微调训练恢复精度,得到最终的模型,这种方法自然也是可以的,但在某些任务中,如果剪枝较多效果会很差,即便微调训练也恢复不了多少精度。
本文所用到的剪枝是通道剪枝(结构化剪枝),可以参考我另外一篇博客(这篇文章被多个开源社区收藏,所以值得一试):YOLOv5通道剪枝,同时在我其他博客中还实现了YOLOV4,YOLOX,YOLOR,YOLOV7等剪枝,欢迎点赞收藏。
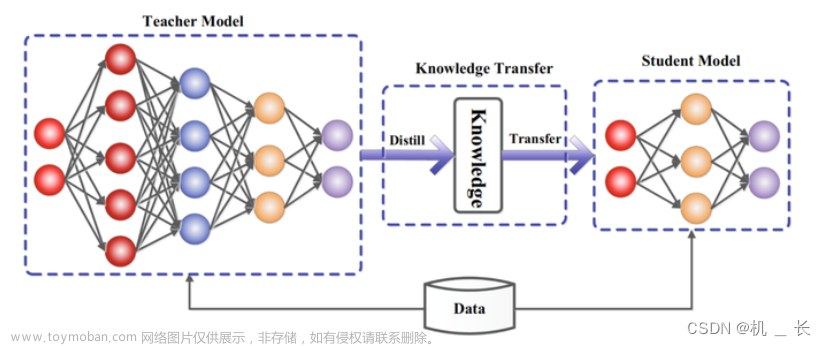
知识蒸馏是在一个精度高的大模型和一个精度低的小模型之间建立损失函数,将大模型"压缩"到小模型中【并不是严格意义上的压缩】。这也是近两年用的比较多的手段,之前的知识的蒸馏均是在分类网络中进行,现在也开始应用于目标检测。分类网络的知识蒸馏可以参考:知识蒸馏,自蒸馏
目标检测的知识蒸馏参考:SSD知识蒸馏
知识蒸馏的蒸馏方式有在线式和离线式,还可分为特征蒸馏和逻辑蒸馏。在这里我公布的代码是离线式的逻辑蒸馏。
目录
项目说明
环境说明
1.训练自己的数据集
2.对任意卷积层进行剪枝
3.剪枝后的训练
4.剪枝后的模型预测
5.知识蒸馏训练
代码
项目说明
1.训练自己的数据集
2.对任意卷积层进行剪枝
3.剪枝后的训练
4.剪枝后的模型预测
5.利用知识蒸馏对剪枝后模型进行训练
环境说明
gitpython>=3.1.30
matplotlib>=3.3
numpy>=1.18.5
opencv-python>=4.1.1
Pillow>=7.1.2
psutil # system resources
PyYAML>=5.3.1
requests>=2.23.0
scipy>=1.4.1
thop>=0.1.1 # FLOPs computation
torch>=1.7.0 # see https://pytorch.org/get-started/locally (recommended)
torchvision>=0.8.1
tqdm>=4.64.0
ultralytics>=8.0.100
torch_pruning==0.2.7
pandas>=1.1.4
seaborn>=0.11.0
1.训练自己的数据集
将自己制作好的数据集放在dataset文件下,目录形式如下:
dataset
|-- Annotations
|-- ImageSets
|-- images
|-- labels
Annotations是存放xml标签文件的,images是存放图像的,ImageSets存放四个txt文件【后面运行代码的时候会自动生成】,labels是将xml转txt文件。
1.运行makeTXT.py。这将会在ImageSets文件夹下生成 trainval.txt,test.txt,train.txt,val.txt四个文件【如果你打开这些txt文件,里面仅有图像的名字】。
2.打开voc_label.py,并修改代码 classes=[""]填入自己的类名,比如你的是训练猫和狗,那么就是classes=["dog","cat"],然后运行该程序。此时会在labels文件下生成对应每个图像的txt文件,形式如下:【最前面的0是类对应的索引,我这里只有一个类,后面的四个数为box的参数,均归一化以后的,分别表示box的左上和右下坐标,等训练的时候会处理成center_x,center_y,w, h】。形式如下。
0 0.4723557692307693 0.5408653846153847 0.34375 0.8990384615384616
0 0.8834134615384616 0.5793269230769231 0.21875 0.8221153846153847
3.在data文件夹下新建一个mydata.yaml文件。内容如下【你也可以把coco.yaml复制过来】。
你只需要修改nc以及names即可,nc是类的数量,names是类的名字。
train: ./dataset/train.txt
val: ./dataset/val.txt
test: ./dataset/test.txt# number of classes
nc: 1# class names
names: ['target']
4.终端输入参数,开始训练。
以yolov5s为例:
python train.py --weights yolov5s.pt --cfg models/yolov5s.yaml --data data/mydata.yamlfrom n params module arguments 0 -1 1 3520 models.common.Conv [3, 32, 6, 2, 2] 1 -1 1 18560 models.common.Conv [32, 64, 3, 2] 2 -1 1 18816 models.common.C3 [64, 64, 1] 3 -1 1 73984 models.common.Conv [64, 128, 3, 2] 4 -1 2 115712 models.common.C3 [128, 128, 2] 5 -1 1 295424 models.common.Conv [128, 256, 3, 2] 6 -1 3 625152 models.common.C3 [256, 256, 3] 7 -1 1 1180672 models.common.Conv [256, 512, 3, 2] 8 -1 1 1182720 models.common.C3 [512, 512, 1] 9 -1 1 656896 models.common.SPPF [512, 512, 5] 10 -1 1 131584 models.common.Conv [512, 256, 1, 1] 11 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest'] 12 [-1, 6] 1 0 models.common.Concat [1] 13 -1 1 361984 models.common.C3 [512, 256, 1, False] 20 -1 1 296448 models.common.C3 [256, 256, 1, False] 21 -1 1 590336 models.common.Conv [256, 256, 3, 2] 22 [-1, 10] 1 0 models.common.Concat [1] 23 -1 1 1182720 models.common.C3 [512, 512, 1, False] 24 [17, 20, 23] 1 16182 models.yolo.Detect [1, [[10, 13, 16, 30, 33, 23], [30, 61, 62, 45, 59, 119], [116, 90, 156, 198, 373, 326]], [128, 256, 512]] Model Summary: 270 layers, 7022326 parameters, 7022326 gradients, 15.8 GFLOPs
Starting training for 300 epochs...
Epoch gpu_mem box obj cls labels img_size 0/299 0.589G 0.0779 0.03841 0 4 640: 6%|████▋ | 23/359 [00:23<04:15, 1.31it/s]
看到以上信息就开始训练了。
2.对任意卷积层进行剪枝
在利用剪枝功能前,需要安装一下剪枝的库。需要安装0.2.7版本,0.2.8有粉丝说有问题。剪枝时的一些log信息会自动保存在logs文件夹下,每个log的大小我设置的为1MB,如果有其他需要大家可以更改。
pip install torch_pruning==0.2.7
YOLOv5与我之前写过的剪枝不同,v5在训练保存后的权重本身就保存了完整的model,即用的是torch.save(model,...),而不是torch.save(model.state_dict(),...),因此不需要单独在对网络结构保存一次。
模型剪枝代码在tools/prunmodel.py。你只需要找到这部分代码进行修改:我这里是以剪枝整个backbone的卷积层为例,如果你要剪枝的是其他层按需修改.included_layers内就是你要剪枝的层。
"""
这里写要剪枝的层
"""
included_layers = []
for layer in model.model[:10]:
if type(layer) is Conv:
included_layers.append(layer.conv)
elif type(layer) is C3:
included_layers.append(layer.cv1.conv)
included_layers.append(layer.cv2.conv)
included_layers.append(layer.cv3.conv)
elif type(layer) is SPPF:
included_layers.append(layer.cv1.conv)
included_layers.append(layer.cv2.conv)接下来在找到下面这行代码,amount为剪枝率,同样也是按需修改。【这里需要明白的一点,这里的剪枝率仅是对你要剪枝的所有层剪枝这么多,并不是把网络从头到尾全部剪,有些粉丝说我选了一层,剪枝率50%,怎么模型还那么大,没啥变化,这个就是他搞混了,他以为是对整个网络剪枝50%】。
pruning_plan = DG.get_pruning_plan(m, tp.prune_conv, idxs=strategy(m.weight, amount=0.8))接下来调用剪枝函数,传入参数为自己的训练好的权重文件路径。
layer_pruning('../runs/train/exp/weights/best.pt')见到如下形式,就说明剪枝成功了,剪枝以后的权重会保存在model_data下,名字为layer_pruning.pt。
这里需要说明一下,保存的权重文件中不仅包含了网络结构和权值内容,还有优化器的权值,如果仅仅保存网络结构和权值也是可以的,这样pt会更小一点,我这里默认都保存是为了和官方pt格式一致。
-------------
[ <DEP: prune_conv => prune_conv on model.9.cv2.conv (Conv2d(208, 512, kernel_size=(1, 1), stride=(1, 1), bias=False))>, Index=[0, 1, 2, 3, 7, 8, 10, 11, 12, 13, 16, 17, 18, 19, 21, 22, 23, 25, 27, 28, 29, 30, 31, 32, 33, 34, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50, 51, 53, 54, 56, 57, 58, 59, 60, 61, 62, 63, 65, 67, 69, 70, 71, 72, 73, 74, 76, 77, 78, 79, 80, 81, 82, 83, 84, 85, 86, 87, 89, 90, 91, 92, 95, 96, 97, 99, 100, 102, 103, 104, 105, 106, 107, 109, 110, 111, 113, 114, 115, 117, 118, 119, 120, 121, 122, 123, 124, 125, 126, 127, 128, 129, 130, 132, 133, 135, 137, 139, 142, 143, 144, 146, 148, 150, 152, 153, 154, 155, 156, 157, 158, 159, 161, 162, 163, 164, 165, 166, 167, 168, 169, 170, 171, 173, 174, 178, 179, 180, 181, 182, 183, 184, 185, 186, 187, 188, 189, 191, 192, 193, 194, 195, 196, 197, 198, 199, 200, 201, 202, 203, 204, 205, 206, 207, 208, 209, 210, 211, 212, 213, 215, 216, 217, 219, 220, 221, 222, 223, 224, 225, 226, 228, 229, 230, 232, 233, 234, 235, 236, 237, 239, 240, 241, 242, 243, 246, 247, 248, 249, 251, 252, 253, 254, 257, 258, 259, 260, 263, 264, 265, 266, 267, 268, 270, 271, 272, 273, 274, 275, 276, 277, 278, 280, 281, 282, 283, 284, 285, 286, 287, 288, 292, 293, 294, 295, 296, 297, 299, 301, 302, 303, 306, 307, 308, 309, 310, 311, 312, 313, 314, 315, 317, 318, 321, 322, 323, 324, 325, 326, 327, 329, 330, 331, 332, 334, 335, 338, 339, 341, 342, 343, 344, 346, 347, 349, 351, 353, 354, 355, 356, 357, 358, 359, 361, 362, 363, 364, 365, 366, 368, 369, 370, 372, 373, 374, 375, 378, 379, 381, 382, 383, 385, 386, 387, 388, 389, 390, 391, 392, 393, 395, 396, 397, 398, 399, 401, 402, 403, 404, 405, 407, 408, 411, 413, 414, 415, 416, 418, 419, 420, 421, 422, 423, 425, 426, 427, 428, 429, 430, 431, 432, 433, 434, 435, 436, 437, 438, 440, 441, 442, 443, 444, 445, 446, 448, 449, 451, 452, 453, 454, 455, 456, 457, 458, 459, 461, 463, 465, 466, 468, 470, 472, 473, 474, 475, 476, 477, 478, 479, 480, 482, 483, 484, 485, 486, 487, 488, 490, 491, 492, 493, 494, 495, 496, 497, 498, 499, 500, 502, 503, 505, 506, 507, 510, 511], NumPruned=85072]
[ <DEP: prune_conv => prune_batchnorm on model.9.cv2.bn (BatchNorm2d(512, eps=0.001, momentum=0.03, affine=True, track_running_stats=True))>, Index=[0, 1, 2, 3, 7, 8, 10, 11, 12, 13, 16, 17, 18, 19, 21, 22, 23, 25, 27, 28, 29, 30, 31, 32, 33, 34, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50, 51, 53, 54, 56, 57, 58, 59, 60, 61, 62, 63, 65, 67, 69, 70, 71, 72, 73, 74, 76, 77, 78, 79, 80, 81, 82, 83, 84, 85, 86, 87, 89, 90, 91, 92, 95, 96, 97, 99, 100, 102, 103, 104, 105, 106, 107, 109, 110, 111, 113, 114, 115, 117, 118, 119, 120, 121, 122, 123, 124, 125, 126, 127, 128, 129, 130, 132, 133, 135, 137, 139, 142, 143, 144, 146, 148, 150, 152, 153, 154, 155, 156, 157, 158, 159, 161, 162, 163, 164, 165, 166, 167, 168, 169, 170, 171, 173, 174, 178, 179, 180, 181, 182, 183, 184, 185, 186, 187, 188, 189, 191, 192, 193, 194, 195, 196, 197, 198, 199, 200, 201, 202, 203, 204, 205, 206, 207, 208, 209, 210, 211, 212, 213, 215, 216, 217, 219, 220, 221, 222, 223, 224, 225, 226, 228, 229, 230, 232, 233, 234, 235, 236, 237, 239, 240, 241, 242, 243, 246, 247, 248, 249, 251, 252, 253, 254, 257, 258, 259, 260, 263, 264, 265, 266, 267, 268, 270, 271, 272, 273, 274, 275, 276, 277, 278, 280, 281, 282, 283, 284, 285, 286, 287, 288, 292, 293, 294, 295, 296, 297, 299, 301, 302, 303, 306, 307, 308, 309, 310, 311, 312, 313, 314, 315, 317, 318, 321, 322, 323, 324, 325, 326, 327, 329, 330, 331, 332, 334, 335, 338, 339, 341, 342, 343, 344, 346, 347, 349, 351, 353, 354, 355, 356, 357, 358, 359, 361, 362, 363, 364, 365, 366, 368, 369, 370, 372, 373, 374, 375, 378, 379, 381, 382, 383, 385, 386, 387, 388, 389, 390, 391, 392, 393, 395, 396, 397, 398, 399, 401, 402, 403, 404, 405, 407, 408, 411, 413, 414, 415, 416, 418, 419, 420, 421, 422, 423, 425, 426, 427, 428, 429, 430, 431, 432, 433, 434, 435, 436, 437, 438, 440, 441, 442, 443, 444, 445, 446, 448, 449, 451, 452, 453, 454, 455, 456, 457, 458, 459, 461, 463, 465, 466, 468, 470, 472, 473, 474, 475, 476, 477, 478, 479, 480, 482, 483, 484, 485, 486, 487, 488, 490, 491, 492, 493, 494, 495, 496, 497, 498, 499, 500, 502, 503, 505, 506, 507, 510, 511], NumPruned=818]
[ <DEP: prune_batchnorm => _prune_elementwise_op on _ElementWiseOp()>, Index=[0, 1, 2, 3, 7, 8, 10, 11, 12, 13, 16, 17, 18, 19, 21, 22, 23, 25, 27, 28, 29, 30, 31, 32, 33, 34, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50, 51, 53, 54, 56, 57, 58, 59, 60, 61, 62, 63, 65, 67, 69, 70, 71, 72, 73, 74, 76, 77, 78, 79, 80, 81, 82, 83, 84, 85, 86, 87, 89, 90, 91, 92, 95, 96, 97, 99, 100, 102, 103, 104, 105, 106, 107, 109, 110, 111, 113, 114, 115, 117, 118, 119, 120, 121, 122, 123, 124, 125, 126, 127, 128, 129, 130, 132, 133, 135, 137, 139, 142, 143, 144, 146, 148, 150, 152, 153, 154, 155, 156, 157, 158, 159, 161, 162, 163, 164, 165, 166, 167, 168, 169, 170, 171, 173, 174, 178, 179, 180, 181, 182, 183, 184, 185, 186, 187, 188, 189, 191, 192, 193, 194, 195, 196, 197, 198, 199, 200, 201, 202, 203, 204, 205, 206, 207, 208, 209, 210, 211, 212, 213, 215, 216, 217, 219, 220, 221, 222, 223, 224, 225, 226, 228, 229, 230, 232, 233, 234, 235, 236, 237, 239, 240, 241, 242, 243, 246, 247, 248, 249, 251, 252, 253, 254, 257, 258, 259, 260, 263, 264, 265, 266, 267, 268, 270, 271, 272, 273, 274, 275, 276, 277, 278, 280, 281, 282, 283, 284, 285, 286, 287, 288, 292, 293, 294, 295, 296, 297, 299, 301, 302, 303, 306, 307, 308, 309, 310, 311, 312, 313, 314, 315, 317, 318, 321, 322, 323, 324, 325, 326, 327, 329, 330, 331, 332, 334, 335, 338, 339, 341, 342, 343, 344, 346, 347, 349, 351, 353, 354, 355, 356, 357, 358, 359, 361, 362, 363, 364, 365, 366, 368, 369, 370, 372, 373, 374, 375, 378, 379, 381, 382, 383, 385, 386, 387, 388, 389, 390, 391, 392, 393, 395, 396, 397, 398, 399, 401, 402, 403, 404, 405, 407, 408, 411, 413, 414, 415, 416, 418, 419, 420, 421, 422, 423, 425, 426, 427, 428, 429, 430, 431, 432, 433, 434, 435, 436, 437, 438, 440, 441, 442, 443, 444, 445, 446, 448, 449, 451, 452, 453, 454, 455, 456, 457, 458, 459, 461, 463, 465, 466, 468, 470, 472, 473, 474, 475, 476, 477, 478, 479, 480, 482, 483, 484, 485, 486, 487, 488, 490, 491, 492, 493, 494, 495, 496, 497, 498, 499, 500, 502, 503, 505, 506, 507, 510, 511], NumPruned=0]
[ <DEP: _prune_elementwise_op => _prune_elementwise_op on _ElementWiseOp()>, Index=[0, 1, 2, 3, 7, 8, 10, 11, 12, 13, 16, 17, 18, 19, 21, 22, 23, 25, 27, 28, 29, 30, 31, 32, 33, 34, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50, 51, 53, 54, 56, 57, 58, 59, 60, 61, 62, 63, 65, 67, 69, 70, 71, 72, 73, 74, 76, 77, 78, 79, 80, 81, 82, 83, 84, 85, 86, 87, 89, 90, 91, 92, 95, 96, 97, 99, 100, 102, 103, 104, 105, 106, 107, 109, 110, 111, 113, 114, 115, 117, 118, 119, 120, 121, 122, 123, 124, 125, 126, 127, 128, 129, 130, 132, 133, 135, 137, 139, 142, 143, 144, 146, 148, 150, 152, 153, 154, 155, 156, 157, 158, 159, 161, 162, 163, 164, 165, 166, 167, 168, 169, 170, 171, 173, 174, 178, 179, 180, 181, 182, 183, 184, 185, 186, 187, 188, 189, 191, 192, 193, 194, 195, 196, 197, 198, 199, 200, 201, 202, 203, 204, 205, 206, 207, 208, 209, 210, 211, 212, 213, 215, 216, 217, 219, 220, 221, 222, 223, 224, 225, 226, 228, 229, 230, 232, 233, 234, 235, 236, 237, 239, 240, 241, 242, 243, 246, 247, 248, 249, 251, 252, 253, 254, 257, 258, 259, 260, 263, 264, 265, 266, 267, 268, 270, 271, 272, 273, 274, 275, 276, 277, 278, 280, 281, 282, 283, 284, 285, 286, 287, 288, 292, 293, 294, 295, 296, 297, 299, 301, 302, 303, 306, 307, 308, 309, 310, 311, 312, 313, 314, 315, 317, 318, 321, 322, 323, 324, 325, 326, 327, 329, 330, 331, 332, 334, 335, 338, 339, 341, 342, 343, 344, 346, 347, 349, 351, 353, 354, 355, 356, 357, 358, 359, 361, 362, 363, 364, 365, 366, 368, 369, 370, 372, 373, 374, 375, 378, 379, 381, 382, 383, 385, 386, 387, 388, 389, 390, 391, 392, 393, 395, 396, 397, 398, 399, 401, 402, 403, 404, 405, 407, 408, 411, 413, 414, 415, 416, 418, 419, 420, 421, 422, 423, 425, 426, 427, 428, 429, 430, 431, 432, 433, 434, 435, 436, 437, 438, 440, 441, 442, 443, 444, 445, 446, 448, 449, 451, 452, 453, 454, 455, 456, 457, 458, 459, 461, 463, 465, 466, 468, 470, 472, 473, 474, 475, 476, 477, 478, 479, 480, 482, 483, 484, 485, 486, 487, 488, 490, 491, 492, 493, 494, 495, 496, 497, 498, 499, 500, 502, 503, 505, 506, 507, 510, 511], NumPruned=0]
[ <DEP: _prune_elementwise_op => prune_related_conv on model.10.conv (Conv2d(512, 256, kernel_size=(1, 1), stride=(1, 1), bias=False))>, Index=[0, 1, 2, 3, 7, 8, 10, 11, 12, 13, 16, 17, 18, 19, 21, 22, 23, 25, 27, 28, 29, 30, 31, 32, 33, 34, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50, 51, 53, 54, 56, 57, 58, 59, 60, 61, 62, 63, 65, 67, 69, 70, 71, 72, 73, 74, 76, 77, 78, 79, 80, 81, 82, 83, 84, 85, 86, 87, 89, 90, 91, 92, 95, 96, 97, 99, 100, 102, 103, 104, 105, 106, 107, 109, 110, 111, 113, 114, 115, 117, 118, 119, 120, 121, 122, 123, 124, 125, 126, 127, 128, 129, 130, 132, 133, 135, 137, 139, 142, 143, 144, 146, 148, 150, 152, 153, 154, 155, 156, 157, 158, 159, 161, 162, 163, 164, 165, 166, 167, 168, 169, 170, 171, 173, 174, 178, 179, 180, 181, 182, 183, 184, 185, 186, 187, 188, 189, 191, 192, 193, 194, 195, 196, 197, 198, 199, 200, 201, 202, 203, 204, 205, 206, 207, 208, 209, 210, 211, 212, 213, 215, 216, 217, 219, 220, 221, 222, 223, 224, 225, 226, 228, 229, 230, 232, 233, 234, 235, 236, 237, 239, 240, 241, 242, 243, 246, 247, 248, 249, 251, 252, 253, 254, 257, 258, 259, 260, 263, 264, 265, 266, 267, 268, 270, 271, 272, 273, 274, 275, 276, 277, 278, 280, 281, 282, 283, 284, 285, 286, 287, 288, 292, 293, 294, 295, 296, 297, 299, 301, 302, 303, 306, 307, 308, 309, 310, 311, 312, 313, 314, 315, 317, 318, 321, 322, 323, 324, 325, 326, 327, 329, 330, 331, 332, 334, 335, 338, 339, 341, 342, 343, 344, 346, 347, 349, 351, 353, 354, 355, 356, 357, 358, 359, 361, 362, 363, 364, 365, 366, 368, 369, 370, 372, 373, 374, 375, 378, 379, 381, 382, 383, 385, 386, 387, 388, 389, 390, 391, 392, 393, 395, 396, 397, 398, 399, 401, 402, 403, 404, 405, 407, 408, 411, 413, 414, 415, 416, 418, 419, 420, 421, 422, 423, 425, 426, 427, 428, 429, 430, 431, 432, 433, 434, 435, 436, 437, 438, 440, 441, 442, 443, 444, 445, 446, 448, 449, 451, 452, 453, 454, 455, 456, 457, 458, 459, 461, 463, 465, 466, 468, 470, 472, 473, 474, 475, 476, 477, 478, 479, 480, 482, 483, 484, 485, 486, 487, 488, 490, 491, 492, 493, 494, 495, 496, 497, 498, 499, 500, 502, 503, 505, 506, 507, 510, 511], NumPruned=104704]
190594 parameters will be pruned
-------------2022-09-29 12:30:50.396 | INFO | __main__:layer_pruning:75 - Params: 7022326 => 3056461
2022-09-29 12:30:50.691 | INFO | __main__:layer_pruning:89 - 剪枝完成
如果你仅仅就想剪一层,可以这样写:
included_layers = [model.model[3].conv] # 仅仅想剪一个卷积层3.剪枝后的训练
这里需要和稀疏训练区别一下,因为很多人在之前项目中问我有没有稀疏训练。我这里的通道剪枝是离线式的,也就是针对已经训练好的模型进行剪枝,而边训练边剪枝是在线式剪枝,这个训练过程也就是稀疏训练,所以还是有区别的。
训练后的剪枝训练与训练部分是一样的,只不过加一个pt参数而已。命令如下:
python train.py --weights model_data/layer_pruning.pt --data data/mydata.yaml --pt 4.剪枝后的模型预测
剪枝后的预测,和正常预测一样。
python detect.py --weights model_data/layer_pruning.pt --source [你的图像路径]这里再说明一下!!本文章只是给大家造个轮子,具体最终的剪枝效果,需要根据自己的需求以及实际效果来实现,我对整个backbone剪枝80%后的微调训练反正是效果很不好,对SPPF后其他的层剪枝还稍微好点,网上也有很多人说对backbone剪枝效果不行。
5.知识蒸馏训练
项目需求:想用知识蒸馏做剪枝后网络的微调训练
教师网络:未剪枝前的
学生网络:剪枝后的
由于学生网络是剪枝后的,因此可以脱离模型的yaml配置文件。
本项目的知识蒸馏是逻辑蒸馏(没有做特征层的蒸馏)。
模型实例化代码
s_ckpt = torch.load(s_weights, map_location=device)
s_model = s_ckpt['model'] # 学生网络
# 教师网络的创建
t_ckpt = torch.load(t_weights, map_location=device)
t_model = Model(t_cfg, ch=3, nc=nc, anchors=hyp.get('anchors')).to(device) # teacher model create蒸馏的关键代码:
其中d_weight是蒸馏权重。可以根据自己的实际情况调整。
s_pred = s_model(imgs) # student forward
_, t_pred = t_model(imgs) # teacher forward
s_hard_loss, loss_items = compute_loss(s_pred, targets.to(device)) # student hard loss
d_outputs_loss = compute_distillation_output_loss(s_pred, t_pred, s_model, d_weight=10)
loss = d_outputs_loss + s_hard_loss--t_weights:教师网络权重路径
--s_weights:学生网络权重路径
--data:data.yaml路径
--kd:开启蒸馏训练
python train_dil.py --t_weights best.pt --s_weights layer_pruning.pt --data data/mydata.yaml --batch-size 16 --kd训练后的结果会保存在runs/train/exp_kd中
代码
GitHub - YINYIPENG-EN/Knowledge_distillation_Pruning_Yolov5: 本项目支持对剪枝后的yolov5模型进行知识蒸馏训练(This project supports knowledge distillation training for the pruned YOLOv5 model)
补充说明:测试效果要根据实际应用场景、数据集、网络模型等有关,本文章发布的代码并不是万能的~ 文章来源:https://www.toymoban.com/news/detail-454357.html
2024.01.28更新功能:添加了用已训练好的模型自动标注数据集,欢迎使用文章来源地址https://www.toymoban.com/news/detail-454357.html
到了这里,关于yolov5剪枝与知识蒸馏【附代码】的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!