啊~数据库、操作系统、计算机网络、Linux
start
Linux
netstat grep top chmod find
chmod
作用:修改文件的权限(三级权限:档案拥有者、群组、其他)
chmod [-cfvR] [--help] [--version] mode file字符方式
mode:权限设定字串
[ugoa...][[+-=][rwxX]...][,...]u 表示该档案的拥有者 g 表示与该档案的拥有者属于同一个群体 o 表示其他以外的人 a 表示这三者皆是
+ 增加权限 - 取消权限 = 唯一设定权限
r 可读取 w 可写入 x 可执行 X 只有当该档案是个子目录或者该档案已经被设定过为可执行
-c 若该档案权限确实已经更改,才显示其更改动作
-f 若该档案权限无法被更改也不要显示错误信息
-v 显示权限变更的详细资料
-R 对目前目录下的所有档案与子目录进行相同的权限变更
--help 显示辅助说明
--version 显示版本
例子
chmod ugo+r file.txt chmod a+r file.txt //所有人皆可读取
//将f1.txt与f2.txt设置为该档案拥有者、与其所属同一个群体者可写入,但其他以外的人则不可写入
chmod ug+w,o-w f1.txt f2.txt
//将e.py设置为该档案拥有者可以执行
chmod u+x e.py
//将目前目录下的所有档案与子目录都设为任何人可读取
chmod -R a+r *数字方式
chmod nnn file.txtnnn:用户 组成员 其他
4 r 2 w 1 x
例子
//所有人皆可读写执行
chmod a=rwx file.txt
a:三个位置都写满了
=:唯一设定权限
rwx:4+2+1=7
chmod 777 file.txt
//档案拥有者和群组可读写执行,其他人只能执行
chmod ug=rwx,o=x file.txt
ug=rwx:77
o=x:1
chmod 771 file.txt
chmod 4755 file.txt //root权限grep
作用:查找文件
grep -l 'boss' * //显示所有包含boss的文件名
grep -n 'boss' file //在匹配行之前加行号
grep -i 'boss' file //显示匹配行,boss不区分大小写
grep -v 'boss' file //显示所有不匹配行
grep -q 'boss' file //找到匹配行,但不显示,但可以检查grep的退出状态(0为匹配成功)
grep -c 'boss' file //只显示匹配行数(包括0)
grep "$boss" file //扩展变量boss的值再执行命令
ps -ef|grep "^*user1" //搜索user1的命令,即使它前面有0个或多个空格
ps -e|grep -E 'grant_server|commsvr|tcpsvr|dainfo' //查找多个字符串的匹配//找出文件夹下包含“aaa”,同时不包含“bbb”的文件,然后重新生成
grep -rl "aaa" * | grep -v "bbb" //管道符| //左边的输出会作为右边的输入
generate 文件名
generate ·grep -rl "aaa" * | grep -v "bbb"·
//查找包含“logField”和“open”的文件
grep -rl "logField" * | grep -rl "open"操作系统
并发和并行
并发是同一时间段内发生了多个事情,多任务之间互相抢占资源。
并行是在同一时间点内发生了多个事情,多任务之间不互相抢占资源,只有多CPU的情况下才能并行。
例如:我今天同时学习了数据库、操作系统、计算机网络和Linux这四门课程,学四门课程的任务是并发执行的。我和我的小伙伴两个人(相当于多CPU),今天同时学习了四大件,但是某一时刻我俩同时学习了操作系统这门课程,这一时刻下的学习叫并行。
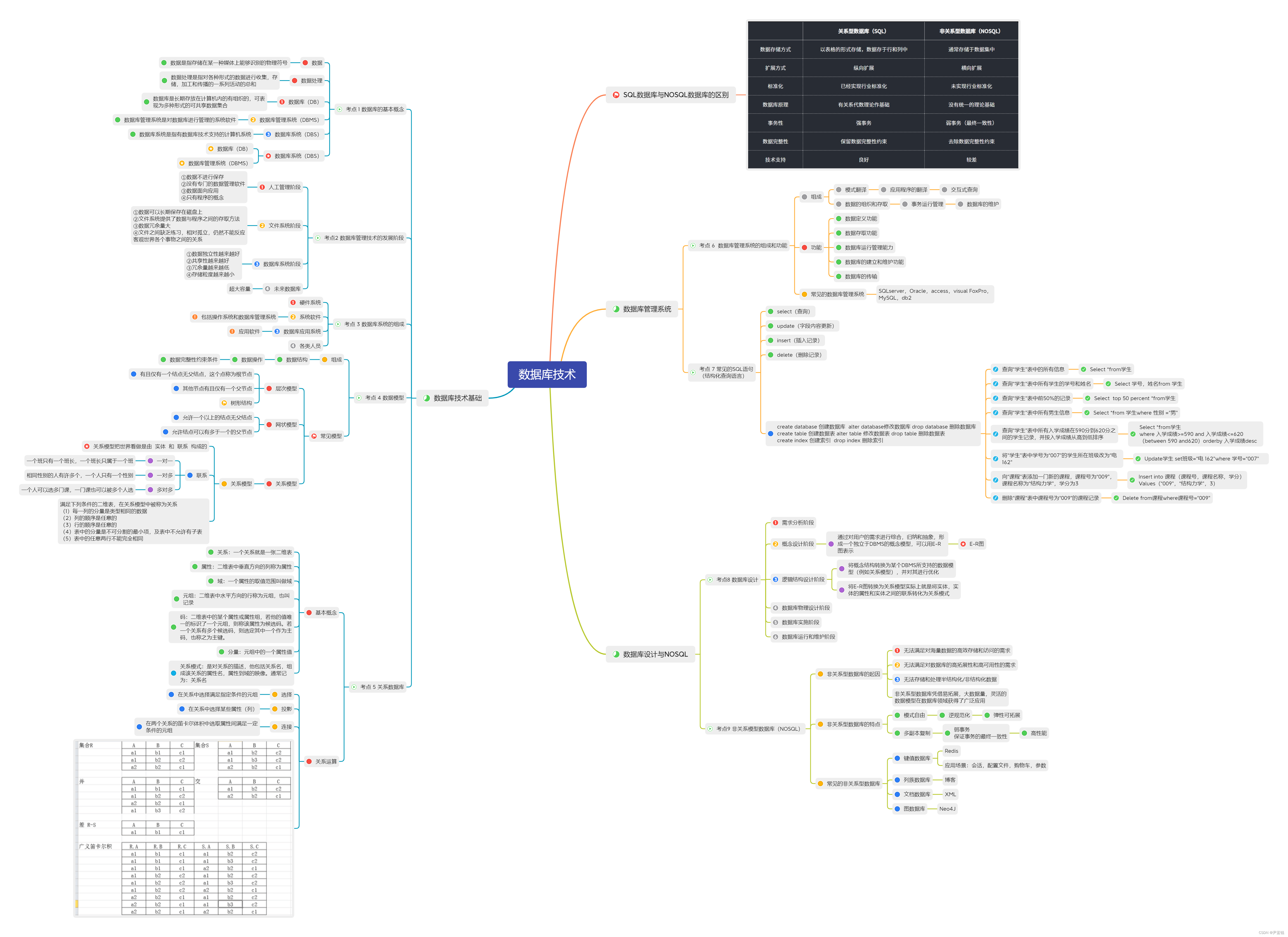
数据库
MySQL锁
用于解决多个事务在并发情况下的脏读、不可重复读、幻读、丢失更新。
查了一下王珊老师的《数据库系统概论》第5版,310页。
脏读:事务T1修改某一数据并将其写回磁盘,事务T2读取同一数据后,T1由于某种原因被撤销,这时被T1修改过的数据恢复原值,T2读到的数据就与数据库中的数据不一致,则T2读到的数据就为“脏”数据,即不正确的数据。
丢失更新:两个事务T1和T2读入同一数据并修改,T2提交的结果破坏了T1提交的结果,导致T1的修改被丢失。
不可重复读:事务T1读取数据后,事务T2执行更新操作,使T1无法再现前一次读取结果。
幻读:不可重复读的另外两种现象。1)事务T1按一定条件从数据库中读取了某些数据记录后,事务T2删除了其中部分记录,当T1再次按相同条件读取数据时,发现某些记录神秘地消失了。2)事务按一定条件从数据库中读取某些数据记录后,事务T2插入了一些记录,当T1再次按相同条件读取数据时,发现多了一些记录。
锁的种类
全局锁:对整个数据库加锁。(全库逻辑备份)(数据增删改查× 建表、修改表结构× 更新类事务的提交×)
Flush tables with read lock(FTWRL)表级锁
(1)表锁:(每次操作锁住整张表 开销小,加锁快 并发度低)
lock tables ...read/write元数据锁(MDL)访问表时自动被加上,保持读写的正确性。事务提交后释放,可能会产生死锁问题。
(2)行锁:针对数据表中行记录的锁(每次操作锁住一行数据 开销大,加锁慢 锁冲突低,并发度高)
加锁规则:2原则、2优化、1bug
2原则:1)加锁基本单位next-key lock,前开后闭
2)查找过程中访问到的对象才会加锁
2优化:1)索引上的等值查询,给唯一索引加锁时,next-key lock退化为行锁
2)索引上的等值查询,向右遍历时且最后一个值不满足等值条件时,next-key lock退化为间隙锁
1bug:唯一的索引上的范围查询会访问到不满足条件的第一个值为止
锁的划分
1、从数据库角度
共享锁(读锁 S锁)
可被其他用户读取,但不能修改
select user_id from product_comment where user_id = 10 lock in share mode;排它锁(写锁 X锁)
只允许进行锁定操作的事务使用,其他事务无法查询和修改
对数据库进行更新时(insert、update、delete),自动使用排它锁
select user_id from product_comment where user_id = 10 for update;all
还可以锁住一张表
lock table product_comment read; //添加共享锁
unlock table; //解锁
lock table product_comment write; //添加排它锁
unlock table; //解锁意向锁:给更大一级别的空间示意里面是否已经上过锁。
2、程序员角度
乐观锁:对同一数据的并发操作不会总发生,不用每次都上锁。(不采用数据库的锁机制,通过程序上,版本号或时间戳实现)(适合读操作多的场景,优点:程序实现不存在死锁问题)
悲观锁:对数据被其他事务修改保持保守态度。(通过数据库自身锁机制实现 )(适合写操作多的场景,缺点:加锁时间长,并发性不好)
InnoDB使用表锁还是行锁?
绝大多数情况下使用行锁。使用表锁:1)表大,事务需要更新全部或大部分数据2)事务涉及多个表,比较复杂,可能引起死锁,造成大量的事务回滚。
InnoDB事务遵从两级锁协议,需要添加行锁,事务结束时释放。
封锁协议:
一级封锁协议(丢失更新):事务T在修改数据R之前必须先对其加X锁,直到事务结束才释放
二级封锁协议(丢失更新、脏读):在一级封锁协议基础上增加事务T在读取数据R之前必须对其加S锁,读完之后即可释放S锁文章来源:https://www.toymoban.com/news/detail-454586.html
三级封锁协议(丢失更新、脏读、不可重复读):在一级封锁协议基础上增加事务T在读取数据R之前必须先对其加S锁,直到事务结束才释放文章来源地址https://www.toymoban.com/news/detail-454586.html
到了这里,关于计算机四大件笔记的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!