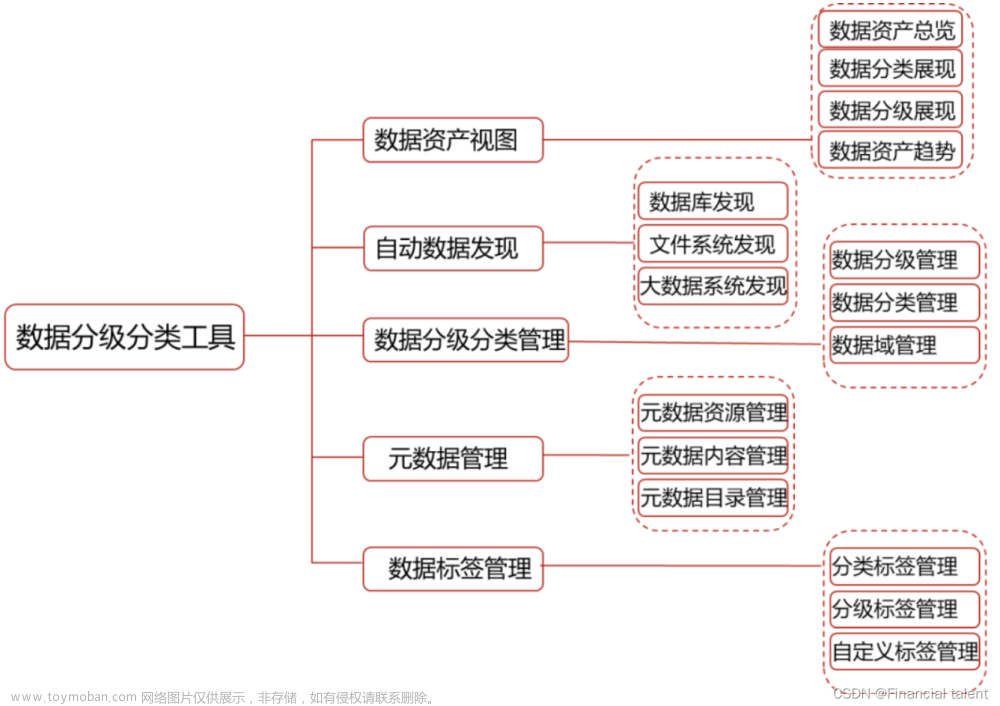
前面讲了数据分类分级 数据识别-实现部分敏感数据识别,本次针对模版导入展开,excel导入采用的是easyexcel

上面图片是AI创作生成!如需咒语可私戳哦!
easyexcel介绍
之前的excel导入解析采用的是Apache poi,但是在Java领域解析、生成Excel比较有名的框架如Apache poi,jxl等,在使用的时候,存在一个严重的问题,就是非常的耗内存,如果系统并发量不大的话,可能还行,但是一旦并发上来后一定会OOM或者JVM频繁的垃圾回收。
EasyExcel官网
EasyExcel是阿里巴巴开源的一个excel处理框架,他具有使用简单,节省内存的特点,EasyExcel能大大减少占用内存的主要原因是在解析Excel时没有将文件数据一次性全部加载到内存中,而是从磁盘上一行行读取数据,逐个解析的,这一特点待会在读取excel数据的时候也会体现出来。
gpt生成的介绍
easyexcel实战
添加依赖
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>easyexcel</artifactId>
<version>2.2.6</version>
</dependency>
读取数据
easyexcel读取文件数据需要设置监听器,通过实现监听器,就可以实现数据的单行读取操作, 以下面的这个数据对象为例:
/**
* 分类分级模版数据TemplateData
*/
@Data
public class TemplateData {
@ExcelProperty(value="一级分类",index = 0)
private String firstClass;
@ExcelProperty(value="一级分类描述",index = 1)
private String firstClassDesc;
@ExcelProperty(value="一级分类",index = 2)
private String secondClass;
@ExcelProperty(value="一级分类描述",index = 3)
private String secondClassDesc;
@ExcelProperty(value="一级分类",index = 4)
private String thirdClass;
@ExcelProperty(value="一级分类描述",index = 5)
private String thirdClassDesc;
@ExcelProperty(value="一级分类",index = 6)
private String fourthClass;
@ExcelProperty(value="一级分类描述",index = 7)
private String fourthClassDesc;
}
读取的数据内容如下示例:
数据安全-数据分类分级-国民经济行业数据分类模版.xlsx
监听器的实现
在读取excel数据的时候,需要实现AnalysisEventListener监听器,其中需要传入对应的数据类型,在该监听接口中,主要使用的方法是:
- invoke:一行一行读取,每读取一行数据时就会调用该方法。
- invokeHeadMap:读取表头数据,
- doAfterAllAnalysed:所有数据读取完毕之后调用,一般用于对最后读取到的数据进行处理。
- onException:在转换异常,获取其他异常的情况下会调用此接口,抛出异常就停止读取,如果不抛出异常就继续读取
接口的实现如下:
代码中会包含一些业务数据,如果可以结合上面的模版来看下面的代码可能会更好理解
/**
* 读取excel,设置监听器
*/
@Slf4j
public class TemplateDataListener extends AnalysisEventListener<TemplateData> {
/**
* 定义一个存储的界限,每读取BATCH_COUNT条数据就存储一次数据库,防止数据过多时发生溢出
* 存储完成之后就清空list重新读取新的数据,方便内存回收
*/
private static final int BATCH_COUNT = 800;
/**
* 定义一个数据存储缓存,用于临时存储sql数据
*/
public List<String> cacheSqlList = new ArrayList<>();
String firstClass = null;
String secondClass = null;
String thirdClass = null;
String firstClassId = null;
String secondClassId = null;
String thirdClassId = null;
String fourthClassId = null;
private List<String> repeatClassList = new ArrayList<>();
private List<String> templateClassList = new ArrayList<>();
private final DataSource dataSource;
private final String templateId;
public TemplateDataListener(DataSource dataSource, String templateId) {
this.dataSource = dataSource;
this.templateId = templateId;
}
@Override
public void invoke(TemplateData templateData, AnalysisContext analysisContext) {
if (null != templateData) {
//这里是因为存在分类跨行的数据,但是入库每一行都需要有父分类
firstClass = null == templateData.getFirstClass() ? firstClass : templateData.getFirstClass();
secondClass = null == templateData.getSecondClass() ? secondClass : templateData.getSecondClass();
thirdClass = null == templateData.getThirdClass() ? thirdClass : templateData.getThirdClass();
firstClassId = null == templateData.getFirstClass() ? firstClassId : CommonUtil.generateClassifyId();
secondClassId = null == templateData.getSecondClass() ? secondClassId : CommonUtil.generateClassifyId();
thirdClassId = null == templateData.getThirdClass() ? thirdClassId : CommonUtil.generateClassifyId();
fourthClassId = CommonUtil.generateClassifyId();
if (null != firstClass && (firstClass.length() > 30 || firstClass.contains("(") || firstClass.contains(")"))) {
log.info("#####:" + firstClass);
}
if (null != secondClass && (secondClass.length() > 30 || secondClass.contains("(") || secondClass.contains(")"))) {
log.info("#####:" + secondClass);
}
if (null != thirdClass && (thirdClass.length() > 30 || thirdClass.contains("(") || thirdClass.contains(")"))) {
log.info("#####:" + thirdClass);
}
if (null != templateData.getFourthClass() && (templateData.getFourthClass().length() > 30 || templateData.getFourthClass().contains("(") || templateData.getFourthClass().contains(")"))) {
log.info("#####:" + templateData.getFourthClass());
}
log.info("invoke :" + templateData + ", firstClassId:" + firstClassId + ", secondClassId:" + secondClassId + ", thirdClassId:"+ thirdClassId + ", fourthClassId:" + fourthClassId);
saveData(templateData, firstClassId, secondClassId, thirdClassId, fourthClassId, templateId);
/**
* 如果当前缓存列表中的数据等于指定值,就存储
*/
if (cacheSqlList.size() > BATCH_COUNT) {
log.info("保存数据到数据库: " + cacheSqlList.size());
runSql();
}
}
}
@Override
public void invokeHeadMap(Map<Integer, String> headMap, AnalysisContext context) {
log.info("表头:" + headMap);
}
@Override
public void doAfterAllAnalysed(AnalysisContext analysisContext) {
log.info("将最后的数据存储到数据库-cacheSqlList:" + cacheSqlList.size());
runSql();
log.info("读取结束,共有分类:" + templateClassList.size());
if (repeatClassList.size() > 0) {
log.info("存在重复分类名称:" + repeatClassList);
}
cacheSqlList.clear();
}
private void runSql() {
Connection connection = null;
Statement statement = null;
try {
connection = dataSource.getConnection();
statement = connection.createStatement();
for (String sql : cacheSqlList) {
statement.executeUpdate(sql);
}
} catch (Exception e) {
e.printStackTrace();
throw DatabaseErrorCodeEnum.CONNECT_DATABASE_ERROR.newException();
} finally {
try {
if (connection != null) {
connection.close();
}
if (statement != null) {
statement.close();
}
} catch (Exception e2) {
e2.printStackTrace();
throw DatabaseErrorCodeEnum.CONNECT_DATABASE_ERROR.newException();
}
}
//清空缓存列表重新读取
cacheSqlList.clear();
}
/**
* 在转换异常,获取其他异常的情况下会调用此接口,
* 抛出异常就停止读取,如果不抛出异常就继续读取。
* @param exception
* @param context
* @throws Exception
*/
@Override
public void onException(Exception exception, AnalysisContext context) throws Exception {
if (exception instanceof ExcelDataConvertException){
ExcelDataConvertException e = (ExcelDataConvertException) exception;
log.info("数据解析异常,所在行: " + e.getRowIndex() + ", 所在列: " + e.getColumnIndex() + ", 数据是:" + e.getCellData());
} else {
log.info("解析失败,但是继续解析下一行:" + exception.getMessage() + ", exception:" + exception.toString());
}
}
/**
* 将数据存储到持久层
*/
private void saveData(TemplateData templateData, String firstClassId, String secondClassId, String thirdClassId, String fourthClassId, String templateId) {
if (null != templateData.getFirstClass()) {
//检查是否存在重复名称的分类名称
checkRepeatClass(templateData.getFirstClass());
//生成sql放入缓存
String sql = getSql(null == templateData.getSecondClass(), 1L, templateId, templateId, firstClassId, templateData.getFirstClass(), templateData.getFirstClassDesc());
cacheSqlList.add(sql);
}
if (null != templateData.getSecondClass()) {
checkRepeatClass(templateData.getSecondClass());
String sql = getSql(null == templateData.getThirdClass(), 2L, templateId, firstClassId, secondClassId, templateData.getSecondClass(), templateData.getSecondClassDesc());
cacheSqlList.add(sql);
}
if (null != templateData.getThirdClass()) {
checkRepeatClass(templateData.getThirdClass());
String sql = getSql(null == templateData.getFourthClass(), 3L, templateId, secondClassId, thirdClassId, templateData.getThirdClass(), templateData.getThirdClassDesc());
cacheSqlList.add(sql);
}
if (null != templateData.getFourthClass()) {
checkRepeatClass(templateData.getFourthClass());
String sql = getSql(true, 4L, templateId, thirdClassId, fourthClassId, templateData.getFourthClass(), templateData.getFourthClassDesc());
cacheSqlList.add(sql);
}
}
private void checkRepeatClass(String classifyName) {
if (templateClassList.contains(classifyName)) {
repeatClassList.add(classifyName);
}
templateClassList.add(classifyName);
}
private String getSql(boolean leaf,Long level, String templateId, String parentClassifyId, String classifyId, String classifyName, String classifyDesc) {
long timestamp = System.currentTimeMillis();
SimpleDateFormat simpleDateFormat = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
String date = simpleDateFormat.format(new Date(timestamp));
return "INSERT INTO `template_classify` (`leaf`, `level`, `classify_template_id`, `parent_classify_id`, `classify_id`, `classify_name`, `classify_desc`, `rule_id`, `is_built_in`, `extra`, `create_time`, `last_modified_time`)" +
" VALUES(" + leaf + "," + level + ",'" + templateId + "','" + parentClassifyId + "','" + classifyId + "','" + classifyName + "','" + classifyDesc + "',NULL" + "," + 1 + ",'','" + date + "','" + date + "'" + ")";
}
}
数据读取方法
接口实现完毕之后,进行数据读取的方法其实是非常简单,只需要一句代码就可以了,
读取如下:文章来源:https://www.toymoban.com/news/detail-454807.html
/**
* 从excel中读取全部工作表的数据
* dataSource, templateId和都业务需要的数据,如果没有可以删除
*/
private void readAllSheetDataForExcel(String path, String templateId) {
/**
* 主要是doReadAll()方法
*/
EasyExcel.read(path, TemplateData.class, new TemplateDataListener(dataSource, templateId)).sheet().doRead();
}
读取结果

查看数据库
数据分类分级 数据识别-excel分类分级模版文件导入、解析的操作就到这里,如果有不解或需要帮助的,欢迎讨论!文章来源地址https://www.toymoban.com/news/detail-454807.html
到了这里,关于数据分类分级 数据识别-excel分类分级模版文件导入、解析的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!