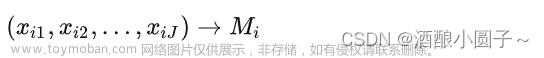权重计算方法有很多种,不同的方法有不同的特点和适用情况。AHP层次分析法和熵值法在权重计算中属于比较常用的方法。除此之外,还有一些与权重计算相关的方法,今天一文总结了13种与权重计算相关的方法,大家可以对比选择使用。

一、13种权重计算方法
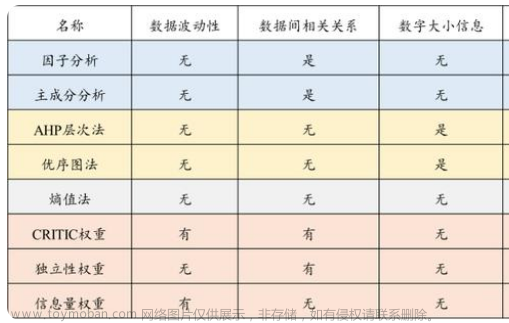
一句话简单描述13种权重计算方法,见下表:

提示:以上13种方法中,模糊综合评价、灰色关联法、TOPSIS法、熵权TOPSIS这4种方法属于综合评价方法,并非主流权重计算方法,本文将一并进行介绍。
接下来,对13种方法进行逐个说明。
二、13种权重计算方法说明
(1)AHP层次分析法
AHP层次分析法是一种主观赋权法和客观赋权法相结合的方法,被广泛应用于指标权重的确定。该方法先用专家经验判断指标相对重要程度,再计算权重,比较适合解决难以用定量方法应对的问题。
AHP层次分析法的数据格式比较特殊,需要手工录入判断矩阵,如下表:

上表格显示:门票相对于景色来讲,重要性更高,所以为3分;相反,景色相对于门票来讲,则为0.33333分。交通相对于景色来更重要为2分,其余类似下去。
SPSSAU输出权重计算结果如下:


(2)熵值法
熵值法是客观赋权法当中的一种,熵值是对不确定性的一种度量。熵值法用以确定指标权重的根据是各项指标在数值层面的变异程度,由于对客观数据有着高度依赖,熵值法的运用过程中避免了人为因素对指标权重结果可能造成的偏差。
在进行熵值法之前,如果数据方向不一致时,需要进行提前数据处理,通常为正向化、逆向化两种处理。
SPSSAU输出权重计算结果如下:

(3)因子分析法
因子分析通过信息浓缩大小进行权重计算,使用旋转后方差解释率进行计算。比如提取3个因子,旋转后的方差解释率分别是45.802%,65.517%,75.246%,旋转后累积方差解释率为75.246%。那么归一化(即除累积方差解释率)即得到权重。

权重计算如下表:

(4)主成分分析法
主成分分析法与因子分析法计算权重的原理类似,都根据信息浓缩大小进行权重计算。权重计算是主成分的一类应用场景,其原理在于使用方差解释率进行权重计算。如下图:得到的4个主成分的方差解释率和累积方差解释率:

权重计算如下表:

(5)模糊综合评价
模糊综合评价借助模糊数学的一些概念,应用模糊关系合成原理,将一些边界不清、不易定量的因素定量化,进而进行综合性评价的一种方法。
模糊综合评价的数据格式比较特殊,需要注意:1列放1个评价项(比如不满意、比较不满意、满意、非常满意之类的评价项)。如果说各个指标项有着自己的权重,那么就需要单独用一列表示 “ 指标项权重值 ”,如果没有此数据,默认各个指标的权重完全一致。如下图:

SPSSAU输出权重计算结果如下:

(6)灰色关联法
灰色关联分析法通过研究数据关联性大小(母序列与特征序列之间的关联程度),通过关联度(即关联性大小)进行度量数据之间的关联程度,从而辅助决策的一种研究方法。
灰色关联法数据格式:母序列单独使用一列标识,每个特征序列都使用1列标识。

SPSSAU输出结果如下:


(7)TOPSIS法
TOPSIS法用于研究与理想方案相似性的顺序选优技术,通俗理解即为数据大小有优劣关系,数据越大越优,数据越小越劣,因此结合数据间的大小找出正负理想解以及正负理想解距离,并且在最终得到接近程序C值,并且结合C值排序得出优劣方案排序。
在进行TOPSIS法分析时,数据一定需要全部同趋势正向化,即让所有的数据表示为数字越大越优;如果数据量纲不一致,还需要使用数据归一化解决量纲问题。
SPSSAU输出结果如下:

(8)熵权TOPSIS法
熵权TOPSIS法核心在于TOPSIS,但在计算数据时,首先会利用熵值法(熵权法)计算得到各评价指标的权重,并且将评价指标数据与权重相乘,得到新的数据,利用新数据进行TOPSIS法研究。
(9)优序图法
优序图法利用数据相对重要性原理进行权重计算,数字越大,其相对重要性会越高。SPSSAU默认对分析项计算出平均值,并且结合平均值的相对大小构建出优序图权重计算表,进而计算得到权重。
SPSSAU输出权重计算结果如下:

(10)CRITIC权重
CRITIC权重法是一种客观赋权法。其思想在于用于两项指标,分别是对比强度和冲突性指标。对比强度使用标准差进行表示;冲突性使用相关系数进行表示。权重计算时,对比强度与冲突性指标相乘,并且进行归一化处理,即得到最终的权重。
在进行CRITIC分析之前,通常需要对数据进行量纲化处理,一般建议使用正向化或逆向化处理。
SPSSAU输出权重计算结果如下:

(11)独立性权重
独立性权重法是一种客观赋权法。其思想在于利用指标之间的共线性强弱来确定权重。如果说某指标与其它指标的相关性很强,说明信息有着较大的重叠,意味着该指标的权重会比较低,反之该指标的权重会更高。
SPSSAU输出权重计算结果如下:

(12)信息量权重
信息量权重法是一种客观赋权法。其思想在于利用数据的变异系数进行权重赋值,如果变异系数越大,说明其携带的信息越大,因而权重也会越大。信息量权重的适用场景较小,通常只用于专家评价打分时使用。
SPSSAU输出权重计算结果如下:

(13)DEMATEL
Dematel(决策实验室法),其通过系统中各要素之间的逻辑关系和直接影响矩阵,可以计算出每个要素对其它要素的影响度以及被影响度,从而计算出每个要素的原因度与中心度,作为构造模型的依据,从而确定要素间的因果关系和每个要素在系统中的地位。
DEMATEL的数据格式说明为:第1行为标题,第2行起为数据,数据一定为方阵(即除标题外的数据需要行和列相等),右下三角线数据一定为0。数据格式类似下图。

SPSSAU输出权重计算结果如下:
 文章来源:https://www.toymoban.com/news/detail-454881.html
文章来源:https://www.toymoban.com/news/detail-454881.html
以上13种分析方法的更详细介绍,可以登录SPSSAU官网,查看每一种方法的帮助手册说明,以及教学视频。文章来源地址https://www.toymoban.com/news/detail-454881.html
到了这里,关于13种权重的计算方法的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!