Hadoop 自带 S3 依赖,位置如下:
$HADOOP_HOME/share/hadoop/tools/lib/hadoop-aws-3.1.3.jar
$HADOOP_HOME/share/hadoop/tools/lib/aws-java-sdk-bundle-1.11.271.jar
但是这些依赖包默认不在 hadoop classpath 下面。可以使用以下两种方法引入这两个包:
在 hadoop-env.sh 中加入 export HADOOP_CLASSPATH=$HADOOP_CLASSPATH:$HADOOP_HOME/share/hadoop/tools/lib/*。更改完毕后可以使用 hadoop classpath 确定。
通过软链接:ln -s $HADOOP_HOME/share/hadoop/tools/lib/*aws* $HADOOP_HOME/share/hadoop/common/lib/
修改hadoop的core-site.xml文件:
s3的配置模板(记得修改成自己的 secret key 与 access key )
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>fs.s3a.access.key</name>
<value>xbqk6TYW5ujCaLxH</value>
</property>
<property>
<name>fs.s3a.secret.key</name>
<value>6fSRPMeFNwaNxkWxgz6OrupxsAY5YCjw</value>
</property>
<property>
<name>fs.s3a.connection.ssl.enabled</name>
<value>false</value>
</property>
<property>
<name>fs.s3a.path.style.access</name>
<value>true</value>
</property>
<property>
<name>fs.s3a.endpoint</name>
<value>http://172.16.120.190:32613</value>
</property>
<property>
<name>fs.s3a.impl</name>
<value>org.apache.hadoop.fs.s3a.S3AFileSystem</value>
</property>
<property>
<name>fs.defaultFS</name>
<value>s3a://hive0614/</value>
</property>
</configuration>
更改完毕并重启集群后
测试hdfs dfs -ls s3a://hive0614/ 等命令操作 S3 中的文件。
bin/hdfs dfs -mkdir s3a://hive0614/mgtest
bin/hdfs dfs -ls s3a://hive0614/

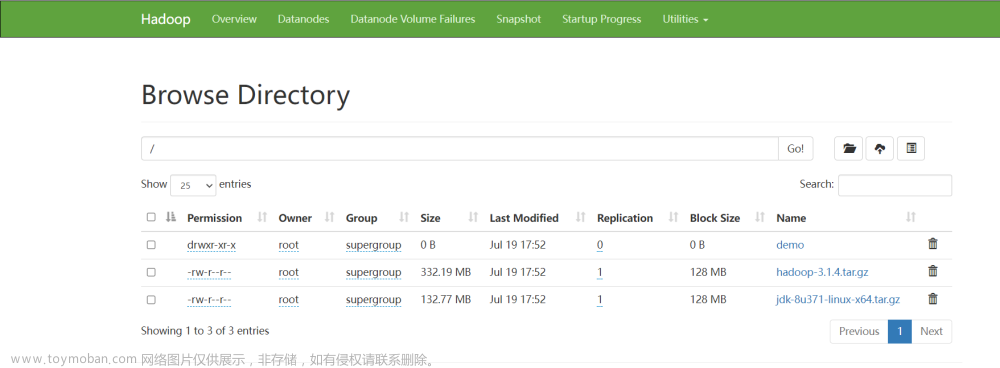
目前HDFS Client已经可以看到S3文件了。
如果需要yarn和MapReducer 需要修改如下文件
hdfs-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>dfs.namenode.datanode.registration.ip-hostname-check</name>
<value>false</value>
</property><property>
<name>dfs.permissions.enabled</name>
<value>false</value>
</property>
<property>
<name>dfs.namenode.rpc-bind-host</name>
<value>0.0.0.0</value>
</property>
<property>
<name>dfs.namenode.servicerpc-bind-host</name>
<value>0.0.0.0</value>
</property>
<property>
<name>dfs.namenode.http-bind-host</name>
<value>0.0.0.0</value>
</property>
<property>
<name>dfs.namenode.https-bind-host</name>
<value>0.0.0.0</value>
</property>
<property>
<name>dfs.client.use.datanode.hostname</name>
<value>false</value>
</property>
<property>
<name>dfs.datanode.use.datanode.hostname</name>
<value>false</value>
</property>
</configuration>
yarn-site.xml:
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>tdh01</value>
</property>
<property>
<name>yarn.resourcemanager.store.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.recovery.FileSystemRMStateStore</value>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce_shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>mapred.map.output.compress.codec</name>
<value>org.apache.hadoop.io.compress.SnappyCodec</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.capacity.CapacityScheduler</value>
</property>
<property>
<name>mapreduce.map.output.compress</name>
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.recovery.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
<property>
<name>yarn.resourcemanager.bind-host</name>
<value>0.0.0.0</value>
</property>
<property>
<name>yarn.nodemanager.bind-host</name>
<value>0.0.0.0</value>
</property>
<property>
<name>yarn.nodemanager.bind-host</name>
<value>0.0.0.0</value>
</property>
<property>
<name>yarn.timeline-service.bind-host</name>
<value>0.0.0.0</value>
</property>
<property>
<name>yarn.application.classpath</name>
<value>
/opt/adptest/hadoop/etc/hadoop,
/opt/adptest/hadoop/share/hadoop/common/*,
/opt/adptest/hadoop/share/hadoop/common/lib/*,
/opt/adptest/hadoop/share/hadoop/hdfs/*,
/opt/adptest/hadoop/share/hadoop/hdfs/lib/*,
/opt/adptest/hadoop/share/hadoop/mapreduce/*,
/opt/adptest/hadoop/share/hadoop/mapreduce/lib/*,
/opt/adptest/hadoop/share/hadoop/yarn/*,
/opt/adptest/hadoop/share/hadoop/yarn/lib/*
</value>
</property>
</configuration>
mapred-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=/opt/adptest/hadoop</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=/opt/adptest/hadoop</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=/opt/adptest/hadoop</value>
</property>
<property>
<name>yarn.application.classpath</name>
<value>
/opt/adptest/hadoop/etc/hadoop,
/opt/adptest/hadoop/share/hadoop/common/*,
/opt/adptest/hadoop/share/hadoop/common/lib/*,
/opt/adptest/hadoop/share/hadoop/hdfs/*,
/opt/adptest/hadoop/share/hadoop/hdfs/lib/*,
/opt/adptest/hadoop/share/hadoop/mapreduce/*,
/opt/adptest/hadoop/share/hadoop/mapreduce/lib/*,
/opt/adptest/hadoop/share/hadoop/yarn/*,
/opt/adptest/hadoop/share/hadoop/yarn/lib/*
</value>
</property>
</configuration>
分发给其他节点:
scp -r etc/hadoop/yarn-site.xml etc/hadoop/mapred-site.xml tdh02:/opt/adptest/

配置完毕后,分发配置,然后需要重启整个 Hadoop 集群
Hive配置方法:
在 Hive 的安装目录下进行以下操作,增加依赖包:
mkdir /opt/hive/auxlib
ln -s $HADOOP_HOME/share/hadoop/tools/lib/*aws* ./auxlib/

创建 core-site.xml
在 $HIVE_HOME/conf 目录下新建 core-site.xml 并加入如下配置:
core-site.xml
<configuration>
<property>
<name>fs.s3a.access.key</name>
<value>xbqk6TYW5ujCaLxH</value>
</property>
<property>
<name>fs.s3a.secret.key</name>
<value>6fSRPMeFNwaNxkWxgz6OrupxsAY5YCjw</value>
</property>
<property>
<name>fs.s3a.connection.ssl.enabled</name>
<value>false</value>
</property>
<property>
<name>fs.s3a.path.style.access</name>
<value>true</value>
</property>
<property>
<name>fs.s3a.endpoint</name>
<value>http://172.16.120.190:32613</value>
</property>
<property>
<name>fs.s3a.impl</name>
<value>org.apache.hadoop.fs.s3a.S3AFileSystem</value>
</property>
</configuration>
配置 hive-env.sh
在 $HIVE_HOME/conf 目录下运行 cp hive-env.sh.template hive-env.sh 后添加如下内容:
# Folder containing extra libraries required for hive compilation/execution can be controlled by:
export HIVE_AUX_JARS_PATH=$HIVE_HOME/auxlib
重启hive服务
$HIVE_HOME/bin/hiveservices.sh restart
后台启动:
nohup ./hive --service metastore 2>&1 &
nohup ./hive --service hiveserver2 2>&1 &
启动完成后测试hive使用:
#创建表文章来源:https://www.toymoban.com/news/detail-455274.html
create table mgtest2(id int) location 's3a://hive0614/hive/warehouse/mgtest2';
insert into table mgtest2 values(1);
select * from mgtest2;

 文章来源地址https://www.toymoban.com/news/detail-455274.html
文章来源地址https://www.toymoban.com/news/detail-455274.html
到了这里,关于Hadoop 集群中使用 S3(对象存储)文件系统的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!
![[ 云计算 | AWS 实践 ] 使用 Java 列出存储桶中的所有 AWS S3 对象](https://imgs.yssmx.com/Uploads/2024/02/742234-1.png)
![[ 云计算 | AWS ] Java 应用中使用 Amazon S3 进行存储桶和对象操作完全指南](https://imgs.yssmx.com/Uploads/2024/02/680987-1.png)
![[ 云计算 | AWS 实践 ] Java 应用中使用 Amazon S3 进行存储桶和对象操作完全指南](https://imgs.yssmx.com/Uploads/2024/02/713792-1.png)






