BeautifulSoup
1.定义:
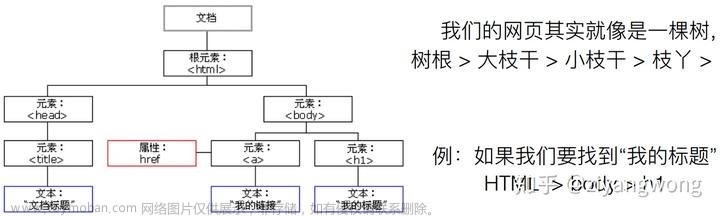
将复杂的HTML文档转换成一个复杂的树形结构,每个结点都是一个Python对象,所有对象可以分为四种:
Tag
NavigableString
BeautifulSoup
Comment
2.说明:
首先要引入该函数,再打开相应的html文件读取其中的内容,在使用BeautiSoup对其进行解析,解析的时候要使用相应类型的解析器html.parser

bs当中是我们获取到的该网址的解析信息,其中包含了如head,a,title等信息,这些名头,就是标签Tag
Tag:标签及其内容:拿到它所找到的第一个内容。
print(bs.title)
只获得标签的内容,不要标签:
print(bs.title.string)文章来源:https://www.toymoban.com/news/detail-455371.html
这个内容就是NavigableString文章来源地址https://www.toymoban.com/news/detail-455371.html
到了这里,关于Python爬虫——BeautifulSoup,获取HTML中文档,标签等内容的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!




![第一个Python程序_获取网页 HTML 信息[Python爬虫学习笔记]](https://imgs.yssmx.com/Uploads/2024/01/797744-1.png)