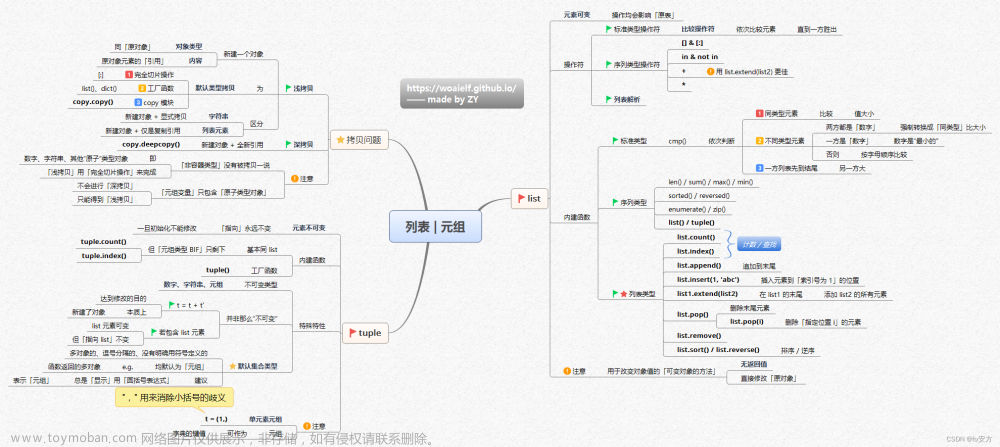
1. 序列
1.1 什么是序列
Python 中的序列是一种数据类型,用于存储一组有序的元素。序列是 Python 中最基本的数据结构之一,具有以下基本特性:
- 有序性:序列中的元素按照一定的顺序排列,可以通过索引访问和操作特定位置的元素。
- 可迭代性:序列可以进行迭代操作,例如使用循环遍历序列中的元素。
- 可变性:某些序列类型(如列表和字节数组)是可变的,可以对其进行添加、删除、修改元素等操作;而另一些序列类型(如字符串和元组)是不可变的,不能直接修改其元素,只能通过创建新的序列实现变化。
- 支持多种元素类型:序列可以包含不同类型的元素,如整数、浮点数、字符串等。
- 长度可变:可变序列的长度可以动态增加或减少,不可变序列的长度固定。
1.2 基本操作
对序列进行操作时,可以使用一些常用的操作符和函数:
1.2.1 索引
序列中的元素可以通过索引访问,索引从 0 开始。例如,序列 my_list 中的第一个元素可以通过 my_list[0] 来获取。
1.2.2 切片
切片:可以使用切片操作来获取序列中的子序列。切片使用起始索引和结束索引来指定子序列的范围。例如,my_list[1:4] 将返回从索引 1 到索引 3 的子序列。
(1)语法一
语法:列表[起始:结束]
通过切片获取元素时,会包括起始位置的元素,不会包括结束位置的元素
做切片操作时,总会返回一个新的列表,不会影响原来的列表
起始和结束位置的索引都可以省略不写
如果省略结束位置,则会一直截取到最后
如果省略起始位置,则会从第一个元素开始截取
如果起始位置和结束位置全部省略,则相当于创建了一个列表的副本
(2)语法二
语法:列表[起始:结束:步长]
步长表示,每次获取元素的间隔,默认值是1
print(stus[0:5:3])
步长不能是0,但是可以是负数
print(stus[::0]) ValueError: slice step cannot be zero
如果是负数,则会从列表的后部向前边取元素
(3)长度
长度:可以使用 len() 函数获取序列的长度,即其中元素的个数。
(4)遍历(迭代)
迭代:可以使用循环结构对序列进行迭代,逐个处理其中的元素。
(5)运算符①
运算符:序列支持一些常用的运算符,例如 + 运算符可以用于拼接两个序列,* 运算符可以用于重复序列的元素。
(6)修改序列
修改序列:在某些情况下,序列是可变的,可以修改其中的元素。例如,列表是可变的,可以通过索引来修改列表中的元素。
(7)通用操作
连接操作:使用 + 运算符将两个序列连接起来,生成一个新的序列。
重复操作:使用 * 运算符将序列重复指定次数,生成一个新的序列。
(8)运算符②
在 Python 中,in 和 not in 是用于判断某个元素是否存在于序列中的成员运算符。
-
in运算符用于检查元素是否存在于序列中,如果存在则返回True,否则返回False。 -
not in运算符则用于检查元素是否不存在于序列中,如果不存在则返回True,否则返回False。
这两个运算符可以应用于任何序列类型,包括字符串、列表、元组和字节数组序列等。
(9)其他内置函数
其他内置函数:min() 和 max() 用于获取序列中的最小值和最大值,sum() 用于求序列元素的和等。
my_list = [1, 2, 3, 4, 5] # 列表
my_tuple = (1, 2, 3, 4, 5) # 元组
my_string = "Hello, World!" # 字符串
# 通过索引访问元素
print(my_list[0]) # 输出: 1
print(my_tuple[2]) # 输出: 3
print(my_string[7]) # 输出: W
# 使用切片获取子序列
print(my_list[1:4]) # 输出: [2, 3, 4]
print(my_tuple[:3]) # 输出: (1, 2, 3)
print(my_string[7:]) # 输出: World!
# 获取序列的长度
print(len(my_list)) # 输出: 5
print(len(my_tuple)) # 输出: 5
print(len(my_string)) # 输出: 13
# 迭代序列
for item in my_list:
print(item)
# 序列的运算符
new_list = my_list + [6, 7] # 拼接两个列表
print(new_list) # 输出: [1, 2, 3, 4, 5, 6, 7]
repeated_tuple = my_tuple * 3 # 元组重复三次
print(repeated_tuple) # 输出: (1, 2, 3, 4, 5, 1, 2, 3, 4, 5, 1, 2, 3,
# 修改序列
stus = ['孙悟空','猪八戒','沙和尚','唐僧','蜘蛛精','白骨精']
stus[0:0] = ['牛魔王'] # 向索引为0的位置插入元素
# 连接操作
print(my_list + [6, 7]) # 输出:[1, 2, 3, 4, 5, 6, 7]
# 重复操作
print(my_list * 2) # 输出:[1, 2, 3, 4, 5, 1, 2, 3, 4, 5]
# 成员关系判断
print(3 in my_list) # 输出:True 2. python中各种类型的序列
2.1 字符串序列(str)
2.1.1 定义
定义:由字符组成的不可变序列。
用途:用于存储和操作文本数据。
2.1.2 示例
# 访问序列元素:
my_string = "Hello"
print(my_string[0]) # 输出第一个字符: 'H'
# 切片操作:
my_string = "Hello, World"
print(my_string[7:]) # 输出从索引为 7 到末尾的子字符串: 'World'
# 序列拼接和重复:
my_string1 = "Hello"
my_string2 = "World"
concatenated_string = my_string1 + ", " + my_string2 # 连接两个字符串
print(concatenated_string) # 输出拼接后的字符串: 'Hello, World'
# 序列成员检查:
my_string = "Hello"
print('H' in my_string) # 检查字符是否
# 字符串中的成员运算
string = "Hello, World!"
print('H' in string) # 输出:True,'H' 存在于字符串中
print('X' not in string) # 输出:True,'X' 不存在于字符串中2.2 列表序列(list)
2.2.1 定义
-
定义:由任意类型的元素组成的可变序列,用方括号
[ ]表示。 -
用途:用于存储和操作多个元素的集合。
2.2.2 示例
# 访问序列元素
my_list = [1, 2, 3, 4]
print(my_list[2]) # 输出索引为 2 的元素: 3
# 切片操作:
my_list = [1, 2, 3, 4, 5]
print(my_list[1:4]) # 输出索引为 1 到 3 的子列表: [2, 3, 4]
# 序列拼接和重复:
my_list1 = [1, 2, 3]
my_list2 = [4, 5, 6]
concatenated_list = my_list1 + my_list2 # 连接两个列表
print(concatenated_list) # 输出拼接后的列表: [1, 2, 3, 4, 5, 6]
# 列表中的成员运算
list = [1, 2, 3, 4, 5]
print(3 in list) # 输出:True,3 存在于列表中
print(6 not in list) # 输出:True,6 不存在于列表中2.3 元组序列(tuple)
2.3.1 定义
-
定义:由任意类型的元素组成的不可变序列,用圆括号
( )表示。 -
用途:用于存储和保护一组数据,通常在函数返回多个值时使用。
2.3.2 示例
# 访问序列元素:
my_tuple = (10, 20, 30)
print(my_tuple[-1]) # 输出最后一个元素: 30
# 切片操作:
my_tuple = (10, 20, 30, 40)
print(my_tuple[:2]) # 输出从开始到索引为 1 的子元组: (10, 20)
# 序列拼接和重复:
my_tuple1 = (10, 20)
my_tuple2 = (30, 40)
concatenated_tuple = my_tuple1 + my_tuple2 # 连接两个元组
print(concatenated_tuple) # 输出拼接后的元组: (10, 20, 30, 40)
# 元组中的成员运算
tuple = (1, 2, 3, 4, 5)
print(2 in tuple) # 输出:True,2 存在于元组中
print(6 not in tuple) # 输出:True,6 不存在于元组中2.4 范围序列(range)
2.4.1 定义
-
定义:由指定范围内的整数组成的不可变序列。
-
用途:用于生成一系列连续的整数,通常在循环中使用。
2.4.2 示例
# 访问序列元素:
my_range = range(5)
print(my_range[2]) # 输出索引为 2 的元素: 2
# 切片操作:
my_range = range(5)
print(list(my_range[2:4])) # 输出索引为 2 到 3 的子列表: [2, 3]
# 序列拼接和重复:
my_range = range(3)
repeated_range = my_range * 3 # 重复范围三次
print(list(repeated_range)) # 输出重复后的列表: [0, 1, 2, 0, 1, 2, 0, 1, 2]
2.5 字节数组序列(bytearray)
2.5.1 定义
-
定义:由字节组成的可变序列。
-
用途:用于在二进制数据上执行可变操作。
2.5.2 示例
# 创建空的字节数组序列
my_bytes = bytearray()
# 创建包含字节数据的字节数组序列
my_bytes = bytearray(b'Hello')
# 通过索引访问和修改字节
print(my_bytes[0]) # 输出:72,对应 ASCII 码中的 'H'
my_bytes[1] = 101 # 修改字节为 ASCII 码中的 'e'
# 切片操作
print(my_bytes[2:4]) # 输出:bytearray(b'll')
my_bytes[2:4] = b'xy' # 替换字节
# 添加和删除字节
my_bytes.append(111) # 添加字节到末尾
del my_bytes[0] # 删除指定位置的字节
# 转换为字符串
my_str = my_bytes.decode('utf-8')
# 字节数组序列中的成员运算
bytearray = bytearray(b'Hello')
print(108 in bytearray) # 输出:True,108 对应字节 'l' 存在于字节数组序列中
print(120 not in bytearray) # 输出:True,120 对应字节 'x' 不存在于字节数组序列中
# 其他常用操作
length = len(my_bytes) # 获取字节数组序列的长度
my_bytes.extend(b'World') # 扩展字节数组序列
3. 字典
3.1 字典定义与说明
字典(Dictionary)是 Python 中的一种数据结构,用于存储键-值(Key-Value)对。字典是可变的、无序的,且键(Key)必须是唯一的。在字典中,键用于查找、访问和修改对应的值。
字典的定义使用花括号 {},每个键-值对之间使用冒号 : 分隔。字典的基本语法如下:
# 创建字典
my_dict = {key1: value1, key2: value2, key3: value3}
其中,key1、key2、key3 是键,对应的 value1、value2、value3 是值。键和值可以是任意类型的对象,通常键是不可变的类型,如字符串、数字或元组,而值可以是任意类型的对象。
字典的特性包括:
- 键必须是唯一的,如果在同一个字典中使用相同的键进行赋值,后面的值会覆盖前面的值。
- 字典中的键是无序的,不会按照定义时的顺序进行存储和访问。
- 字典是可变的,可以添加、修改或删除键-值对。
- 字典可以根据键来进行快速的查找和访问,因此在需要根据某个标识获取对应值的场景下很有用。
3.2 常用操作示例
以下是字典的一些常用操作示例:
# 创建字典
my_dict = {'name': 'Alice', 'age': 25, 'city': 'New York'}
# 访问字典中的值
print(my_dict['name']) # 输出:Alice
print(my_dict.get('age')) # 输出:25
# 修改字典中的值
my_dict['age'] = 26
print(my_dict['age']) # 输出:26
# 添加新的键-值对
my_dict['gender'] = 'Female'
print(my_dict) # 输出:{'name': 'Alice', 'age': 26, 'city': 'New York', 'gender': 'Female'}
# 删除键-值对
del my_dict['city']
print(my_dict) # 输出:{'name': 'Alice', 'age': 26, 'gender': 'Female'}
# 检查键是否存在
print('age' in my_dict) # 输出:True
print('city' not in my_dict) # 输出:True
# 获取字典中所有的键和值
keys = my_dict.keys()
values = my_dict.values()
print(keys) # 输出:dict_keys(['name', 'age', 'gender'])
print(values) # 输出:dict_values(['Alice', 26, 'Female'])
3.3 遍历字典
遍历字典可以使用字典对象的不同方法来实现。以下是几种常用的遍历字典的方式:
(1)遍历键(keys): 使用字典的 keys() 方法获取所有键,然后通过循环遍历键,再根据键获取对应的值。
my_dict = {'name': 'Alice', 'age': 25, 'city': 'New York'}
for key in my_dict.keys():
print(key, my_dict[key])
(2)遍历值(values): 使用字典的 values() 方法获取所有值,然后通过循环遍历值。
my_dict = {'name': 'Alice', 'age': 25, 'city': 'New York'}
for value in my_dict.values():
print(value)
(3)遍历键值对(items): 使用字典的 items() 方法获取所有键值对,然后通过循环遍历键值对,可以同时获取键和值。
my_dict = {'name': 'Alice', 'age': 25, 'city': 'New York'}
for key, value in my_dict.items():
print(key, value)
注意,字典是无序的,所以遍历时不会按照键的顺序进行输出。如果需要按照特定的顺序遍历字典,可以使用 sorted() 函数对键进行排序,然后再进行遍历。
my_dict = {'name': 'Alice', 'age': 25, 'city': 'New York'}
for key in sorted(my_dict.keys()):
print(key, my_dict[key])
通过以上方法,你可以轻松地遍历字典并获取其中的键、值或键值对,根据具体需求选择适合的遍历方式。
3.4 复制字典
在 Python 中,复制字典有两种方式:浅复制和深复制。
(1)浅复制(Shallow Copy): 浅复制创建了一个新的字典对象,但是该新字典的键和值与原始字典相同。也就是说,新字典中的键和值是对原始字典中相同键和值的引用。
可以使用字典对象的 copy() 方法进行浅复制。
original_dict = {'name': 'Alice', 'age': 25}
new_dict = original_dict.copy()
print(new_dict)
输出:
{'name': 'Alice', 'age': 25}
在浅复制中,如果原始字典中的值是可变对象(如列表、字典等),则新字典中对该值的修改也会反映在原始字典中。
(2)深复制(Deep Copy): 深复制创建了一个完全独立的字典对象,包括字典的所有键和值。修改新字典中的值不会影响原始字典。
可以使用 copy 模块中的 deepcopy() 函数进行深复制。
import copy
original_dict = {'name': 'Alice', 'age': 25}
new_dict = copy.deepcopy(original_dict)
print(new_dict)
输出:
{'name': 'Alice', 'age': 25}
在深复制中,无论原始字典中的值是可变对象还是不可变对象,新字典中的值都是完全独立的,修改新字典中的值不会影响原始字典。
通过浅复制和深复制,你可以根据需要选择适当的方式来复制字典。
4. 集合
4.1 Set集合
Python 中的集合(Set)是一种无序、可变的数据结构,它用于存储唯一的元素。集合中的元素不能重复,且没有固定的顺序。
集合的主要特点包括:
- 元素唯一性:集合中的元素是唯一的,不能重复出现。
- 无序性:集合中的元素没有固定的顺序,每次遍历的顺序可能不同。
- 可变性:集合中的元素可以随时添加、删除和修改。
Python 提供了内置的 set 类型用于创建集合对象。可以使用花括号 {} 或 set() 函数来创建一个集合。例如:
# 创建一个集合
fruits = {'apple', 'banana', 'orange'}
print(fruits)
# 创建一个空集合
empty_set = set()
print(empty_set)
集合支持一系列的操作和方法,包括:
- 添加元素:使用
add()方法向集合中添加元素。 - 移除元素:使用
remove()方法从集合中移除指定的元素。 - 集合运算:例如并集、交集、差集等。
- 成员关系测试:使用
in和not in来检查元素是否属于集合。 - 遍历集合:使用
for循环遍历集合中的元素。
4.2 集合的基本操作
下面是一些示例代码来演示集合的基本操作:
fruits = {'apple', 'banana', 'orange'}
# 添加元素
fruits.add('kiwi')
print(fruits)
# 移除元素
fruits.remove('banana')
print(fruits)
# 集合运算
fruits1 = {'apple', 'banana', 'orange'}
fruits2 = {'orange', 'kiwi', 'pineapple'}
union = fruits1 | fruits2 # 并集
intersection = fruits1 & fruits2 # 交集
difference = fruits1 - fruits2 # 差集
print(union)
print(intersection)
print(difference)
# 成员关系测试
print('banana' in fruits)
print('kiwi' not in fruits)
# 遍历集合
for fruit in fruits:
print(fruit)
输出结果:文章来源:https://www.toymoban.com/news/detail-455568.html
{'orange', 'kiwi', 'banana', 'apple'}
{'orange', 'kiwi', 'apple'}
{'kiwi', 'orange', 'pineapple', 'banana', 'apple'}
{'orange'}
{'kiwi', 'banana', 'apple'}
True
True
orange
kiwi
apple
4.3 集合的运算
# 在对集合做运算时,不会影响原来的集合,而是返回一个运算结果
# 创建两个集合
s = {1,2,3,4,5}
s2 = {3,4,5,6,7}
# & 交集运算
result = s & s2 # {3, 4, 5}
# | 并集运算
result = s | s2 # {1,2,3,4,5,6,7}
# - 差集
result = s - s2 # {1, 2}
# ^ 异或集 获取只在一个集合中出现的元素
result = s ^ s2 # {1, 2, 6, 7}
# <= 检查一个集合是否是另一个集合的子集
# 如果a集合中的元素全部都在b集合中出现,那么a集合就是b集合的子集,b集合是a集合超集
a = {1,2,3}
b = {1,2,3,4,5}
result = a <= b # True
result = {1,2,3} <= {1,2,3} # True
result = {1,2,3,4,5} <= {1,2,3} # False
# < 检查一个集合是否是另一个集合的真子集
# 如果超集b中含有子集a中所有元素,并且b中还有a中没有的元素,则b就是a的真超集,a是b的真子集
result = {1,2,3} < {1,2,3} # False
result = {1,2,3} < {1,2,3,4,5} # True
# >= 检查一个集合是否是另一个的超集
# > 检查一个集合是否是另一个的真超集
print('result =',result)- 并集(Union):返回两个集合的所有元素,去除重复的部分。
- 交集(Intersection):返回两个集合中共同存在的元素。
- 差集(Difference):返回第一个集合中存在,而第二个集合中不存在的元素。
- 对称差(Symmetric Difference):返回两个集合中不重复的元素,即属于一个集合但不属于另一个集合的元素。
通过集合的运算,我们可以方便地对集合进行合并、求交、找出差异等操作,从而更加灵活地处理数据。文章来源地址https://www.toymoban.com/news/detail-455568.html
到了这里,关于python入门(5)序列、字典、集合的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!