本篇博客主要是根据 1、聚类的基本知识点_哔哩哔哩_bilibili系列视频进行的学习记录
一、SPSS聚类分析的基本知识点
1、什么是聚类分析?
聚类分析(Cluster analysis)又叫做群集分析,通过一些属性将对象或变量 分成不同的组别,在 同一类下的对象或变量在这些属性上具有一些相似的特点。
两种聚类类型
对个案(样品、对象、被试)进行分类——Q型聚类。
对变量进行分类——R型聚类。
或者换一种说法:
样本聚类又称Q型聚类,它针对实测量进行分类,将特征相近的实测量分为一类,特征差异较大的实察量分在不同的类。
变量聚类又称R型聚类,它针对变量分类,将性质相近的变量分为一类,将性质差异较大的变量分在不同的类。

例如:

对每一行进行聚类——Q型聚类
对每一列进行聚类——R型聚类(比如车重和油箱进行聚类)
2、SPSS聚类分析的方法。
(1) 快速聚类(k-均值聚类):最简单的聚类方法,只能对 连续数据进行聚类,只能对样品进行聚类,适合 大样本聚类,不能自动确定类别数量。
(2) 系统聚类:可以对个案、变量进行聚类,可以对连续变量或分类变量进行聚类,适合样本容量较小的情况,不能自动确定类别数量。
(3) 二阶聚类:最 智能的聚类方法,可以对个案进行聚类,可以对 连续变量+分类变量进行聚类,适合 大样本聚类, 能自动确定类别数量。
二、聚类分析的SPSS实操
1.k-均值聚类。
(1)操作要点。
首先把数据标准化。(SPSS: 分析->统计描述->描述)
聚类数:根据计算结果来定。
迭代数:可以改大一些。
保存:“聚类成员和"与"聚类中心的距离”
选项:“ANOVA”和“每个个案聚类信息”
(2)结果解读:
a、读最终聚类中心能够反映分出来的这两类的特点,可以自己起名字。
b、ANOVA显示两个或者多个类别的群体在聚类的各个变量上是否有差异,有差异说明聚类相对成功。
c、个案数显示两个或者多个类别的群体各有多少个被试。最好比较均匀,不要有类别太少。
(3)三线表的制作
SPSS步骤:
1. 数据标准化:分析->统计描述->描述

2. 分析->分类 -> K-均值聚类
选变量、聚类数(多尝试几个)、迭代(次数大一些,比如99次)、保存(聚类变量、与聚类中心的距离)、选项(√ANOVA表——给出每个类别之间有没有差异,我们是希望不同类别之间是有差异的,√每个类别的聚类信息)



根据聚类中心我们看看能不能自己起名字
最终聚类中心 | ||
|
聚类 |
|
1 |
2 |
|
Zscore(Income) |
.97179 |
-.51186 |
Zscore(Children) |
-.45904 |
.24179 |
Zscore(Family_Quotient) |
1.11281 |
-.58614 |
ANOVA | ||||||
|
聚类 |
误差 |
F |
Sig. |
||
均方 |
df |
均方 |
df |
|||
Zscore(Income) |
298.452 |
1 |
.503 |
598 |
593.830 |
.000文章来源:https://www.toymoban.com/news/detail-455653.html |
Zscore(Children) |
66.595 |
1 |
.890 |
598 |
74.799 |
.000 |
Zscore(Family_Quotient) |
391.353 |
1 |
.347 |
598 |
1127.055 |
.000 |
F 检验应仅用于描述性目的,因为选中的聚类将被用来最大化不同聚类中的案例间的差别。观测到的显著性水平并未据此进行更正,因此无法将其解释为是对聚类均值相等这一假设的检验。文章来源地址https://www.toymoban.com/news/detail-455653.html | ||||||
我们可以看到显著性是有差异的,这说明聚类相对成功。
至于三线表的制作我们可以借助excel(先把SPSS的表格复制粘贴到excel,在excel中进行必要行的删减或修改,添加三条线,最后粘贴到word文档即可)
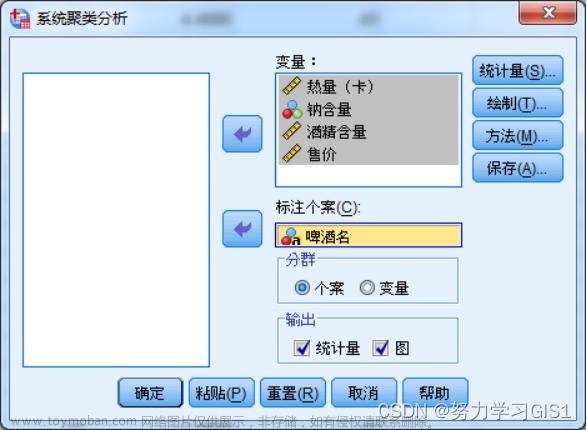
2.系统聚类
(1)操作要点。
绘制:树状图(谱系图)。
方法:“聚类方法"用"组间连接"。
“度量标准"根据数据类型选定:Q型聚类选“平方欧氏距离",R型聚类用“Pearson相关"。
“标准化"选定"Z得分"。
分群:根据聚类类型选定。
(2)结果解读:
画聚合系数随分类数变化图:以聚合系数为纵坐标,类别为横坐标,开始是N-1类。聚合系数图从哪里开始平缓就取那里的分类数。
(3)图表的制作。




我们可以看到在分成两类比较合适
3、两阶聚类
(1)操作要点。
分类变量和连续变量按要求填入。
距离测量:全连续变量选“欧氏",否则选“对数似然"聚类数目:“自动确定"
输出:“透视表”"、“创建聚类成员变量"
(2)结果解读:
(3)图表的制作。





到了这里,关于SPSS聚类分析(含k-均值聚类,系统聚类和二阶聚类)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!





![[足式机器人]Part2 Dr. CAN学习笔记-动态系统建模与分析 Ch02-7二阶系统](https://imgs.yssmx.com/Uploads/2024/01/811525-1.png)



