2023年认证杯SPSSPRO杯数学建模
B题 考订文本
原题再现:
古代文本在传抄过程中,往往会出现种种错误,以至于一部书可能流传下来多种版本。在文献学中,错误往往被总结成“讹”、“脱”、“衍”、“倒”等形式,也可能同时出现多种错误。错误可以在传抄过程中不断累加。
1.“讹”是指对原始文本的篡改。包括无意中写错单个文字,也包括根据传抄者自己的理解篡改完整的词汇,句子乃至整段内容。例如《红楼梦》中著名菜肴“茄鲞”的做法,就有不同版本的古籍流传至今,而且内容相去甚远,其中势必存在被传抄者篡改的部分;
2.“脱”是指误删文字。包括遗漏单个文字或者成段内容。例如《荀子·劝学》一文中有“蓬生麻中,不扶而直”一句,在古籍的传世版本中并无后文。后经清代王念孙考证,后面应有“白沙在涅,与之俱黑”一句;
3.“衍”是指误增文字。包括误增单字或词,误增整句的情况也有。例如三国人物“士仁”在《三国演义》通行本中写作“傅士仁”,有人猜测这个“傅”姓本是衍字而来。增整段的情况较少,往往是传抄者将其他文献或自己原创的批注加进文本,后世无法辨识所致;
4.“倒”一般是指交换原有文字的位置。单个文字位置对换往往是由于传抄失误,大段乃至整篇文字的对换往往是由于装订失误。例如明代于谦诗作《石灰吟》中有“粉骨碎身浑不怕”一句,在一些传抄版本中被误作“粉身碎骨浑不怕”。
不仅是古代的传抄者会出错,即使是现代的通信或存储设备,当一条信息被多次转发或转录以后,也无法避免随机发生的错误。在此,我们将此问题改造成更加理想化的形式:假设原始文本的长度足够大,而且在传抄过程中,传抄者并不和其他版本进行互相校核。这样,在足够长的流传或转发过程中,不同的错误叠加,就可能会产生大量不同的版本。请你建立合理的数学模型,研究如下问题。
第一阶段问题:
1. 请你设计合理的方案,衡量两个不同版本的文本之间的差异大小。
2. 如果一个版本是从另一个版本经过多次传抄而来,我们希望估计两个文本之间经历的传抄次数。请分析并解决这个问题。在建模时请注意:为了进行有效的估计,我们还需要知道哪些必需的信息?
3. 在解决前面提出的问题时,有一些方案虽然在概念上很合理,但会遇到实际计算上的困难。现请你针对前两问,分别设计一个有效而快速的算法。请描述算法的原理,估计其速度,并举算例。
整体求解过程概述(摘要)
中国古籍浩如烟海,古文献流布的一种重要形式即为手抄,但经过反复传抄,不免有文字上的纰缪、词语的脱落、句子的增衍和缺漏等错误。
本文从古籍考订的角度出发展开研究,针对文献传抄中可能出现的“讹”“脱”“衍”“倒”等错误,建立多种不同维度的模型来评估版本之间的差异程度,并在此基础上对版本间的传抄次数进行了估算。
针对问题一,本文将传抄版本间的改动分为字符级别的小范围改动和段落篇章级别的大范围改动,两种情况都会给文献的传承带来负面影响,但带来的影响存在于不同方面。因此,本文分别建立了基于最长公共子序列(Longest Common Subsequence, LCS)的文本匹配度模型和基于编辑路径的版本差异量化模型,对传抄中“讹”“脱”“衍”等错误产生的过程进行了模拟,用于在不同粒度上量化比较两个版本的差异。
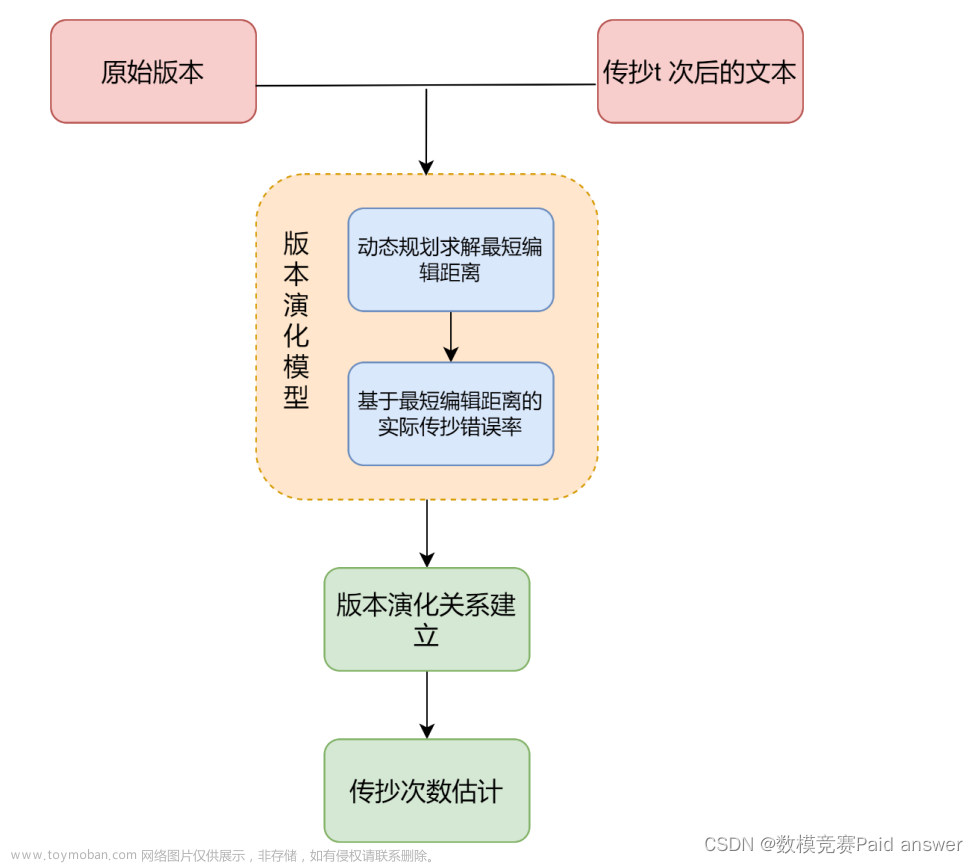
针对问题二,本文在最短编辑距离(Minimum Edit Distance, MED)的基础上提出了一种传抄版本演化模型,在平均传抄错误率γ已知的情况下,可以递推预估文献在数次传抄后产生的错误率期望值,由此计算得出两个版本之间的预估传抄次数。
针对问题三,本文选用 4 个版本的《庄子》内篇作为本文的研究数据,4 个版本分别为不同年代编撰的版本。在问题一和问题二模型的基础上进行计算,得出了 4 个版本两两之间的差异指标,并得到了传抄错误产生的位置、类型和内容;在设定的专家权重上计算版本差异度,发现版本 3 和版本 2 差异最小;同时,在假设γ=3%的情况下预估得到版本 1 和版本 3 之间的传抄次数约为 14 次。
同时,为提高算法执行效率和对更大数据量的处理能力,本文进行了算法优化,结合正则表达式对文本进行了过滤和解析,将各版本按篇章进行对齐匹配,拆分为多个部分分别进行模型的求解运算,算法时间复杂度降低 80%以上,在本文算例中完成全部处理和计算的时间仅为数秒。
问题分析:
基于古文献学原理,古代文本在传抄过程中,不免出现“讹”“脱”“衍”“倒”等错误,并且错误在传抄过程中不断累加。本文选取的四个版本的《庄子》中也存在上述错误,我们认为可以通过对比任意两个版本之间的改动程度来判断差异大小。
传抄版本的改动主要分为两种情况:第一是字符级别的小范围改动,例如因疏忽、介质损坏、妄校等原因造成的错字、多字、漏字或顺序颠倒等情况;第二是段落甚至篇章级别的改动,例如遗漏大段文字、误抄其他文献或加入注释未加区分导致无法辨别等。两种情况都会给文献的传承带来负面影响,但带来的影响存在于不同方面。字符级别的错漏或衍文可能改变文献原貌、降低文献的质量和可读性,给后人阅读和理解造成困扰;大段缺漏文字可能造成文献内容的失传、大段增加内容可能导致文献原义改变。衡量两个版本之间的差异时,两种情况应分别考虑,并结合需求确定侧重的方面。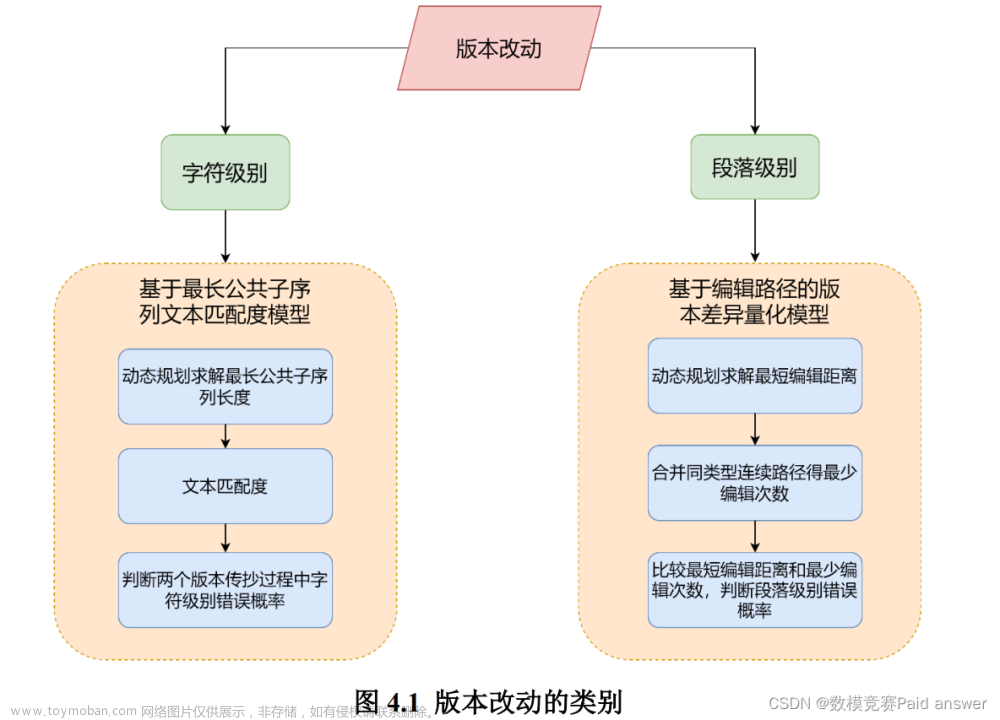
本文认为传抄次数越多,文本错误越多,可以通过分析文本的错误率来估计两个文本之间历经的传抄次数。我们将建立传抄版本演化模型,在问题一的基础上,利用最短编辑距离的衍生指标和必需已知信息——平均传抄错误率,构建传抄次数表达式,以此估计两个版本的文本之间历经的传抄次数。具体流程如下图所示。
模型假设:
为简化模型,我们做了以下合理性假设:
(1) 本文所采用的文本与该版本的原本一致,电子化过程中不存在录入错误。
(2) 本文只考虑不同版本文本文字之间的差异,兼通、避讳等主观因素带来的差异一并记为版本之间的改动。
(3) 本文只考虑正文部分的差异,对于目录、注释等部分差异不予衡量。
(4) 传抄过程中,传抄者并不和其他版本进行互相校核,随着传抄次数增多,错误增多,差异增大。文章来源:https://www.toymoban.com/news/detail-455732.html
完整论文缩略图

 文章来源地址https://www.toymoban.com/news/detail-455732.html
文章来源地址https://www.toymoban.com/news/detail-455732.html
全部论文请见下方“ 只会建模 QQ名片” 点击QQ名片即可
部分程序代码:(代码和文档not free)
1. import pandas as pd
2. import pylcs
3. import re
4. from Levenshtein import distance, editops
5. from collections import Counter
6.
7. base_dir = r'.'
8. with open(base_dir + '\\藏外\\庄子.txt', 'r', encoding='utf-8') as f:
9. text1 = f.read().replace('\u3000', '')
10. text1 = [i for i in text1.split('\n') if i != '']
11. with open(base_dir + '\\正统道藏洞神部 玉诀类\\庄子内篇订正.txt', 'r', encoding='utf8') as f:
12. text2 = f.read().replace('\u3000', '')
13. text2 = re.sub('#\d+', '', re.sub('\n?(右第[一二三四五六七八九十]+
章)\n?', '\n\g<1>\n', text2))
14. text2 = [i for i in text2.split('\n') if i != '']
15. with open(base_dir + '\\正统道藏洞神部 玉诀类\\南华真经注疏.txt', 'r', encoding='utf8') as f:
16. text3 = re.sub('#\d+', '', f.read().replace('\u3000', ''))
17. text3 = [i for i in text3.split('\n') if i != '']
18. with open(base_dir + '\\藏外 钦定四库全书 宋 林希逸 撰.txt', 'r', encoding='utf8') as f:
19. text4 = f.read().replace('\u3000', '').replace('\uef33', '')
20. text4 = [i for i in text4.split('\n') if i != '']
21. len(text1), len(text2), len(text3), len(text4)
22.
23. # 版本 1 解析
24. titles1 = [(i,text1[i]) for i in range(len(text1)) if len(text1[i])<20]
25. print(titles1)
26.
27. title = []
28. for i in titles1:
29. title.extend(re.findall('^卷[一二三四五六七八九十]+[上中下]?第[一二三四五六七八九
十]+(.*?)$', i[1]))
30. print(title)
31.
32. titles1.append((len(text1), 'end'))
33. pos = [(titles1[i][0], titles1[i+1][0]) for i in range(len(titles1)) if re.findall('^卷
[一二三四五六七八九十]+[上中下]?第[一二三四五六七八九十]+(.*?)$', titles1[i][1])]
34. print(pos)
35.
36. text1 = [text1[i[0]:i[1]] for i in pos][:7]
37.
38. with open(base_dir + '\\text1.txt', 'w', encoding='utf-8') as f:
39. f.write('\n\n'.join(['\n'.join(i) for i in text1]))
40.
41. # 版本 2 解析
42. titles2 = [(i,text2[i]) for i in range(len(text2)) if len(text2[i])<20]
43. print(titles2)
44.
45. end_pos = [i for i in titles2 if i[1][0] != '右']
46. pos = [(end_pos[i][0], end_pos[i+1][0]) for i in range(len(end_pos)) if end_pos[i][1] i
n title]
47. print(pos)
48.
49. text2 = [[t for t in text2[i[0]:i[1]] if t[:2] != '右第'] for i in pos]
50.
51. with open(base_dir + '\\text2.txt', 'w', encoding='utf-8') as f:
52. f.write('\n\n'.join(['\n'.join(i) for i in text2]))
53.
54. # 版本 3 解析
55. titles3 = [(i,text3[i]) for i in range(len(text3)) if len(text3[i])<20 and re.findall('
南华真经注疏卷之|^[内外杂]篇(.*?)第' ,text3[i])]
56. print(titles3)
57.
58. level1_pos = [i for i in titles3 if i[1][:8] == '南华真经注疏卷之
'] + [(len(text3), 'end')]
59. level1_pos = [(level1_pos[i][0], level1_pos[i+1][0]) for i in range(len(level1_pos)-
1) if re.findall('^南华真经注疏卷之[一二三四五六七八九十]+$', level1_pos[i][1])]
60. print(level1_pos)
61.
62. titles3_idx = [i[0] for i in titles3]
63. level2_pos = []
64. for i in level1_pos:
65. for j in range(i[0]+1, i[1]):
66. if re.findall('^[内外杂]篇(.*?)第', text3[j]):
67. level2_pos.append((j, titles3_idx[titles3_idx.index(j) + 1],text3[j]))
68. print(level2_pos, len(level2_pos))
69.
70. text3 = [text3[i[0]:i[1]] for i in level2_pos[:7]]
71. text3 = [[i for i in para if not re.findall('^[〔\[[(]?[注疏][〕
\]])]?', i)] for para in text3]
72.
73. with open(base_dir + '\\text3.txt', 'w', encoding='utf-8') as f:
74. f.write('\n\n'.join(['\n'.join(i) for i in text3]))
75.
76. # 版本 4 解析
77. titles4 = [(i,text4[i]) for i in range(len(text4)) if len(text4[i])<6]
78. print(titles4)
79.
80. titles4.append((len(text4), 'end'))
81. pos = [(titles4[i][0], titles4[i+1][0]) for i in range(len(titles4)-1)]
82. print(pos)
83.
84. text4 = [text4[i[0]:i[1]] for i in pos]
85.
86. with open(base_dir + '\\text4.txt', 'w', encoding='utf-8') as f:
87. f.write('\n\n'.join(['\n'.join(i) for i in text4]))
88.
89. # 去标点
90. text1_nopunc = [[re.sub('[,。?!:;“”‘’《》【】、「」『』()
\(\)—.︰:;,\?! ]' , '', i) for i in t] for t in text1]
91. text2_nopunc = [[re.sub('[,。?!:;“”‘’《》【】、「」『』()
\(\)—.︰:;,\?! ]' , '', i) for i in t] for t in text2]
92. text3_nopunc = [[re.sub('[,。?!:;“”‘’《》【】、「」『』()
\(\)—.︰:;,\?! ]' , '', i) for i in t] for t in text3]
93. text4_nopunc = [[re.sub('[,。?!:;“”‘’《》【】、「」『』()
\(\)—.︰:;,\?! ]' , '', i) for i in t] for t in text4]
94.
95. # 版本对比
96. def get_edit_steps(str1, str2):
97. res = []
98. steps = []
99. temp = [' '] # [i[0],str1[i[1]],str2[i[2]],i[1],i[2]]
100. for i in editops(str1, str2):
101. if i[0] == 'replace':
102. if temp[0] == i[0] and i[1] == temp[-2] + 1 and i[2] == temp[-1] + 1:
103. temp[1] += str1[i[1]]
104. temp[2] += str2[i[2]]
105. temp[-2] = i[1]
106. temp[-1] = i[2]
107. else:
108. if temp[0] != ' ':
109. steps.append(temp)
110. temp = [i[0], str1[i[1]], str2[i[2]], i[1], i[2]]
111. elif i[0] == 'insert':
112. if temp[0] == i[0] and i[1] == temp[-2] and i[2] == temp[-1] + 1:
113. temp[2] += str2[i[2]]
114. temp[-1] = i[2]
115. else:
116. if temp[0] != ' ':
117. steps.append(temp)
118. if i[1]==len(str1):
119. temp = [i[0], 'eof', str2[i[2]], i[1], i[2]]
120. else:
121. temp = [i[0], str1[i[1]], str2[i[2]], i[1], i[2]]
122. else:
123. if temp[0] == i[0] and i[1] == temp[-2] + 1 and i[2] == temp[-1]:
124. temp[1] += str1[i[1]]
125. temp[-2] = i[1]
126. else:
127. if temp[0] != ' ':
128. steps.append(temp)
129. if i[2]==len(str2):
130. temp = [i[0], str1[i[1]], 'eof', i[1], i[2]]
131. else:
132. temp = [i[0], str1[i[1]], str2[i[2]], i[1], i[2]]
133. if temp:
134. steps.append(temp)
135. del temp
136. count_dict = {'replace':[0,0,0,0,0], 'insert':[0,0,0,0,0], 'delete':[0,0,0,0,0]}
137. count = 1
138. for i in steps:
139. if i[0] == 'replace':
140. res.append('第%s 处(讹)“%s”修改为
“%s”' % (str(count) if len(i[1])==1 else str(count)+'-'+str(count+len(i[1])-
1), i[1], i[2]))
141. count += len(i[1])
142. count_dict['replace'][0] += 1
143. count_dict['replace'][1] += len(i[1])
144. if len(i[1])<=3:
145. count_dict['replace'][2] += 1
146. elif 4<=len(i[1])<=20:
147. count_dict['replace'][3] += 1
148. else:
149. count_dict['replace'][4] += 1
150. elif i[0] == 'insert':
151. ii = i[2] if len(i[2]) < 30 else i[2][:10] + '…(省略%d 个
字)…' % (len(i[2])-20) + i[2][-10:]
152. if i[1] == 'eof':
153. res.append('第%s 处(衍)最后增加
“%s”' % (str(count) if len(i[2])==1 else str(count)+'-'+str(count+len(i[2])-1), ii))
154. else:
155. res.append('第%s 处(衍)“%s”前增加
“%s”' % (str(count) if len(i[2])==1 else str(count)+'-'+str(count+len(i[2])-
1), i[1], ii))
156. count += len(i[2])
157. count_dict['insert'][0] += 1
158. count_dict['insert'][1] += len(i[2])
159. if len(i[2])<=3:
160. count_dict['insert'][2] += 1
161. elif 4<=len(i[2])<=20:
162. count_dict['insert'][3] += 1
163. else:
164. count_dict['insert'][4] += 1
165. else:
166. ii = i[1] if len(i[1]) < 30 else i[1][:10] + '…(省略%d 个
字)…' % (len(i[1])-20) + i[1][-10:]
167. if i[2] == 'eof':
168. res.append('第%s 处(脱)最后删去
“%s”' % (str(count) if len(i[1])==1 else str(count)+'-'+str(count+len(i[1])-1), ii))
169. else:
170. res.append('第%s 处(脱)“%s”前删去
“%s”' % (str(count) if len(i[1])==1 else str(count)+'-'+str(count+len(i[1])-
1), i[2], ii))
171. count += len(i[1])
172. count_dict['delete'][0] += 1
173. count_dict['delete'][1] += len(i[1])
174. if len(i[1])<=3:
175. count_dict['delete'][2] += 1
176. elif 4<=len(i[1])<=20:
177. count_dict['delete'][3] += 1
178. else:
179. count_dict['delete'][4] += 1
180. return res, count_dict, steps
181.
182. columns = ['篇章名'] + ['版本%d 长度
' % i for i in range(1,5)] + [j+'_'+i for i in ['13', '14', '12', '34', '32', '42'] for
j in ['LCS MD', 'MED MNE']] + [j+'_'+i for i in ['13', '14', '12', '34', '32', '42'] f
or j in ['改动步骤', '改动类型次数', '多次的']]
183. dfs = [] # 1342
184. for i in range(7):
185. str1 = ''.join(text1_nopunc[i][1:])
186. str2 = ''.join(text2_nopunc[i][1:])
187. str3 = ''.join(text3_nopunc[i][1:])
188. str4 = ''.join(text4_nopunc[i][1:])
189. temp = [title[i], len(str1), len(str2), len(str3), len(str4)]
190. final = []
191. for g in [(str1, str3), (str1, str4), (str1, str2), (str3, str4), (str3, str2),
(str4, str2)]:
192. lcs = pylcs.lcs(*g)
193. sim_lcs = lcs/min(len(g[0]), len(g[1]))
194. edit_dis = distance(*g)
195. print_res, count_dict, raw_res = get_edit_steps(*g)
196. print_res = '\n'.join(print_res)
197. multi = [item for item in sorted(dict(Counter([(i[0], i[1], i[2]) for i in r
aw_res])).items(), key=lambda e: e[1], reverse=True) if item[1]>1]
198. multi = '\n'.join([str(k)+' '+str(v)+'次' for k,v in multi])
199. edit_dis = '%d %d' % (edit_dis, sum([v[0] for v in count_dict.values()]))
200. temp.extend(['%d %.4f' % (lcs, sim_lcs), edit_dis])
201. final.extend([print_res, count_dict, multi])
202. dfs.append(temp+final)
203. df = pd.DataFrame(dfs, columns=columns)
204. df.to_csv(base_dir + '\\版本对比.csv', index=False, encoding='utf-8-sig')
205.
206. # 传抄错误模拟
207. res = ''
208. for version, i in list(zip(['13', '14', '12', '34', '32', '42'], [list(zip(title[:7]
,df.loc[:, '改动步骤_'+i].tolist())) for i in ['13', '14', '12', '34', '32', '42']])):
209. res += '版本' + version[0] + '、' + version[1] +'传抄错误模拟\n'
210. for j in i:
211. res += j[0]+'\n'+j[1]+'\n'
212. res += '\n'
213.
214. with open(base_dir + '\\传抄错误步骤.txt', 'w', encoding='utf-8') as f:
215. f.write(res)
216.
217. # 词云图
218. from pyecharts.charts import Pie, WordCloud
219. from pyecharts import options as opts
220. from collections import Counter
221. w = (
222. WordCloud()
223. .add("", sorted(Counter([i.split(')')[1] for i in df.loc[0, '改动步骤
_13'].split('\n')]).items(), key=lambda e: e[1], reverse=True)[:30])
224. .set_global_opts(title_opts=opts.TitleOpts(title='版本 1 到版本 3 的改动步骤'))
225. )
226. w.render_notebook()
227.
228. # 分类量化
229. ddf = df[['篇章名'] + ['改动类型次数
_'+i for i in ['13', '14', '12', '34', '32', '42']]]
230. df_new = []
231. for i in ['13', '14', '12', '34', '32', '42']:
232. line = []
233. for ii in range(2,5):
234. for k in ['replace', 'delete', 'insert']:
235. line.append(sum([j[k][ii] for j in ddf['改动类型次数_' + i].tolist()]))
236. df_new.append(line)
237. df_new = pd.DataFrame(df_new, columns = [i + j + '文' for i in ['轻度', '中度', '严重
'] for j in ['讹','脱','衍']])
238. df_new.index=['版本' + i[0] + '、
' + i[1] for i in ['13', '14', '12', '34', '32', '42']]
239. df_new.to_csv(base_dir + '\\指标计算.csv', encoding='utf-8-sig')
240. df_new['差异程度'] = df_new.apply(lambda x: x['轻度讹文'] + x['轻度脱文'] + x['轻度衍文
'] + 3*(x['中度讹文'] + x['中度脱文'] + x['中度衍文'])+ 10*(x['严重讹文'] + x['严重脱文
'] + x['严重衍文']), axis=1)
241. df_new.to_csv(base_dir + '\\差异程度.csv', encoding='utf-8-sig')
242.
243. # 传抄次数估算
244.
245. import math
246. errorrate=0.34112426
247. r=0.03
248. t=math.log(1-errorrate, 1-r)
249. print(t)
全部论文请见下方“ 只会建模 QQ名片” 点击QQ名片即可
到了这里,关于2023年认证杯SPSSPRO杯数学建模B题(第一阶段)考订文本全过程文档及程序的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!