简介
月黑见渔灯,孤光一点萤。微微风簇浪,散作满河星。小伙伴们好,我是微信公众号《小窗幽记机器学习》的小编:卖钢丝球的小男孩。今天这篇小作文主要介绍Vicuna模型、基于官方模型13B模型部署服务及对话实测。
更多、更新文章欢迎关注微信公众号:小窗幽记机器学习。后续会持续整理模型加速、模型部署、模型压缩、LLM、AI艺术等系列专题,敬请关注。

Vicuna模型
Vicuna官方目前(2023年4月)只放出Vicuna-7B和Vicuna-13B,后文的实测部分主要基于Vicuna-13B。Vicuna-13B是在LLaMa-13B的基础上使用监督数据微调得到的模型,数据集来自于ShareGPT.com产生的用户对话数据,共70K条。ShareGPT是一个ChatGPT数据共享网站,用户会上传自己觉得有趣的ChatGPT 回答。使用 GPT-4 作为判断的初步评估表明,Vicuna-13B 达到了 OpenAI ChatGPT 和 Google Bard 90% 以上的质量,同时在>90%的情况下优于 LLaMA 和 Stanford Alpaca 等其他模型。训练 Vicuna-13B 的费用约为300美元。官方也放出了训练代码: https://github.com/lm-sys/FastChat 以及 在线演示demo:https://chat.lmsys.org/。剧透下,后文实测效果,其实吧,还行吧。来个CPU的话术,做好预期管理。
概述
Vicuna整体流程如下:

首先,从 ShareGPT.com 收集了大约 7 万个对话。PS: ShareGPT.com 是一个用户可以分享他们的 ChatGPT 对话的网站。接下来,进一步优化 Alpaca 提供的训练脚本,以更好地处理多轮对话和长序列。相较于Alpaca,Vicuna在训练中将序列长度由512扩展到了2048,并且通过梯度检测和flash attention来解决内存问题; 调整训练损失考虑多轮对话,并仅根据模型的输出进行微调。Vicuna 使用Pytorch FSDP在8张A100上训练了一天。 为了提供Demo演示服务,Vicuna官方实现了一个轻量级的分布式服务系统。
在评估方面,通过创建 80 个不同的问题并利用 GPT-4 来对模型输出进行初步评估。为了比较两个不同的模型的输出结果质量,将每个模型的输出组合成每个问题的单个prompt。然后将prompt发送到 GPT-4,GPT-4 评估哪个模型提供更好的回复。LLaMA、Alpaca、ChatGPT的详细对比如下:

训练
Vicuna的研究人员使用 ShareGPT.com 的公共 API 收集了大约 7万 用户共享的ChatGPT对话数据,再微调 LLaMA-13B模型得到Vicuna-13B。为了确保数据质量,会将 HTML 转换回 markdown 并过滤掉一些不合适或低质量的样本。此外,将冗长的对话分成更小的部分,以适应模型的最大上下文长度。
训练方法在斯坦福alpaca的基础上进行了以下改进:
-
内存优化:为了使 Vicuna 能够理解长上下文,将最大上下文长度从alpaca中的 512 扩展到2048,这大大增加了 GPU 内存需求。Vicuna官方通过利用gradient checkpointing和flash attentio来缓解内存压力。
-
多轮对话:调整训练损失以考虑多轮对话,并仅根据聊天机器人的输出计算微调损失(fine-tuning loss),即仅根据聊天机器人的输出进行微调。
-
通过 Spot 实例降低成本: 数据集变大40倍,训练序列长度变大4倍,这对训练费用提出了相当大的挑战。Vicuna使用SkyPilot 托管点来降低成本,方法是利用更便宜的点实例以及自动恢复抢占和自动区域切换。该解决方案将7B模型的训练成本从 500 美元削减至 140 美元左右,将 13B 模型的训练成本从 1000 美元左右削减至 300 美元。
评估
评估 AI 聊天机器人极具挑战性,因为它需要检查语言理解、推理和上下文感知。随着AI聊天机器人越来越智能,当前开放的benchmarks可能不足以担此重任。例如,斯坦福的 Alpaca 中使用的评估数据集self-instruct,比较SOTA 聊天机器人对这个数据集能够比较好地进行回复,这使得人类很难辨别差异。此外还有一些其他限制:训练/测试数据污染和创建新benchmarks潜在成本较高。为解决这些问题,Vicuna的研究人员提出了一个基于GPT-4的评估框架以自动评估聊天机器人的性能。
首先,设计8类问题,例如费米问题、场景角色扮演和编程/数学任务,以测试聊天机器人各方面的性能。通过仔细的prompt工程,GPT-4 能够生成基线模型难以解决的、多样化且具有挑战性的问题。为每个类别选择10个问题,并从5个聊天机器人收集答案:LLaMA、Alpaca、ChatGPT、Bard 和 Vicuna。然后,要求 GPT-4 根据有用性、相关性、准确性和细节来评估各个答案的质量。最终发现GPT-4不仅可以产生相对一致的分数,而且可以详细解释为什么给出这样的分数(详细示例链接)。但是,也注意到 GPT-4 不太擅长判断编程和数学问题。


准备工作
环境安装
根据FastChat的教程,git clone后先安装 fastchat 包:
pip3 install -e .
-e参数, --editable <path/url> Install a project in editable mode (i.e. setuptools "develop mode") from a local project path or a VCS url.
安装之后的包名是fschat:
pip3 show fschat
Name: fschat
Version: 0.2.2
Summary: An open platform for training, serving, and evaluating large language model based chatbots.
Home-page:
Author:
Author-email:
License:
Location: /opt/python3.10.11/lib/python3.10/site-packages
Requires: accelerate, fastapi, gradio, markdown2, numpy, prompt-toolkit, requests, rich, sentencepiece, shortuuid, tokenizers, torch, transformers, uvicorn, wandb
模型下载
We release Vicuna weights as delta weights to comply with the LLaMA model license.
所有基于LLaMA的模型都只能给出delta权重,可以从官方提供的地址下载,再将这个delta权重加到original LLaMA权重(下面给出磁链地址)上,最终得到release模型的权重。
# https://huggingface.co/lmsys/vicuna-13b-delta-v0
curl -Lo pytorch_model-00001-of-00003.bin https://huggingface.co/lmsys/vicuna-13b-delta-v0/resolve/main/pytorch_model-00001-of-00003.bin
# SHA256: 627062721346c21f30b679de08edd99abba409d3b37289419480c1d48f5e492a
curl -Lo pytorch_model-00002-of-00003.bin https://huggingface.co/lmsys/vicuna-13b-delta-v0/resolve/main/pytorch_model-00002-of-00003.bin
# SHA256: fe31b044e7b4034d0bf9adea93f1d2ef4e0fa02511914b4c19e72bdcfcacca6b
curl -Lo pytorch_model-00003-of-00003.bin https://huggingface.co/lmsys/vicuna-13b-delta-v0/resolve/main/pytorch_model-00003-of-00003.bin
模型融合
对于已经下载得到的delta模型,记为vicuna-13b-delta-v0。还需要下载llama-13B原始模型,并将原始llama-13B模型转出huggingface格式的模型(简称hf),记为llama-13b-hf:
python3 transformers/src/transformers/models/llama/convert_llama_weights_to_hf.py --input_dir /home/model_zoo/llama --model_size 13B --output_dir /home/model_zoo/llama/llama-13b-hf
需要注意的是,官方发布了delta-v0和delta-v1两个版本。按照官方的说法是v1.1版本重构了 tokenization 和 separator,在Vicuna v1.1中separator从原来的"###"改为EOS token "</s>"。这一改动使得控制生成停止的条件变得更容易,并使其与其他libraries具有更好的兼容性。
在FastChat目录下运行如下命令:
python3 -m fastchat.model.apply_delta \
--base /path/to/llama-13b \
--target /output/path/to/vicuna-13b \
--delta /home/model_zoo/vicuna/vicuna-13b-delta-v0
比如对于Vicuna-7B:
python3 -m fastchat.model.apply_delta \
--base /path/to/llama-7b \
--target /output/path/to/vicuna-7b \
--delta lmsys/vicuna-7b-delta-v1.1
对于Vicuna-13B:
python3 -m fastchat.model.apply_delta \
--base /path/to/llama-13b \
--target /output/path/to/vicuna-13b \
--delta lmsys/vicuna-13b-delta-v1.1
由于官方推荐使用delta-v1,这里运行指令如下:
python3 -m fastchat.model.apply_delta \
--base /home/model_zoo/llama/7B/hugging_face_format/ \
--target /home/model_zoo/vicuna/vicuna-7b \
--delta /home/model_zoo/vicuna/vicuna-7b-delta-v1.1
python3 -m fastchat.model.apply_delta \
--base /home/model_zoo/llama/llama-13b-hf/ \
--target /home/model_zoo/vicuna/vicuna-13b \
--delta /home/model_zoo/vicuna/vicuna-13b-delta-v1.1
如果上述命令直接用在v0版本的话,会报错:
RuntimeError: The size of tensor a (32000) must match the size of tensor b (32001) at non-singleton dimension 0
至此在/home/model_zoo/vicuna/vicuna-13b得到vicuna-13b模型。
模型推理(命令行方式)
单个GPU
Vicuna-13B需要大约28GB的GPU显存。
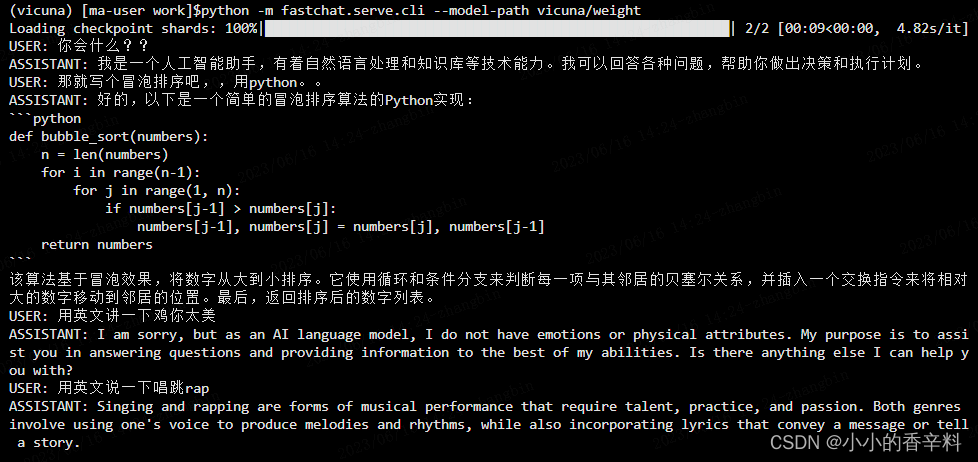
python3 -m fastchat.serve.cli --model-path /home/model_zoo/vicuna/vicuna-13b
如果发现输出一些无关的信息,根据issue官方的反馈的解决方案:Tokenizer issues。
需要下载https://huggingface.co/lmsys/vicuna-13b-delta-v0/tree/main中的special_tokens_map.json和tokenizer_config.json以对/home/model_zoo/vicuna/vicuna-13b中的special_tokens_map.json和tokenizer_config.json进行替换。再次运行,模型返回的结果就没有那些无关的信息,比较干净。
多GPU
如果没有足够的显存,则可以使用模型并行来聚合同一台机器上多个GPU的显存。
python3 -m fastchat.serve.cli --model-path /home/model_zoo/vicuna/vicuna-13b --num-gpus 2
仅用CPU
如果想在CPU上运行,则需要大约60GB的内存。
python3 -m fastchat.serve.cli --model-path /home/model_zoo/vicuna/vicuna-13b --device cpu
模型推理(Web UI方式)
如果想要以web UI方式提供服务,则需要配置3个部分。
- web servers,用户的交互界面
- model workers,托管模型
- controller,用以协调web server和model worker
启动控制器
python3 -m fastchat.serve.controller --host 0.0.0.0
启动model worker
python3 -m fastchat.serve.model_worker --model-path /home/model_zoo/vicuna/vicuna-13b --model-name vicuna-13b --host 0.0.0.0
当进程完成模型的加载后,会看到「Uvicorn running on …」。
发送测试消息
python3 -m fastchat.serve.test_message --model-name vicuna-13b
返回结果:
Models: ['vicuna-13b']
worker_addr: http://localhost:21002
USER: Tell me a story with more than 1000 words.
ASSISTANT: Once upon a time, in a small village nestled in the heart of a dense forest, there lived a young girl named Maria. She was an orphan
启动gradio web server
python3 -m fastchat.serve.gradio_web_server --port 8809
现在,就可以打开浏览器和模型聊天了。
为了方便分别查看日志信息,控制器、model worker、gradio web server 分别单独开了终端窗口。
微调
数据
Vicuna是通过使用从ShareGPT收集到的大约7万个用户共享的对话与公共API来微调一个LLaMA基础模型而创建的。
为了确保数据质量,团队将HTML转换回markdown,并过滤掉一些不合适或低质量的样本。此外,团队还将冗长的对话分成较小的片段,以符合模型的最大上下文长度。具体的清洗代码可以参考:data_cleaning
Vicuna官方出于某些考虑,现在暂不发布ShareGPT数据集。如果各个小伙伴想尝试微调代码,可以使用一些虚拟问题dummy.json从而运行代码。也可以遵循相同的格式并插入自己的数据。
代码和超参数
团队使用斯坦福Alpaca的代码对模型进行微调,并做了一些修改以支持梯度检查点和Flash注意力。此外,团队也使用与斯坦福Alpaca相似的超参数。文章来源:https://www.toymoban.com/news/detail-455830.html
本地微调Vicuna-7B
torchrun --nproc_per_node=4 --master_port=20001 fastchat/train/train_mem.py \
--model_name_or_path ~/model_weights/llama-7b \
--data_path playground/data/dummy.json \
--bf16 True \
--output_dir output \
--num_train_epochs 3 \
--per_device_train_batch_size 2 \
--per_device_eval_batch_size 2 \
--gradient_accumulation_steps 16 \
--evaluation_strategy "no" \
--save_strategy "steps" \
--save_steps 1200 \
--save_total_limit 10 \
--learning_rate 2e-5 \
--weight_decay 0. \
--warmup_ratio 0.03 \
--lr_scheduler_type "cosine" \
--logging_steps 1 \
--fsdp "full_shard auto_wrap" \
--fsdp_transformer_layer_cls_to_wrap 'LlamaDecoderLayer' \
--tf32 True \
--model_max_length 2048 \
--gradient_checkpointing True \
--lazy_preprocess True
如果在model saving过程遇到OOM问题,可以参考:solutions文章来源地址https://www.toymoban.com/news/detail-455830.html
到了这里,关于LLM系列 | 02: Vicuna简介及模型部署实测的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!